Beginner Recommender Systems: Episode 4
1Seamless parallelism with Metaflow
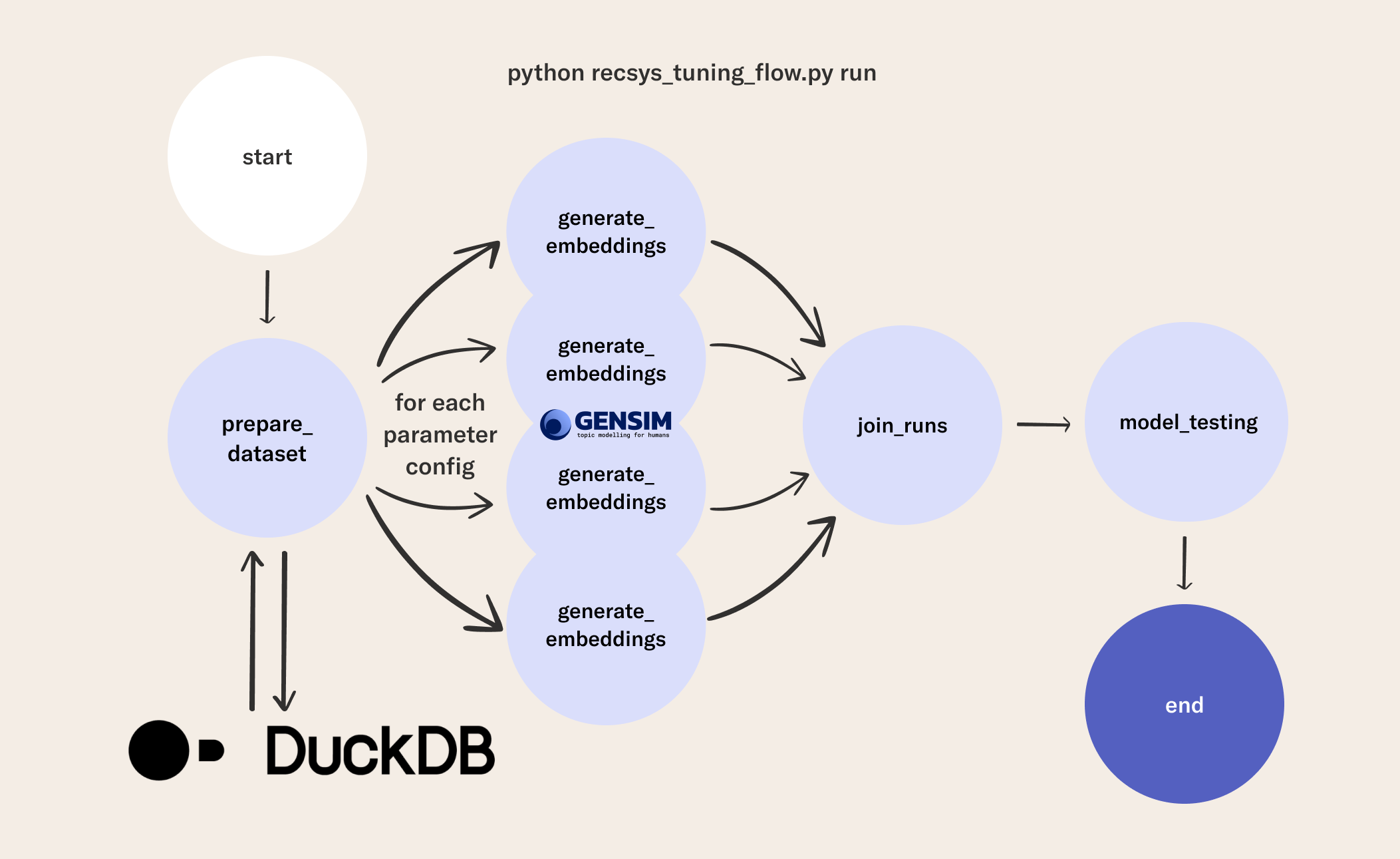
Once you have a functioning process for embedding features and a model that uses them for predictions, we can leverage Metaflow's built-in capabilities for parallelization to take this workflow to the next level. With a slight modification of our flow (note the foreach='hypers_sets' parameter), we can scale tasks that can be parallelized on as many machines as your cloud budget allows.
You can follow along with these modifications in the flow code for this episode. The flow includes tasks like processing data, or in this case hyperparameter tuning. The same logic applies as the flow in the previous episode, but now we tune over many embedding spaces in parallel and pick the best one (on the validation set) to use as our candidate model. As before, we then test our candidate model once again on the held-out set, to give us a sense of its generalization abilities.
2Organize Metaflow run results with cards
We can use Metaflow card abstractions to create cards to document specific components of the pipeline in a versioned, shareable format. For example, @card(type='blank', id='hyperCard') records the performance for all the models we trained. If you wish to use a separate tool for tracking experiments, you can leverage Metaflow integrations with tools like Comet ML and Weights and Biases.
3Find better models with a hyperparemeter tuning flow
In the following code you will see the RecSysTuningFlow. This flow is nearly identical to the previous one.
The changes include:
- Metaflow's
foreachpattern at the end of theprepare_datasetstep. The lineself.next(self.generate_embeddings, foreach='hypers_sets')indicates that thegenerate_embeddingsstep will be created for all the combinations of parameters defined in theself.hypers_setsvariable. - The
join_runsstep is required (it doesn't have to be any particular name, but the "join" step concept needs to exist) to merge all of the artifacts produced in the parallelgenerate_embeddingssteps. Notice this function receives theinputsargument, containing results for each of the embeddings evaluated. This step includes thecardthat organizes the results of the parameter combinations and the validation metric scores they produced.
from metaflow import FlowSpec, step, S3, Parameter, current, card
from metaflow.cards import Markdown, Table
import os
import json
import time
from random import choice
class RecSysTuningFlow(FlowSpec):
IS_DEV = Parameter(
name='is_dev',
help='Flag for dev development, with a smaller dataset',
default='1'
)
KNN_K = Parameter(
name='knn_k',
help='Number of neighbors we retrieve from the vector space',
default='100'
)
@step
def start(self):
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("username: %s" % current.username)
if self.IS_DEV == '1':
print("ATTENTION: RUNNING AS DEV VERSION - DATA WILL BE SUB-SAMPLED!!!")
self.next(self.prepare_dataset)
@step
def prepare_dataset(self):
"""
Get the data in the right shape by reading the parquet dataset
and using duckdb SQL-based wrangling to quickly prepare the datasets for
training our Recommender System.
"""
import duckdb
import numpy as np
con = duckdb.connect(database=':memory:')
con.execute("""
CREATE TABLE playlists AS
SELECT *,
CONCAT (user_id, '-', playlist) as playlist_id,
CONCAT (artist, '|||', track) as track_id,
FROM 'cleaned_spotify_dataset.parquet'
;
""")
con.execute("SELECT * FROM playlists LIMIT 1;")
print(con.fetchone())
tables = ['row_id', 'user_id', 'track_id', 'playlist_id', 'artist']
for t in tables:
con.execute("SELECT COUNT(DISTINCT({})) FROM playlists;".format(t))
print("# of {}".format(t), con.fetchone()[0])
sampling_cmd = ''
if self.IS_DEV == '1':
print("Subsampling data, since this is DEV")
sampling_cmd = ' USING SAMPLE 1 PERCENT (bernoulli)'
dataset_query = """
SELECT * FROM
(
SELECT
playlist_id,
LIST(artist ORDER BY row_id ASC) as artist_sequence,
LIST(track_id ORDER BY row_id ASC) as track_sequence,
array_pop_back(LIST(track_id ORDER BY row_id ASC)) as track_test_x,
LIST(track_id ORDER BY row_id ASC)[-1] as track_test_y
FROM
playlists
GROUP BY playlist_id
HAVING len(track_sequence) > 2
)
{}
;
""".format(sampling_cmd)
con.execute(dataset_query)
df = con.fetch_df()
print("# rows: {}".format(len(df)))
print(df.iloc[0].tolist())
con.close()
train, validate, test = np.split(
df.sample(frac=1, random_state=42),
[int(.7 * len(df)), int(.9 * len(df))])
self.df_dataset = df
self.df_train = train
self.df_validate = validate
self.df_test = test
print("# testing rows: {}".format(len(self.df_test)))
self.hypers_sets = [json.dumps(_) for _ in [
{ 'min_count': 5, 'epochs': 30, 'vector_size': 48, 'window': 10, 'ns_exponent': 0.75 },
{ 'min_count': 10, 'epochs': 30, 'vector_size': 48, 'window': 10, 'ns_exponent': 0.75 }
]]
# we train K models in parallel, depending how many configurations of hypers
# we set - we generate K set of vectors, and evaluate them on the validation
# set to pick the best combination of parameters!
self.next(self.generate_embeddings, foreach='hypers_sets')
def predict_next_track(self, vector_space, input_sequence, k):
"""
Given an embedding space, predict best next song with KNN.
Initially, we just take the LAST item in the input playlist as the query item for KNN
and retrieve the top K nearest vectors (you could think of taking the smoothed average embedding
of the input list, for example, as a refinement).
If the query item is not in the vector space, we make a random bet. We could refine this by taking
for example the vector of the artist (average of all songs), or with some other strategy (sampling
by popularity).
For more options on how to generate vectors for "cold items" see for example the paper:
https://dl.acm.org/doi/10.1145/3383313.3411477
"""
query_item = input_sequence[-1]
if query_item not in vector_space:
query_item = choice(list(vector_space.index_to_key))
return [_[0] for _ in vector_space.most_similar(query_item, topn=k)]
def evaluate_model(self, _df, vector_space, k):
lambda_predict = lambda row: self.predict_next_track(vector_space, row['track_test_x'], k)
_df['predictions'] = _df.apply(lambda_predict, axis=1)
lambda_hit = lambda row: 1 if row['track_test_y'] in row['predictions'] else 0
_df['hit'] = _df.apply(lambda_hit, axis=1)
hit_rate = _df['hit'].sum() / len(_df)
return hit_rate
@step
def generate_embeddings(self):
"""
Generate vector representations for songs, based on the Prod2Vec idea.
For an overview of the algorithm and the evaluation, see for example:
https://arxiv.org/abs/2007.14906
"""
from gensim.models.word2vec import Word2Vec
self.hyper_string = self.input
self.hypers = json.loads(self.hyper_string)
track2vec_model = Word2Vec(self.df_train['track_sequence'], **self.hypers)
print("Training with hypers {} is completed!".format(self.hyper_string))
print("Vector space size: {}".format(len(track2vec_model.wv.index_to_key)))
test_track = choice(list(track2vec_model.wv.index_to_key))
print("Example track: '{}'".format(test_track))
test_vector = track2vec_model.wv[test_track]
print("Test vector for '{}': {}".format(test_track, test_vector[:5]))
test_sims = track2vec_model.wv.most_similar(test_track, topn=3)
print("Similar songs to '{}': {}".format(test_track, test_sims))
self.validation_metric = self.evaluate_model(
self.df_validate,
track2vec_model.wv,
k=int(self.KNN_K))
print("Hit Rate@{} is: {}".format(self.KNN_K, self.validation_metric))
self.track_vectors = track2vec_model.wv
self.next(self.join_runs)
@card(type='blank', id='hyperCard')
@step
def join_runs(self, inputs):
"""
Join the parallel runs and merge results into a dictionary.
"""
self.all_vectors = { inp.hyper_string: inp.track_vectors for inp in inputs}
self.all_results = { inp.hyper_string: inp.validation_metric for inp in inputs}
print("Current result map: {}".format(self.all_results))
self.best_model, self_best_result = sorted(self.all_results.items(), key=lambda x: x[1], reverse=True)[0]
print("The best validation score is for model: {}, {}".format(self.best_model, self_best_result))
self.final_vectors = self.all_vectors[self.best_model]
self.final_dataset = inputs[0].df_test
current.card.append(Markdown("## Results from parallel training"))
current.card.append(
Table([
[inp.hyper_string, inp.validation_metric] for inp in inputs
])
)
# next, test the best model on unseen data, and report the final Hit Rate as
# our best point-wise estimate of "in the wild" performance
self.next(self.model_testing)
@step
def model_testing(self):
"""
Test the generalization abilities of the best model by running predictions
on the unseen test data.
We report a quantitative point-wise metric, hit rate @ K, as an initial implementation. However,
evaluating recommender systems is a very complex task, and better metrics, through good abstractions,
are available, i.e. https://reclist.io/.
"""
self.test_metric = self.evaluate_model(
self.final_dataset,
self.final_vectors,
k=int(self.KNN_K))
print("Hit Rate@{} on the test set is: {}".format(self.KNN_K, self.test_metric))
self.next(self.end)
@step
def end(self):
"""
Just say bye!
"""
print("All done\n\nSee you, space cowboy\n")
return
if __name__ == '__main__':
RecSysTuningFlow()
3Run your flow
python recsys_tuning_flow.py run --is_dev 0
Now you have a flow that will not only help you operationalize the training of your model but can help you train many variations in parallel while seamlessly tracking the results in a variety of modes. Stay tuned for the next episode where you will learn to use Metaflow's Client API to access the models you trained in Python code.