Beginner Recommender Systems: Episode 3
1Embeddings and modeling
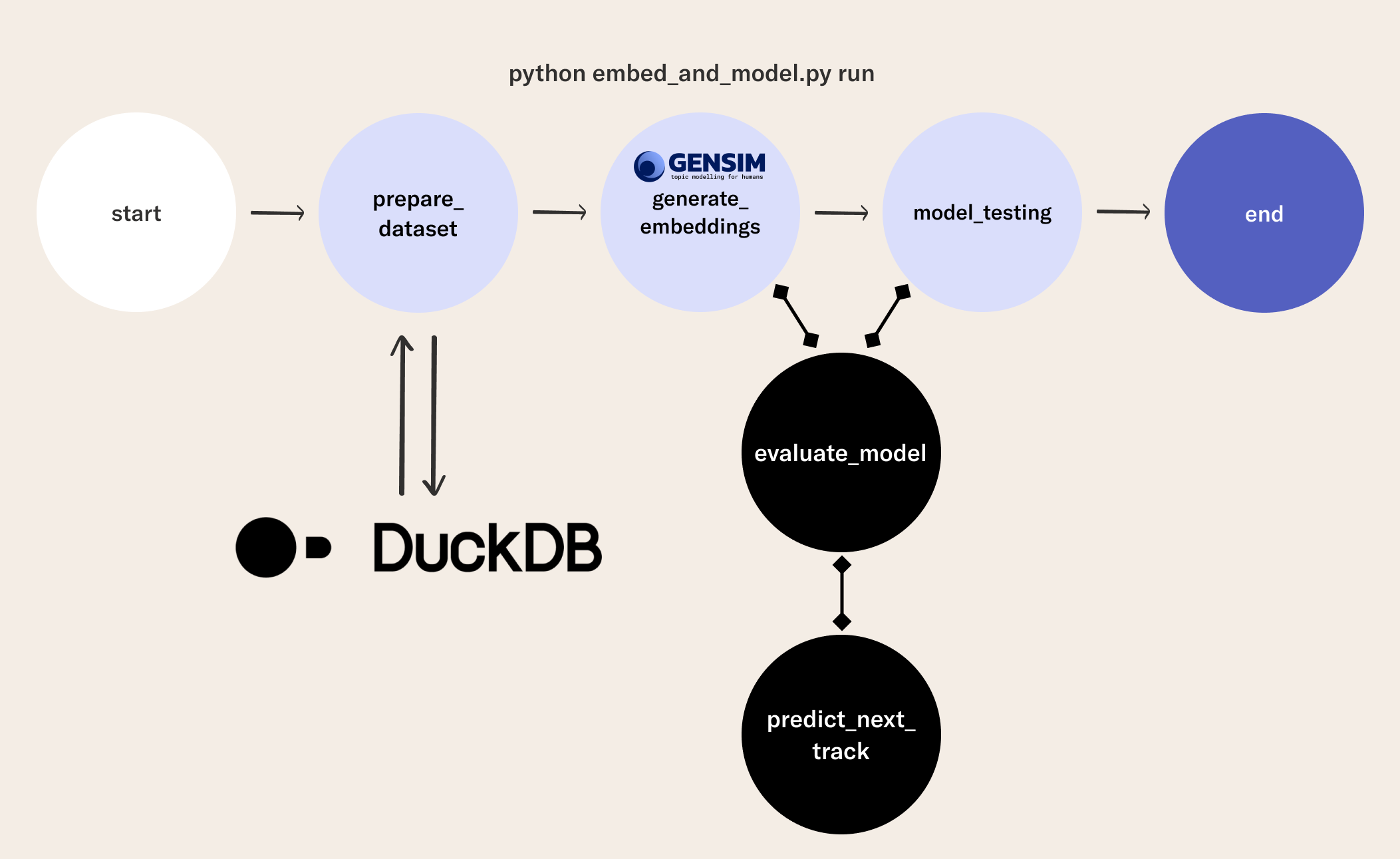
Now we are ready to add model training to our flow. Let's leverage the datasets we prepared with duckDB to train an embedding model for the song data. If you want to follow along, you can find the code in this flow. In particular, self.generate_embeddings trains embeddings for the songs in our dataset.
The intuition for the modeling approach comes from word2vec, an NLP technique that produces a embedding space for words based on their distribution: words that are similar tend to occur in similar contexts. Word2Vec is an algorithm that uses a neural network model to learn word associations by mapping each word to a vector. The mathematical space these vectors live in is the embedding space. At prediction time, we use this space as a way encode input data in a space where we can run the k-nearest neighbors (KNN) algorithm to classify and predict the next song. In this example we compute a standard information retrieval metric - hit rate - to get a sense of how well the model is performing. Again, this whole process is to produce a model that, given a list of songs a user has listened to, learns to suggest a next song the user.
When the latent space has been trained, our candidate model is tested once again, but this time on the unseen test set. The performance on the test set is our estimate of the how the performance of the model will generalize. While summarizing a model with one quantitative test is convenient when getting started with recommender systems, in practice it is recommended to supplement these tests with more robust assessments (https://reclist.io/).
2Extend the flow
In RecModelTrainingFlow, you will see a few new steps after the prepare_dataset step you saw in the last episode.
- The
generate_embeddingsstep uses Word2Vec to process the output ofprepare_dataset. - The
predict_next_trackfunction uses a k-nearest neighbors model to predict the next best song given the embeddings of songs we know the listener enjoys.
from metaflow import FlowSpec, step, S3, Parameter, current
import os
import json
import time
from random import choice
class RecModelTrainingFlow(FlowSpec):
IS_DEV = Parameter(
name='is_dev',
help='Flag for dev development, with a smaller dataset',
default='1'
)
KNN_K = Parameter(
name='knn_k',
help='Number of neighbors we retrieve from the vector space',
default='100'
)
@step
def start(self):
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("username: %s" % current.username)
if self.IS_DEV == '1':
print("ATTENTION: RUNNING AS DEV VERSION - DATA WILL BE SUB-SAMPLED!!!")
self.next(self.prepare_dataset)
@step
def prepare_dataset(self):
"""
Get the data in the right shape by reading the parquet dataset
and using duckdb SQL-based wrangling to quickly prepare the datasets for
training our Recommender System.
"""
import duckdb
import numpy as np
con = duckdb.connect(database=':memory:')
con.execute("""
CREATE TABLE playlists AS
SELECT *,
CONCAT (user_id, '-', playlist) as playlist_id,
CONCAT (artist, '|||', track) as track_id,
FROM 'cleaned_spotify_dataset.parquet'
;
""")
con.execute("SELECT * FROM playlists LIMIT 1;")
print(con.fetchone())
tables = ['row_id', 'user_id', 'track_id', 'playlist_id', 'artist']
for t in tables:
con.execute("SELECT COUNT(DISTINCT({})) FROM playlists;".format(t))
print("# of {}".format(t), con.fetchone()[0])
sampling_cmd = ''
if self.IS_DEV == '1':
print("Subsampling data, since this is DEV")
sampling_cmd = ' USING SAMPLE 10 PERCENT (bernoulli)'
dataset_query = """
SELECT * FROM
(
SELECT
playlist_id,
LIST(artist ORDER BY row_id ASC) as artist_sequence,
LIST(track_id ORDER BY row_id ASC) as track_sequence,
array_pop_back(LIST(track_id ORDER BY row_id ASC)) as track_test_x,
LIST(track_id ORDER BY row_id ASC)[-1] as track_test_y
FROM
playlists
GROUP BY playlist_id
HAVING len(track_sequence) > 2
)
{}
;
""".format(sampling_cmd)
con.execute(dataset_query)
df = con.fetch_df()
print("# rows: {}".format(len(df)))
print(df.iloc[0].tolist())
con.close()
train, validate, test = np.split(
df.sample(frac=1, random_state=42),
[int(.7 * len(df)), int(.9 * len(df))])
self.df_dataset = df
self.df_train = train
self.df_validate = validate
self.df_test = test
print("# testing rows: {}".format(len(self.df_test)))
self.hyper_string = json.dumps({
'min_count': 3,
'epochs': 30,
'vector_size': 48,
'window': 10,
'ns_exponent': 0.75 })
self.next(self.generate_embeddings)
def predict_next_track(self, vector_space, input_sequence, k):
"""
Given an embedding space, predict best next song with KNN.
Initially, we just take the LAST item in the input playlist as the query item for KNN
and retrieve the top K nearest vectors (you could think of taking the smoothed average embedding
of the input list, for example, as a refinement).
If the query item is not in the vector space, we make a random bet. We could refine this by taking
for example the vector of the artist (average of all songs), or with some other strategy (sampling
by popularity).
For more options on how to generate vectors for "cold items" see for example the paper:
https://dl.acm.org/doi/10.1145/3383313.3411477
"""
query_item = input_sequence[-1]
if query_item not in vector_space:
query_item = choice(list(vector_space.index_to_key))
return [_[0] for _ in vector_space.most_similar(query_item, topn=k)]
def evaluate_model(self, _df, vector_space, k):
lambda_predict = lambda row: self.predict_next_track(vector_space, row['track_test_x'], k)
_df['predictions'] = _df.apply(lambda_predict, axis=1)
lambda_hit = lambda row: 1 if row['track_test_y'] in row['predictions'] else 0
_df['hit'] = _df.apply(lambda_hit, axis=1)
hit_rate = _df['hit'].sum() / len(_df)
return hit_rate
@step
def generate_embeddings(self):
"""
Generate vector representations for songs, based on the Prod2Vec idea.
For an overview of the algorithm and the evaluation, see for example:
https://arxiv.org/abs/2007.14906
"""
from gensim.models.word2vec import Word2Vec
self.hypers = json.loads(self.hyper_string)
track2vec_model = Word2Vec(self.df_train['track_sequence'], **self.hypers)
print("Training with hypers {} is completed!".format(self.hyper_string))
print("Vector space size: {}".format(len(track2vec_model.wv.index_to_key)))
test_track = choice(list(track2vec_model.wv.index_to_key))
print("Example track: '{}'".format(test_track))
test_vector = track2vec_model.wv[test_track]
print("Test vector for '{}': {}".format(test_track, test_vector[:5]))
test_sims = track2vec_model.wv.most_similar(test_track, topn=3)
print("Similar songs to '{}': {}".format(test_track, test_sims))
self.validation_metric = self.evaluate_model(
self.df_validate,
track2vec_model.wv,
k=int(self.KNN_K))
print("Hit Rate@{} is: {}".format(self.KNN_K, self.validation_metric))
self.track_vectors = track2vec_model.wv
self.next(self.model_testing)
@step
def model_testing(self):
"""
Test the generalization abilities of the best model by running predictions
on the unseen test data.
We report a quantitative point-wise metric, hit rate @ K, as an initial implementation. However,
evaluating recommender systems is a very complex task, and better metrics, through good abstractions,
are available, i.e. https://reclist.io/.
"""
self.test_metric = self.evaluate_model(
self.df_test,
self.track_vectors,
k=int(self.KNN_K))
print("Hit Rate@{} on the test set is: {}".format(self.KNN_K, self.test_metric))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
RecModelTrainingFlow()
3Run your flow
python embed_and_model.py run
In this lesson, you extended the DataFlow to incorporate feature embeddings and model training.
Next, you will see how to improve our embedding by tuning associated hyperparameters in parallel, leveraging Metaflow's ability to parallelize your code locally or on remote machines with minimal changes to the code.