Recommender Systems with Metaflow: Intermediate Tutorial
This tutorial is an adventure in training recommender systems using Metaflow. In the end, you will have a scalable workflow to use for experimentation and in production systems. After dipping our toes into recommender systems in our first tutorial, we are ready for more complex data flows and architecture.
In particular, in this tutorial we use the H&M dataset to reproduce a classic user-item, offline training-offline serving recommendation use case.
You will implement your own reasonable scale recommender system. To read more about the original work from Ronay Ak and Jacopo Tagliabue that this tutorial is based on, check out their blog post and this webinar.
Stay tuned to get hands on and learn much more!
Tuning Merlin with Metaflow
Try it out directly in your browser
from metaflow import FlowSpec, step, kubernetes, Parameter, current
from custom_decorators import magicdir
import os
import json
from datetime import datetime
class MerlinTuningFlow(FlowSpec):
### MERLIN PARAMETERS ###
MODEL_FOLDER = Parameter(
name="model_folder",
help="Folder to store the model from Merlin, between steps",
default="merlin_model",
)
### DATA PARAMETERS ###
ROW_SAMPLING = Parameter(
name="row_sampling",
help="Row sampling: if 0, NO sampling is applied. Needs to be an int between 1 and 100",
default="1",
)
# NOTE: data parameters - we split by time, leaving the last two weeks for validation and tests
# The first date in the table is 2018-09-20
# The last date in the table is 2020-09-22
TRAINING_END_DATE = Parameter(
name="training_end_date",
help="Data up until this date is used for training, format yyyy-mm-dd",
default="2018-10-20",
)
VALIDATION_END_DATE = Parameter(
name="validation_end_date",
help="Data up after training end and until this date is used for validation, format yyyy-mm-dd",
default="2018-11-20",
)
### TRAINING PARAMETERS ###
VALIDATION_METRIC = Parameter(
name="validation_metric",
help="Merlin metric to use for picking the best set of hyperparameter",
default="recall_at_10",
)
N_EPOCHS = Parameter(
name="n_epoch",
help="Number of epochs to train the Merlin model",
default="1", # default to 1 for quick testing
)
TOP_K = Parameter(
name="top_k",
help="Number of products to recommend for a giver shopper",
default="10",
)
@step
def start(self):
"""
Start-up: check everything works or fail fast!
"""
# print out some debug info
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("username: %s" % current.username)
# we need to check if Metaflow is running with remote (s3) data store or not
from metaflow.metaflow_config import DATASTORE_SYSROOT_S3
print("DATASTORE_SYSROOT_S3: %s" % DATASTORE_SYSROOT_S3)
if DATASTORE_SYSROOT_S3 is None:
print("ATTENTION: LOCAL DATASTORE ENABLED")
# check variables and connections are working fine
assert int(self.ROW_SAMPLING)
# check the data range makes sense
self.training_end_date = datetime.strptime(self.TRAINING_END_DATE, "%Y-%m-%d")
self.validation_end_date = datetime.strptime(
self.VALIDATION_END_DATE, "%Y-%m-%d"
)
assert self.validation_end_date > self.training_end_date
self.next(self.get_dataset)
@step
def get_dataset(self):
"""
Get the data in the right shape using duckDb, after the dbt transformation
"""
from pyarrow import Table as pt
import duckdb
# check if we need to sample - this is useful to iterate on the code with a real setup
# without reading in too much data...
_sampling = int(self.ROW_SAMPLING)
sampling_expression = (
""
if _sampling == 0
else "USING SAMPLE {} PERCENT (bernoulli)".format(_sampling)
)
# thanks to our dbt preparation, the ML models can read in directly the data without additional logic
query = """
SELECT
ARTICLE_ID,
PRODUCT_CODE,
PRODUCT_TYPE_NO,
PRODUCT_GROUP_NAME,
GRAPHICAL_APPEARANCE_NO,
COLOUR_GROUP_CODE,
PERCEIVED_COLOUR_VALUE_ID,
PERCEIVED_COLOUR_MASTER_ID,
DEPARTMENT_NO,
INDEX_CODE,
INDEX_GROUP_NO,
SECTION_NO,
GARMENT_GROUP_NO,
ACTIVE,
FN,
AGE,
CLUB_MEMBER_STATUS,
CUSTOMER_ID,
FASHION_NEWS_FREQUENCY,
POSTAL_CODE,
PRICE,
SALES_CHANNEL_ID,
T_DAT
FROM
read_parquet('filtered_dataframe.parquet')
{}
ORDER BY
T_DAT ASC
""".format(
sampling_expression
)
print(
"Fetching rows with query: \n {} \n\nIt may take a while...\n".format(query)
)
# fetch raw dataset
con = duckdb.connect(database=":memory:")
con.execute(query)
dataset = con.fetchall()
# convert the COLS to lower case (Keras does complain downstream otherwise)
cols = [c[0].lower() for c in con.description]
dataset = [{k: v for k, v in zip(cols, row)} for row in dataset]
# debug
print("Example row", dataset[0])
self.item_id_2_meta = {str(r["article_id"]): r for r in dataset}
# we split by time window, using the dates specified as parameters
# NOTE: we could actually return Arrow table directly, by then running three queries over
# a different date range (e.g. https://duckdb.org/2021/12/03/duck-arrow.html)
# For simplicity, we kept here the original flow compatible with warehouse processing
train_dataset = pt.from_pylist(
[row for row in dataset if row["t_dat"] < self.training_end_date]
)
validation_dataset = pt.from_pylist(
[
row
for row in dataset
if row["t_dat"] >= self.training_end_date
and row["t_dat"] < self.validation_end_date
]
)
test_dataset = pt.from_pylist(
[row for row in dataset if row["t_dat"] >= self.validation_end_date]
)
print(
"# {:,} events in the training set, {:,} for validation, {:,} for test".format(
len(train_dataset), len(validation_dataset), len(test_dataset)
)
)
# store and version datasets as a map label -> datasets, for consist processing later on
self.label_to_dataset = {
"train": train_dataset,
"valid": validation_dataset,
"test": test_dataset,
}
# go to the next step for NV tabular data
self.next(self.build_workflow)
# NOTE: we use the magicdir package (https://github.com/outerbounds/metaflow_magicdir)
# to simplify moving the parquet files that Merlin needs / consumes across steps
@magicdir
@step
def build_workflow(self):
"""
Use NVTabular to transform the original data into the final dataframes for training,
validation, testing.
"""
from workflow_builder import get_nvt_workflow, read_to_dataframe
import pandas as pd
import nvtabular as nvt # pylint: disable=import-error
import itertools
# read dataset into frames
label_to_df = {}
for label, dataset in self.label_to_dataset.items():
label_to_df[label] = read_to_dataframe(dataset, label)
full_dataset = nvt.Dataset(pd.concat(list(label_to_df.values())))
# get the workflow and fit the dataset
workflow = get_nvt_workflow()
workflow.fit(full_dataset)
self.label_to_melin_dataset = {}
for label, _df in label_to_df.items():
cnt_dataset = nvt.Dataset(_df)
self.label_to_melin_dataset[label] = cnt_dataset
workflow.transform(cnt_dataset).to_parquet(
output_path="merlin/{}/".format(label)
)
# store the mapping Merlin ID -> article_id and Merlin ID -> customer_id
user_unique_ids = list(
pd.read_parquet("categories/unique.customer_id.parquet")["customer_id"]
)
items_unique_ids = list(
pd.read_parquet("categories/unique.article_id.parquet")["article_id"]
)
self.id_2_user_id = {idx: _ for idx, _ in enumerate(user_unique_ids)}
self.id_2_item_id = {idx: _ for idx, _ in enumerate(items_unique_ids)}
# sets of hypers
# batch size
batch_sizes = [16384, 4096]
# learning rate
learning_rates = [0.04, 0.02]
grid_search = []
for params in itertools.product(batch_sizes, learning_rates):
grid_search.append({"BATCH_SIZE": params[0], "LEARNING_RATE": params[1]})
# we serialize hypers to a string and pass them to the foreach below
# NOTE: to save time and compute, we limit the foreach to two hypers
self.hypers_sets = [json.dumps(_) for _ in grid_search[:3]]
# debug
print(self.hypers_sets)
self.next(self.train_model, foreach="hypers_sets")
# @kubernetes(
# cpu=1,
# memory=12288,
# image='public.ecr.aws/outerbounds/merlin-reasonable-scale:22.11-latest'
# )
@magicdir
@step
def train_model(self):
"""
Train models in parallel and store artifacts and validation KPIs for downstream consumption.
"""
import hashlib
import merlin.models.tf as mm # pylint: disable=import-error
from merlin.io.dataset import Dataset # pylint: disable=import-error
from merlin.schema.tags import Tags # pylint: disable=import-error
import tensorflow as tf # pylint: disable=import-error
# this is the CURRENT hyper param JSON in the fan-out
# each copy of this step in the parallelization will have its own value
self.hyper_string = self.input
self.hypers = json.loads(self.hyper_string)
train = Dataset("merlin/train/*.parquet")
valid = Dataset("merlin/valid/*.parquet")
print(
"Train dataset shape: {}, Validation: {}".format(
train.to_ddf().compute().shape, valid.to_ddf().compute().shape
)
)
# train the model and evaluate it on validation set
user_schema = train.schema.select_by_tag(Tags.USER) # MERLIN WARNING
user_inputs = mm.InputBlockV2(user_schema)
query = mm.Encoder(user_inputs, mm.MLPBlock([128, 64]))
item_schema = train.schema.select_by_tag(Tags.ITEM)
item_inputs = mm.InputBlockV2(
item_schema,
)
candidate = mm.Encoder(item_inputs, mm.MLPBlock([128, 64]))
model = mm.TwoTowerModelV2(query, candidate)
opt = tf.keras.optimizers.Adagrad(learning_rate=self.hypers["LEARNING_RATE"])
model.compile(
optimizer=opt,
run_eagerly=False,
metrics=[mm.RecallAt(int(self.TOP_K)), mm.NDCGAt(int(self.TOP_K))],
)
model.fit(
train,
validation_data=valid,
batch_size=self.hypers["BATCH_SIZE"],
epochs=int(self.N_EPOCHS),
)
self.metrics = model.evaluate(valid, batch_size=1024, return_dict=True)
print("\n\n====> Eval results: {}\n\n".format(self.metrics))
# save the model
model_hash = str(hashlib.md5(self.hyper_string.encode("utf-8")).hexdigest())
self.model_path = "merlin/model{}/".format(model_hash)
model.save(self.model_path)
print(f"Model saved to {self.model_path}!")
self.next(self.join_runs)
def get_items_topk_recommender_model(self, train_dataset, model, k: int):
from merlin.models.utils.dataset import (
unique_rows_by_features,
) # pylint: disable=import-error
from merlin.schema.tags import Tags # pylint: disable=import-error
candidate_features = unique_rows_by_features(
train_dataset, Tags.ITEM, Tags.ITEM_ID
)
topk_model = model.to_top_k_encoder(candidate_features, k=k, batch_size=128)
topk_model.compile(run_eagerly=False)
return topk_model
@step
def join_runs(self, inputs):
"""
Join the parallel runs and merge results into a dictionary.
"""
# merge results from runs with different parameters (key is hyper settings as a string)
self.model_paths = {inp.hyper_string: inp.model_path for inp in inputs}
self.results_from_runs = {
inp.hyper_string: inp.metrics[self.VALIDATION_METRIC] for inp in inputs
}
print("Current results: {}".format(self.results_from_runs))
# pick one according to some logic, e.g. higher VALIDATION_METRIC
self.best_model, self_best_result = sorted(
self.results_from_runs.items(), key=lambda x: x[1], reverse=True
)[0]
print(
"Best model is: {}, best path is {}".format(
self.best_model, self.model_paths[self.best_model]
)
)
# assign the variable for the "final" (the best) model path in S3 and its corresponding name
self.final_model_path = self.model_paths[self.best_model]
# pick a final mapping for metadata and other service variables
best_model_idx = list(self.model_paths.keys()).index(self.best_model)
self.item_id_2_meta = inputs[best_model_idx].item_id_2_meta
self.id_2_item_id = inputs[best_model_idx].id_2_item_id
self.id_2_user_id = inputs[best_model_idx].id_2_user_id
self.magicdir = inputs[best_model_idx].magicdir
# next, for the best model do more testing
self.next(self.model_testing)
def load_merlin_model(self, dataset, path):
import tensorflow as tf # pylint: disable=import-error
import merlin.models.tf as mm # pylint: disable=import-error
loaded_model = tf.keras.models.load_model(path, compile=False)
# this is necessary when re-loading the model, before building the top K
_ = loaded_model(
mm.sample_batch(dataset, batch_size=128, include_targets=False)
)
# debug
print("Model re-loaded!")
return loaded_model
# @kubernetes(
# cpu=1,
# memory=12288,
# image='public.ecr.aws/outerbounds/merlin-reasonable-scale:22.11-latest'
# )
@magicdir
@step
def model_testing(self):
"""
Test the generalization abilities of the best model through the held-out set...
and RecList Beta (Forthcoming!)
"""
from merlin.io.dataset import Dataset # pylint: disable=import-error
import merlin.models.tf as mm # pylint: disable=import-error
from merlin.schema import Tags # pylint: disable=import-error
# loading back datasets and the model for final testing
test = Dataset("merlin/test/*.parquet")
train = Dataset("merlin/train/*.parquet")
loaded_model = self.load_merlin_model(train, self.final_model_path)
topk_rec_model = self.get_items_topk_recommender_model(
test, loaded_model, k=int(self.TOP_K)
)
# extract the target item id from the inputs
test_loader = mm.Loader(
test, batch_size=1024, transform=mm.ToTarget(test.schema, Tags.ITEM_ID)
)
self.test_metrics = topk_rec_model.evaluate(
test_loader, batch_size=1024, return_dict=True
)
print("\n\n====> Test results: {}\n\n".format(self.test_metrics))
# calculate recommendations
topk_rec_model = self.get_items_topk_recommender_model(
train, loaded_model, k=int(self.TOP_K)
)
self.best_predictions = self.get_recommendations(test, topk_rec_model)
self.next(self.end)
def get_recommendations(self, test, topk_rec_model):
"""
Run predictions on a target dataset of shoppers (in this case, the testing dataset)
and store the predictions for the cache downstream.
"""
import merlin.models.tf as mm # pylint: disable=import-error
# export ONLY the users in the test set to simulate the set of shoppers we need to recommend items to
test_dataset = mm.Loader(test, batch_size=1024, shuffle=False)
# predict returns a tuple with two elements, scores and product IDs: we get the IDs only
self.raw_predictions = topk_rec_model.predict(test_dataset)[1]
n_rows = self.raw_predictions.shape[0]
self.target_shoppers = test_dataset.data.to_ddf().compute()["customer_id"]
print(
"Inspect the shopper object for debugging...{}".format(
type(self.target_shoppers)
)
)
# check we have as many predictions as we have shoppers in the test set
assert n_rows == len(self.target_shoppers)
# map predictions to a final dictionary, with the actual H and M IDs for users and products
self.h_m_shoppers = [
str(self.id_2_user_id[_]) for _ in self.target_shoppers.to_numpy().tolist()
]
print("Example target shoppers: ", self.h_m_shoppers[:3])
self.target_items = test_dataset.data.to_ddf().compute()["article_id"]
print("Example target items: ", self.target_items[:3])
predictions = self.serialize_predictions(
self.h_m_shoppers,
self.id_2_item_id,
self.raw_predictions,
self.target_items,
n_rows,
)
print("Example target predictions", predictions[self.h_m_shoppers[0]])
# debug, if rows > len(predictions), same user appears at least twice in test set
print(n_rows, len(predictions))
return predictions
def serialize_predictions(
self, h_m_shoppers, id_2_item_id, raw_predictions, target_items, n_rows
):
"""
Convert raw predictions to a dictionary user -> items for easy re-use
later in the pipeline (e.g. dump the predicted items to a cache!)
"""
sku_convert = lambda x: [str(id_2_item_id[_]) for _ in x]
predictions = {}
for _ in range(n_rows):
cnt_user = h_m_shoppers[_]
cnt_raw_preds = raw_predictions[_].tolist()
cnt_target = target_items[_]
# don't overwite if we already have a prediction for this user
if cnt_user not in predictions:
predictions[cnt_user] = {
"items": sku_convert(cnt_raw_preds),
"target": sku_convert([cnt_target])[0],
}
return predictions
@step
def end(self):
"""
Just say bye!
"""
print("All done\n\nSee you, recSys cowboy\n")
return
if __name__ == "__main__":
MerlinTuningFlow()
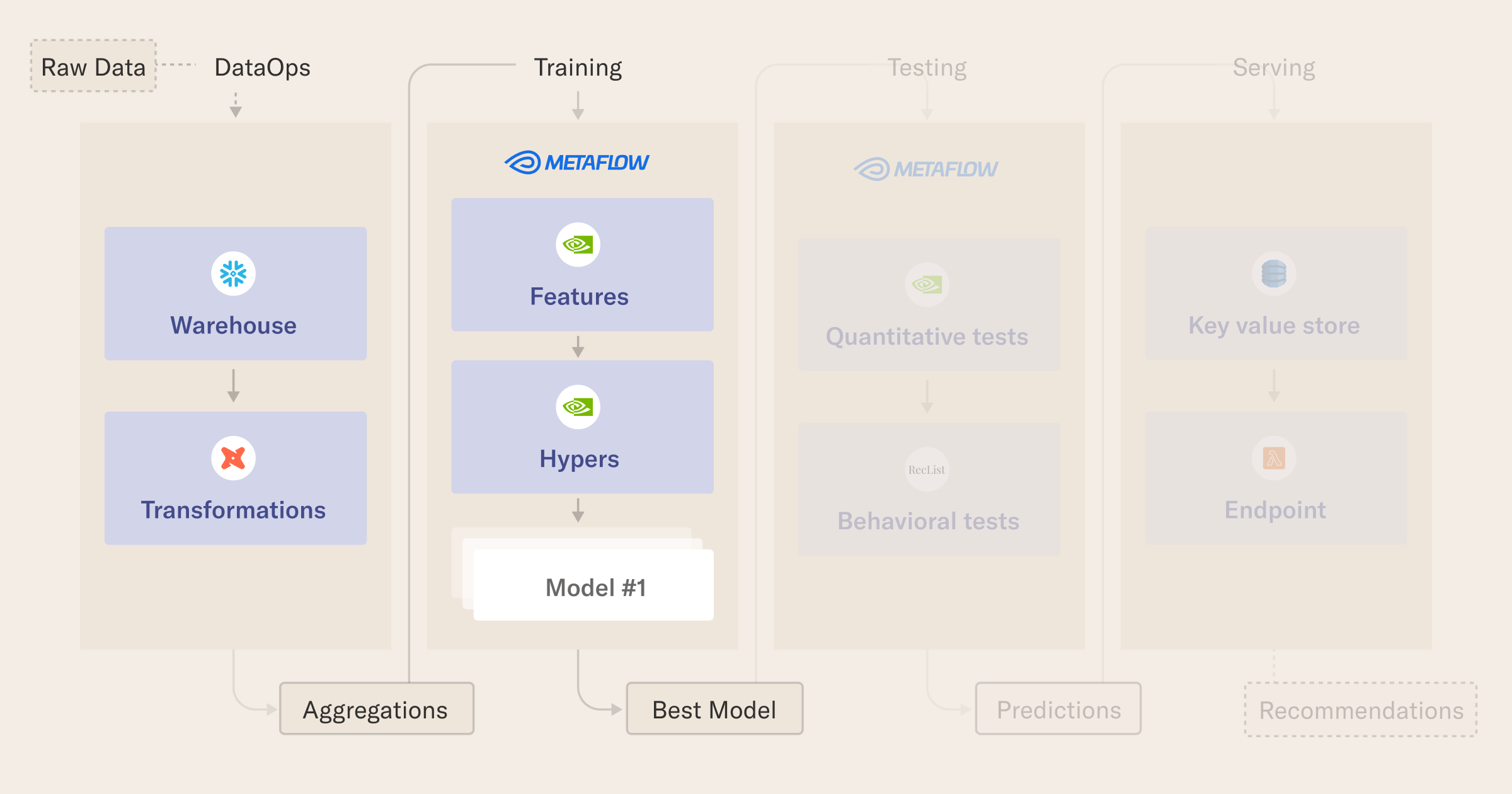
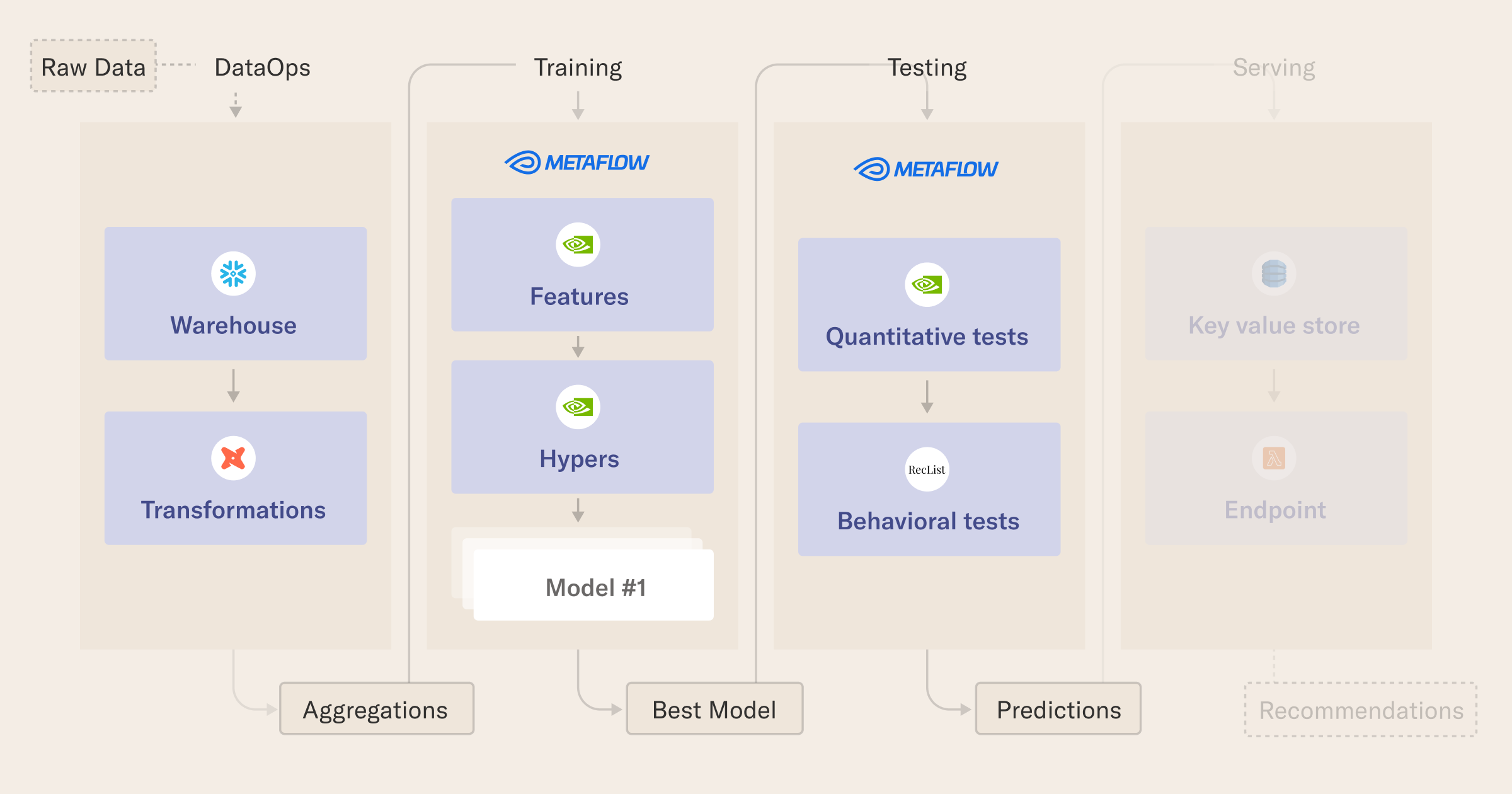
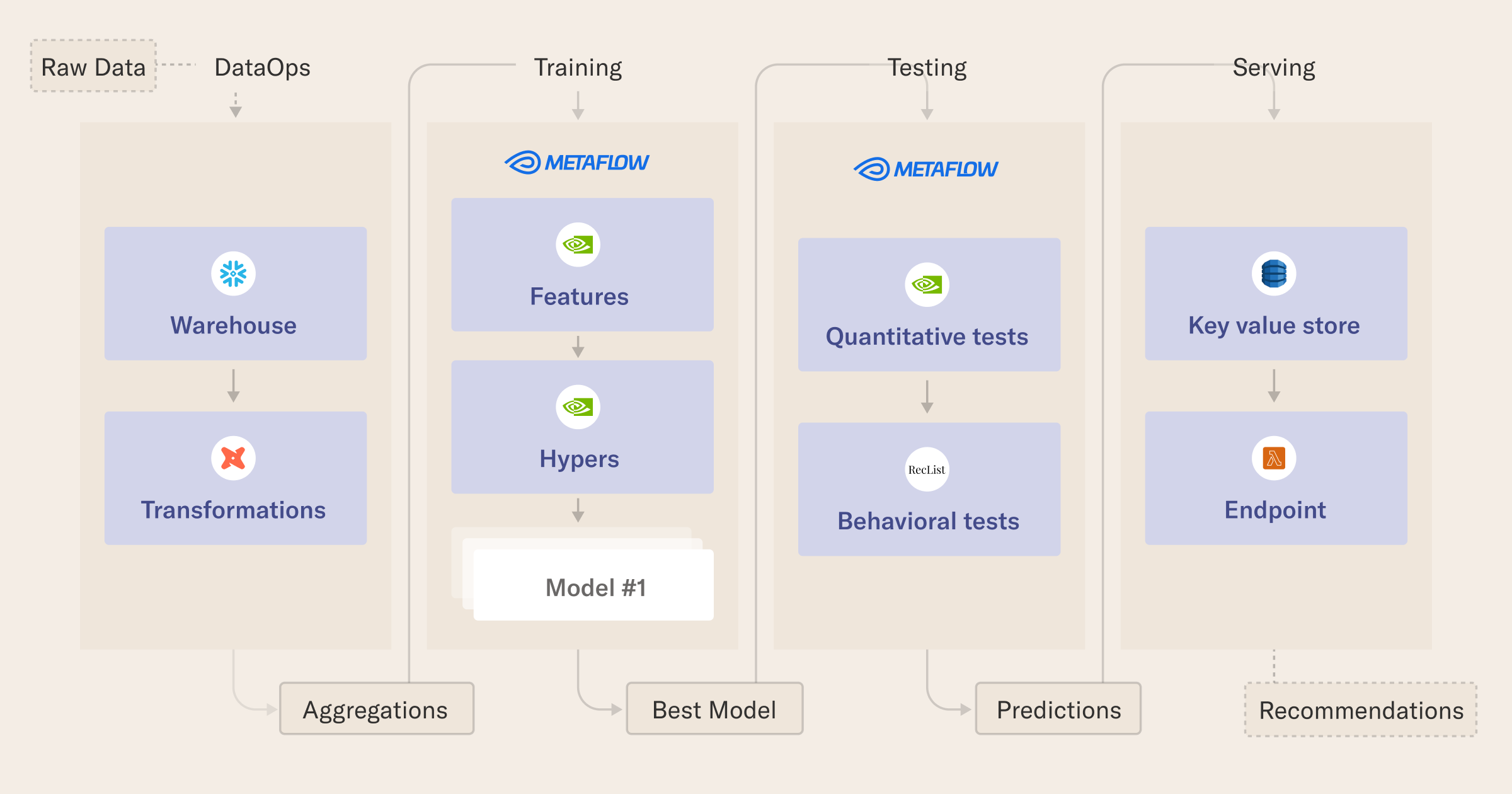
Objectives
In this tutorial, you will learn how to:
- prepare data with DuckDB and dbt,
- structure cloud workflows with Metaflow,
- engineer features on big datasets with NVTabular,
- train a state-of-the-art recommender model using Nvidia Merlin, and
- cache predictions of the winning model in a serverless data store using DynamoDB, AWS Lambda, and the Serverless framework.
Prerequisites
Before starting this tutorial, we suggest you feel confident with the following topics
- a good understanding of Metaflow and basic decorators including:
@step,@batch, etc.; and familiarity with the basic concepts of machine learning such as training, validation, and test split for model evaluation; - a basic understanding of RecSys use cases: Jacopo's intro using embeddings is a great place to start;
- a good understanding of RecSys pipelines: complete our Beginner Recommender Systems Tutorial if you have not done so already;
- nice to have: familiarity with deep learning for the modeling part, and working knowledge of AWS Lambda and DynamoDB for the deployment part.
Tutorial Structure
The content includes the following: