Beginner Recommender Systems: Episode 6
1How to deploy our model behind an endpoint
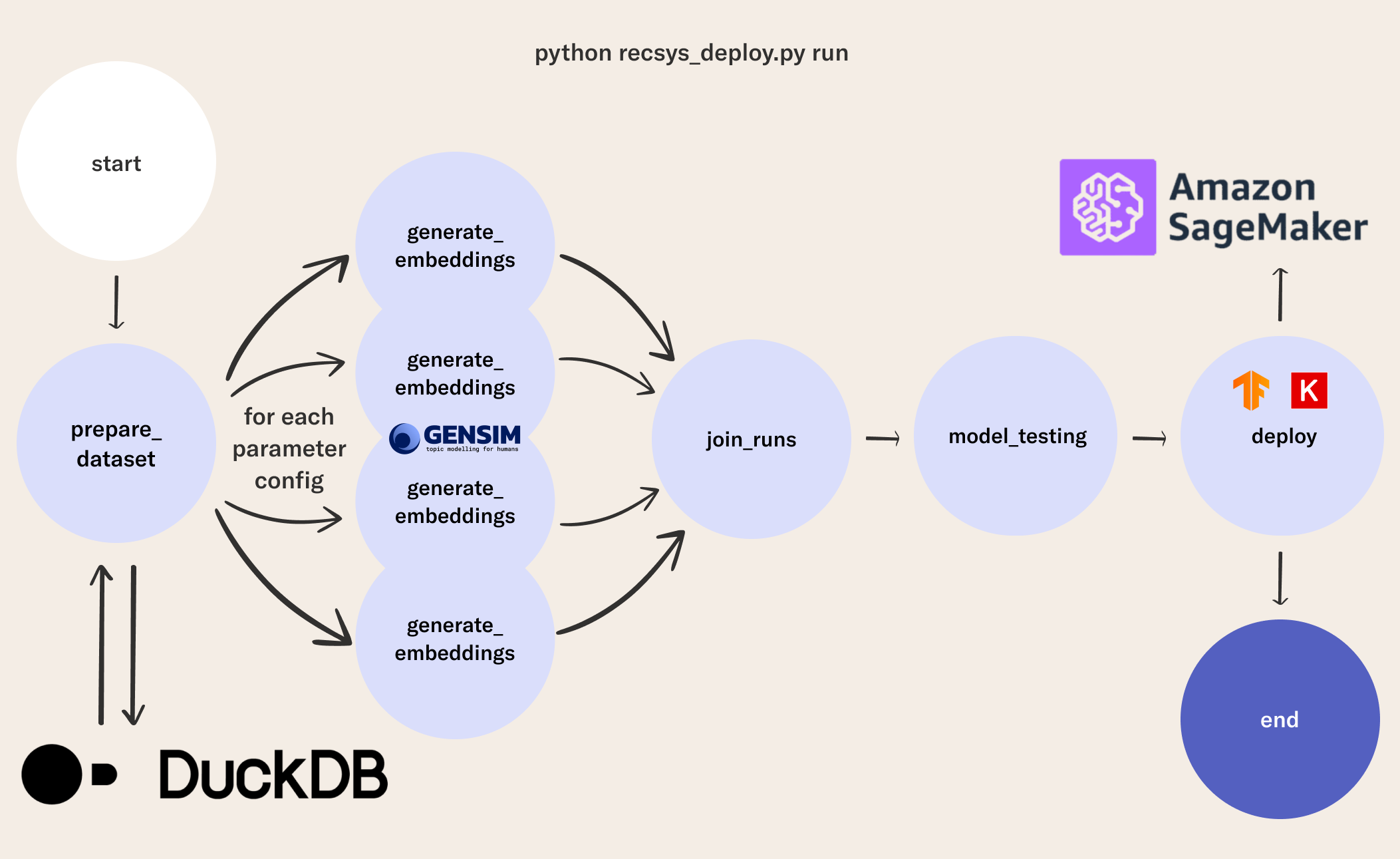
The final episode of this tutorial extends our flow once more into a full-fledged, end-to-end workflow. We introduce a few new parameters to govern SageMaker, the AWS service for hosted ML inference. You can follow along with in this flow.
The idea is pretty simple: since now we have a (versioned) artifact that is our tested model, how do we deploy it in real life so that users can get recommendations on what songs should be next in their digital radio?
2Using SageMaker and Metaflow
There are many possible solutions for deploying a KNN model. We pick Sagemaker endpoints here for a few reasons:
- As an AWS resource, you can spin up and delete the endpoint from Python, directly in your flow - no other configuration is needed!
- If you're using Metaflow with AWS as a data store (recommended in general, and required by the code below), SageMaker deployments are an elegant way to leverage Metaflow artifact storage: in fact, just point SageMaker to the model on s3!
- SageMaker is easier to use with one of the pre-defined model types - in this case Tensorflow. In fact, our deployment strategy for the KNN-based model we trained is to first "export" it to a TF-Recs model with keras (the function
keras_model), and then deploy it to SageMaker with their TensorFlowModel abstraction. If you wish, you can build your own container and serve predictions directly from the gensim model that we trained - for simplicity, and to showcase another open-source library, we opted here to convert the space to a TF model.
Note that after deployment, getting actual, live predictions in code is as easy as calling result = predictor.predict(input).
Setup
You will need access to the appropriate SageMaker execution role to run this code. You can read more about the AmazonSageMakerFullAccess IAM role, as well as more granular permissions in this guide. Once this role is in your IAM policy, we can use it to create SageMaker resources for tasks like training jobs and deploying models to endpoints.
Please consider that:
- SageMaker allows you to pick a Docker image and hardware. The image we picked is compatible with TensorFlow models. The hardware can be changed but please do so with caution as SageMaker can be very expensive;
- the code in the following flow automatically deletes the endpoint after making one test prediction - this is to save money. If you wish to test the endpoint for longer, comment out the delete endpoint line and use the same Python code to get predictions from a notebook, for example.
3Deploy your model from a flow!
This flow extends episode 4 where we trained several models in parallel. The new steps include
- The
keras_modelfunction helps us package our KNN model using generic TensorFlow abstractions so we can leverage the TensorFlow and Sagemaker integration. - The
build_retrieval_modelcalls thekeras_modelfunction, zips up the model, and sends it to S3 using Metaflow's built-in S3 client. - The
deploystep calls thebuild_retrieval_modelfunction and deploys the resulting model as a Sagemaker endpoint with our choice of the underlying Docker image and hardware capabilities.
# global imports
from metaflow import FlowSpec, step, S3, Parameter, current, card
from metaflow.cards import Markdown, Table
import os
import json
import time
from random import choice
class RecSysSagemakerDeployment(FlowSpec):
IS_DEV = Parameter(
name='is_dev',
help='Flag for dev development, with a smaller dataset',
default='1'
)
KNN_K = Parameter(
name='knn_k',
help='Number of neighbors we retrieve from the vector space',
default='100'
)
# NOTE: Sagemaker-specific parameters below here
# If you don't wish to deploy the model, you can leave 'sagemaker_deploy' as 0,
# and ignore the other parameters. Check the README for more details.
SAGEMAKER_DEPLOY = Parameter(
name='sagemaker_deploy',
help='Deploy KNN model with Sagemaker',
default='0'
)
SAGEMAKER_IMAGE = Parameter(
name='sagemaker_image',
help='Image to use in the Sagemaker endpoint: this is compatible with our TF recs KNN model',
default='763104351884.dkr.ecr.us-west-2.amazonaws.com/tensorflow-inference:2.7.0-gpu-py38-cu112-ubuntu20.04-sagemaker'
)
SAGEMAKER_INSTANCE = Parameter(
name='sagemaker_instance',
help='AWS instance for the Sagemaker endpoint: this may be expensive!',
default='ml.p3.2xlarge'
)
SAGEMAKER_ROLE = Parameter(
name='sagemaker_role',
help='IAM role in AWS to use to spin up the Sagemaker endpoint',
default='MetaSageMakerRole'
)
@step
def start(self):
"""
Start-up: check everything works or fail fast!
"""
from metaflow.metaflow_config import DATASTORE_SYSROOT_S3
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("username: %s" % current.username)
print("datastore is: %s" % DATASTORE_SYSROOT_S3)
if self.IS_DEV == '1':
print("ATTENTION: RUNNING AS DEV VERSION - DATA WILL BE SUB-SAMPLED!!!")
if self.SAGEMAKER_DEPLOY == '1':
print("ATTENTION: DEPLOYMENT TO SAGEMAKER IS ENABLED!")
assert DATASTORE_SYSROOT_S3 is not None
self.next(self.prepare_dataset)
@step
def prepare_dataset(self):
"""
Get the data in the right shape by reading the parquet dataset
and using duckdb SQL-based wrangling to quickly prepare the datasets for
training our Recommender System.
"""
import duckdb
import numpy as np
con = duckdb.connect(database=':memory:')
con.execute("""
CREATE TABLE playlists AS
SELECT *,
CONCAT (user_id, '-', playlist) as playlist_id,
CONCAT (artist, '|||', track) as track_id,
FROM 'cleaned_spotify_dataset.parquet'
;
""")
con.execute("SELECT * FROM playlists LIMIT 1;")
print(con.fetchone())
tables = ['row_id', 'user_id', 'track_id', 'playlist_id', 'artist']
for t in tables:
con.execute("SELECT COUNT(DISTINCT({})) FROM playlists;".format(t))
print("# of {}".format(t), con.fetchone()[0])
sampling_cmd = ''
if self.IS_DEV == '1':
print("Subsampling data, since this is DEV")
sampling_cmd = ' USING SAMPLE 10 PERCENT (bernoulli)'
dataset_query = """
SELECT * FROM
(
SELECT
playlist_id,
LIST(artist ORDER BY row_id ASC) as artist_sequence,
LIST(track_id ORDER BY row_id ASC) as track_sequence,
array_pop_back(LIST(track_id ORDER BY row_id ASC)) as track_test_x,
LIST(track_id ORDER BY row_id ASC)[-1] as track_test_y
FROM
playlists
GROUP BY playlist_id
HAVING len(track_sequence) > 2
)
{}
;
""".format(sampling_cmd)
con.execute(dataset_query)
df = con.fetch_df()
print("# rows: {}".format(len(df)))
print(df.iloc[0].tolist())
con.close()
train, validate, test = np.split(
df.sample(frac=1, random_state=42),
[int(.7 * len(df)), int(.9 * len(df))])
self.df_dataset = df
self.df_train = train
self.df_validate = validate
self.df_test = test
print("# testing rows: {}".format(len(self.df_test)))
self.hypers_sets = [json.dumps(_) for _ in [
{ 'min_count': 3, 'epochs': 30, 'vector_size': 48, 'window': 10, 'ns_exponent': 0.75 },
{ 'min_count': 5, 'epochs': 30, 'vector_size': 48, 'window': 10, 'ns_exponent': 0.75 },
{ 'min_count': 10, 'epochs': 30, 'vector_size': 48, 'window': 10, 'ns_exponent': 0.75 }
]]
# we train K models in parallel, depending how many configurations of hypers
# we set - we generate K set of vectors, and evaluate them on the validation
# set to pick the best combination of parameters!
self.next(self.generate_embeddings, foreach='hypers_sets')
def predict_next_track(self, vector_space, input_sequence, k):
"""
Given an embedding space, predict best next song with KNN.
Initially, we just take the LAST item in the input playlist as the query item for KNN
and retrieve the top K nearest vectors (you could think of taking the smoothed average embedding
of the input list, for example, as a refinement).
If the query item is not in the vector space, we make a random bet. We could refine this by taking
for example the vector of the artist (average of all songs), or with some other strategy (sampling
by popularity).
For more options on how to generate vectors for "cold items" see for example the paper:
https://dl.acm.org/doi/10.1145/3383313.3411477
"""
query_item = input_sequence[-1]
if query_item not in vector_space:
query_item = choice(list(vector_space.index_to_key))
return [_[0] for _ in vector_space.most_similar(query_item, topn=k)]
def evaluate_model(self, _df, vector_space, k):
lambda_predict = lambda row: self.predict_next_track(vector_space, row['track_test_x'], k)
_df['predictions'] = _df.apply(lambda_predict, axis=1)
lambda_hit = lambda row: 1 if row['track_test_y'] in row['predictions'] else 0
_df['hit'] = _df.apply(lambda_hit, axis=1)
hit_rate = _df['hit'].sum() / len(_df)
return hit_rate
@step
def generate_embeddings(self):
"""
Generate vector representations for songs, based on the Prod2Vec idea.
For an overview of the algorithm and the evaluation, see for example:
https://arxiv.org/abs/2007.14906
"""
from gensim.models.word2vec import Word2Vec
self.hyper_string = self.input
self.hypers = json.loads(self.hyper_string)
track2vec_model = Word2Vec(self.df_train['track_sequence'], **self.hypers)
print("Training with hypers {} is completed!".format(self.hyper_string))
print("Vector space size: {}".format(len(track2vec_model.wv.index_to_key)))
test_track = choice(list(track2vec_model.wv.index_to_key))
print("Example track: '{}'".format(test_track))
test_vector = track2vec_model.wv[test_track]
print("Test vector for '{}': {}".format(test_track, test_vector[:5]))
test_sims = track2vec_model.wv.most_similar(test_track, topn=3)
print("Similar songs to '{}': {}".format(test_track, test_sims))
self.validation_metric = self.evaluate_model(
self.df_validate,
track2vec_model.wv,
k=int(self.KNN_K))
print("Hit Rate@{} is: {}".format(self.KNN_K, self.validation_metric))
self.track_vectors = track2vec_model.wv
self.next(self.join_runs)
@card(type='blank', id='hyperCard')
@step
def join_runs(self, inputs):
"""
Join the parallel runs and merge results into a dictionary.
"""
self.all_vectors = { inp.hyper_string: inp.track_vectors for inp in inputs}
self.all_results = { inp.hyper_string: inp.validation_metric for inp in inputs}
print("Current result map: {}".format(self.all_results))
self.best_model, self_best_result = sorted(self.all_results.items(), key=lambda x: x[1], reverse=True)[0]
print("The best validation score is for model: {}, {}".format(self.best_model, self_best_result))
self.final_vectors = self.all_vectors[self.best_model]
self.final_dataset = inputs[0].df_test
current.card.append(Markdown("## Results from parallel training"))
current.card.append(
Table([
[inp.hyper_string, inp.validation_metric] for inp in inputs
])
)
self.next(self.model_testing)
@step
def model_testing(self):
"""
Test the generalization abilities of the best model by running predictions
on the unseen test data.
We report a quantitative point-wise metric, hit rate @ K, as an initial implementation. However,
evaluating recommender systems is a very complex task, and better metrics, through good abstractions,
are available, i.e. https://reclist.io/.
"""
self.test_metric = self.evaluate_model(
self.final_dataset,
self.final_vectors,
k=int(self.KNN_K))
print("Hit Rate@{} on the test set is: {}".format(self.KNN_K, self.test_metric))
self.next(self.deploy)
def keras_model(
self,
all_ids: list,
song_vectors, # np array with vectors
test_id: str,
test_vector
):
"""
Build a retrieval model using TF recommender abstraction - by packaging the vector space
in a Keras object, we get for free the possibility of shipping the artifact "as is" to
a Sagemaker endpoint, and benefit from the PaaS abstraction and hardware acceleration.
Of course, other deployment options are possible, including for example using a custom script
and a custom image with Sagemaker.
"""
import tensorflow as tf
import tensorflow_recommenders as tfrs
import numpy as np
embedding_dimension = song_vectors[0].shape[0]
print("Vector space dims: {}".format(embedding_dimension))
unknown_vector = np.zeros((1, embedding_dimension))
print(song_vectors.shape, unknown_vector.shape)
embedding_matrix = np.r_[unknown_vector, song_vectors]
print(embedding_matrix.shape)
assert embedding_matrix[0][0] == 0.0
embedding_layer = tf.keras.layers.Embedding(len(all_ids) + 1, embedding_dimension)
embedding_layer.build((None, ))
embedding_layer.set_weights([embedding_matrix])
embedding_layer.trainable = False
vector_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=all_ids, mask_token=None),
embedding_layer
])
_v = vector_model(np.array([test_id]))
# debug
print(test_vector[:3])
print(_v[0][:3])
# test unknonw ID
print("Test unknown id:")
print(vector_model(np.array(['blahdagkagda']))[0][:3])
song_index = tfrs.layers.factorized_top_k.BruteForce(vector_model)
song_index.index(song_vectors, np.array(all_ids))
_, names = song_index(tf.constant([test_id]))
print(f"Recommendations after track '{test_id}': {names[0, :3]}")
return song_index
def build_retrieval_model(self):
"""
Take the embedding space, build a Keras KNN model and store it in S3
so that it can be deployed by a Sagemaker endpoint!
While for simplicity this function is embedded in the deploy step,
you could think of spinning it out as it's own step.
"""
import tarfile
self.model_timestamp = int(round(time.time() * 1000))
model_name = "playlist-recs-model-{}/1".format(self.model_timestamp )
local_tar_name = 'model-{}.tar.gz'.format(self.model_timestamp)
self.test_index = 3
retrieval_model = self.keras_model(
self.all_ids,
self.startup_embeddings,
self.all_ids[self.test_index],
self.startup_embeddings[self.test_index]
)
retrieval_model.save(filepath=model_name)
with tarfile.open(local_tar_name, mode="w:gz") as _tar:
_tar.add(model_name, recursive=True)
with open(local_tar_name, "rb") as in_file:
data = in_file.read()
with S3(run=self) as s3:
url = s3.put(local_tar_name, data)
print("Model saved at: {}".format(url))
return url
@step
def deploy(self):
"""
Inspired by: https://github.com/jacopotagliabue/no-ops-machine-learning/blob/main/flow/training.py
Use SageMaker to deploy the model as a stand-alone, PaaS endpoint, with our choice of the underlying
Docker image and hardware capabilities.
Available images for inferences can be chosen from AWS official list:
https://github.com/aws/deep-learning-containers/blob/master/available_images.md
"""
import numpy as np
self.all_ids = list(self.final_vectors.index_to_key)
self.startup_embeddings = np.array([self.final_vectors[_] for _ in self.all_ids])
if self.SAGEMAKER_DEPLOY == '0':
print("Skipping deployment to Sagemaker")
else:
self.model_s3_path = self.build_retrieval_model()
from sagemaker.tensorflow import TensorFlowModel
self.ENDPOINT_NAME = 'playlist-recs-{}-endpoint'.format(self.model_timestamp)
print("\n\n================\nEndpoint name is: {}\n\n".format(self.ENDPOINT_NAME))
model = TensorFlowModel(
model_data=self.model_s3_path,
image_uri=self.SAGEMAKER_IMAGE,
role=self.SAGEMAKER_ROLE
)
predictor = model.deploy(
initial_instance_count=1,
instance_type=self.SAGEMAKER_INSTANCE,
endpoint_name=self.ENDPOINT_NAME
)
input = {'instances': np.array([self.all_ids[self.test_index]])}
result = predictor.predict(input)
print(input, result)
print("Deleting endpoint now...")
predictor.delete_endpoint()
print("Endpoint deleted!")
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
RecSysSagemakerDeployment()
4Run your flow
To run this flow and deploy to Sagemaker, you will need:
- Access to a Metaflow deployment on AWS. Reach us on Slack if you need help getting set up!
- Your active Metaflow profile to be configured with an S3 as the
DATASTORE_SYSROOT_S3variable. You can find the default config at$HOME/.metaflowconfig/config.json. Read more here. - To set the argument
--sagemaker_deploy 1. - To set the argument
--sagemaker_role <YOUR SAGEMAKER EXECUTION ROLE>.
python recsys_deploy.py run --sagemaker_deploy 1 --sagemaker_role <SAGEMAKER_ROLE>
Conclusion
Congratulations, you have completed Metaflow's introductory tutorial on recommender system workflows! You have learned how to:
- take a recommender system idea from prototype to real-time production;
- leverage Metaflow to train different versions of the same model and pick the best one;
- use Metaflow cards to save important details about model performance;
- package a representation of your data in a keras object that you can deploy directly from the flow to a cloud endpoint with AWS Sagemaker.
To keep progressing in your Metaflow journey you can:
- Check out the open-source repository.
- Join our Slack community and learn with us in #ask-metaflow.
- We are actively working on more advanced recommender system tutorials. Please send us your suggestions and questions!