




Authors

MLOps for Foundation Models: Whisper and Metaflow
October 21, 2022
Whisper is a new open-source system for audio-to-text and text-to-text learning tasks by OpenAI. We show how to use large models like Whisper in a production-grade workflow with Metaflow. You will learn how to use Metaflow to overcome the general challenges of working with large models including: scaling to cloud GPUs, moving code to highly-available workflow orchestrators, and more.
To run the example that guides this post in the cloud, open your sandbox using the following link:
YouTubeVideoTranscription Flow
Try it out directly in your browser
Open in Sandbox
from nlp_utils import Mixin
from metaflow import FlowSpec, step, Parameter, kubernetes, card, current
import os
class YouTubeVideoTranscription(FlowSpec, Mixin):
URL = Parameter(
"url",
type=str,
default=os.getenv(
"DEFAULT_VIDEO_URL", "https://www.youtube.com/watch?v=OH0Y_DUZu4Y"
),
help="""The watch url of a YouTube video (starting with https://www.youtube.com/watch),
or a url to a Playlist (starting with https://www.youtube.com/playlist).""",
)
URL_FILENAME = Parameter(
"urls",
type=str,
default=os.getenv("MANY_URL_FILENAME_DEFAULT", ""),
help="A file containing a list of watch urls for YouTube videos.",
)
MODEL_TYPE = Parameter(
"model",
type=str,
default=os.getenv("DEFAULT_MODEL_TYPE", "tiny"),
help="""The size of the Whisper variant.
See the current options at https://github.com/openai/whisper/blob/main/whisper/__init__.py#L17-L27""",
)
TITLE = Parameter(
"title",
type=str,
default="Metaflow",
help="The title to be displayed at the top the post processing step's card.",
)
MIN_COUNT_W2V = Parameter(
"min-ct",
type=int,
default=1,
help="The amount of occurences of a term to be included in word2vec embedding visualization.",
)
@step
def start(self):
from pytube import Playlist, YouTube
from pytube.exceptions import LiveStreamError
from youtube_utils import make_task
if self.URL_FILENAME == os.getenv("MANY_URL_FILENAME_DEFAULT", ""):
# single video watch urls look like:
# 'https://www.youtube.com/watch?v=<VIDEO ID>'
if self.URL.startswith("https://www.youtube.com/watch"):
_pending_transcription_task = [make_task(self.URL, self.MODEL_TYPE)]
# playlist urls look like:
# 'https://www.youtube.com/playlist?list=<PLAYLIST ID>'
elif self.URL.startswith("https://www.youtube.com/playlist"):
_pending_transcription_task = [
make_task(video_url, self.MODEL_TYPE)
for video_url in Playlist(self.URL)
]
else: # user passed a list of urls
_pending_transcription_task = []
with open(self.URL_FILENAME, "r") as file:
for url_line in file:
if url_line.strip().startswith("https://www.youtube.com/playlist"):
_pending_transcription_task.extend(
[
make_task(video_url, self.MODEL_TYPE)
for video_url in Playlist(url_line.strip())
]
)
else:
_pending_transcription_task.append(
make_task(url_line.strip(), self.MODEL_TYPE)
)
# data validation
_live_streams = []
for _transcription_task in _pending_transcription_task:
try:
audio = YouTube(_transcription_task.url).streams.get_audio_only()
audio.download(
output_path=self.AUDIO_OUTPUT, filename=_transcription_task.filename
)
audio_filename = self.AUDIO_OUTPUT + _transcription_task.filename
except LiveStreamError:
msg = "{} is a coming live stream, removing it from the pending transcription list."
print(msg.format(_transcription_task.url))
_live_streams.append(_transcription_task)
self.pending_transcription_task = []
for _task in _pending_transcription_task:
if _task not in _live_streams:
self.pending_transcription_task.append(_task)
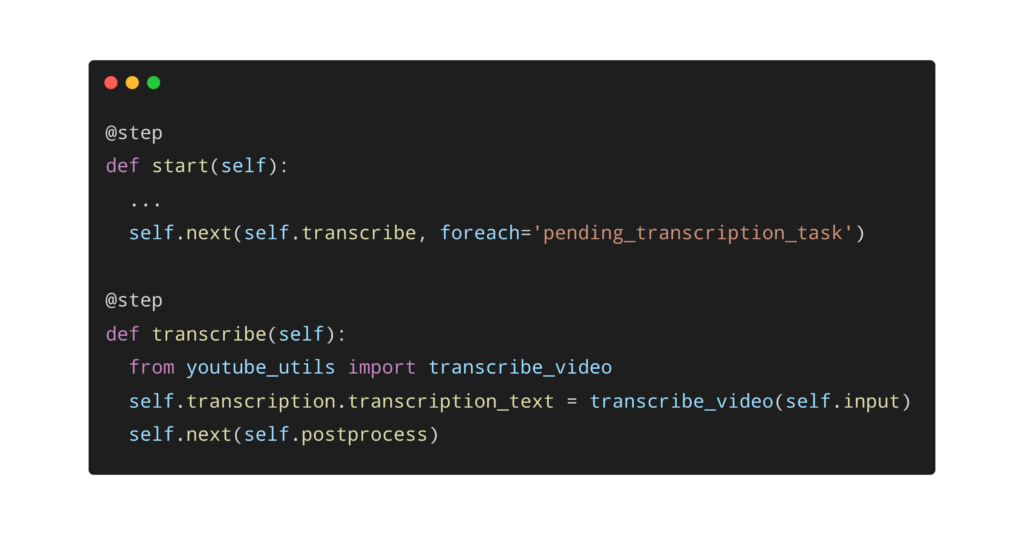
self.next(self.transcribe, foreach="pending_transcription_task")
@kubernetes(cpu=3, memory=12288, image="registry.hub.docker.com/eddieob/whisper")
@step
def transcribe(self):
self.transcription = self.input
self.transcription_text = self.transcribe_video(self.transcription)
self.next(self.postprocess)
@card
@step
def postprocess(self, transcribe_steps):
import pandas as pd
from metaflow.cards import Image, Table, Markdown
import matplotlib.pyplot as plt
# gather documents
self.documents = []
task_data = []
for _step in transcribe_steps:
task_data.append(_step.transcription.dict())
self.documents.append(_step.transcription_text)
self.results = pd.DataFrame(task_data)
_joined_document = " ".join(document.strip() for document in self.documents)
# create visualizations
self.fig, ax = plt.subplots(1, 2, figsize=(16, 8))
self.fig.suptitle(
"{} - Wordcloud and Word2vec Embedding".format(self.TITLE), fontsize=32
)
_ = self.get_wordcloud_figure(document=_joined_document, fig=self.fig, ax=ax[0])
_ = self.get_w2v_figure(document=_joined_document, fig=self.fig, ax=ax[1])
current.card.append(Table([[Image.from_matplotlib(self.fig)]]))
# show transcription in Metaflow card
md = [Markdown("# Transcriptions from Whisper {}".format(self.MODEL_TYPE))]
for i, document in enumerate(self.documents):
md.extend(
[
Markdown("## *Video Name:* {}".format(task_data[i]["title"])),
Markdown(document),
]
)
current.card.extend(md)
self.next(self.end)
@step
def end(self):
msg = """
Fetch the run object from a notebook or script using:
from metaflow import Flow
run = Flow('YouTubeVideoTranscription').latest_successful_run
This flow recorded metadata for {} transcription(s) in the run.data.results dataframe.
You can access the list of transcriptions using run.data.documents.
"""
print(msg.format(self.results.shape[0]))
if __name__ == "__main__":
YouTubeVideoTranscription()What is Whisper?
Whisper is the latest open-source system from OpenAI. It performs near or above state-of-the-art on several audio-to-text and text-to-text learning tasks. The model is a sequence-to-sequence transformer trained to do many speech tasks at once on 680,000 hours of audio data. You can read more about the Whisper model architecture and training process in the paper.
Whisper follows recent foundation models like BLOOM, Stable Diffusion, and many other impressive AI models that have been open-sourced in the 2020s. You can read more about using Metaflow to scale Stable Diffusion in our recent article.
ModelNumber of ParametersDomainTypeSourceBERT110Mgeneral NLPTransformerGoogleStable Diffusion890Mtext-to-imageDiffusionStability AIWhisper Large1.5Bspeech-to-textTransformerOpenAIImagen4.5Btext-to-imageDiffusionGoogleDall-E 25Btext-to-imageDiffusionOpenAIDall-E12Btext-to-imageDiffusionOpenAIGPT-3175Bgeneral NLPTransformerOpenAIOPT-175B175Bgeneral NLPTransformerMeta AIBLOOM176Bgeneral NLPTransformerHugging Face
One useful aspect of Whisper to leverage is that there are five sizes of the model trained (this is a common characteristic of foundation models). Having small versions available makes it easy to get started working with Whisper in any Python code or terminal. This post will show you how to leverage these properties of Whisper by pairing them with Metaflow. You’ll write one workflow to run the small models locally, use larger versions of the model efficiently by leveraging the cloud, as well as making the whole workflow production-ready through highly available workflow orchestration. Note that Whisper is still an experimental model, and that you should take care to study its failure modes before using Whisper in production systems.
Getting Started with Whisper
All code referenced in this post is accessible here. You should be able to run everything on a laptop with the tiny or base Whisper model, and potentially the larger model versions depending on your machine. You can install local dependencies using Miniconda and instructions in the repository if you want to run the code as you read this post. If desired, you can also follow instructions in the repository to run steps of the YouTubeVideoTranscription flow on cloud resources using your Metaflow deployment.
To get started with Whisper on a laptop or your own infrastructure, you can install the latest package using pip:
pip install git+https://github.com/openai/whisper.gitIf you do not already have it, you will need ffmpeg installed on your machine for Whisper to work. See these instructions to install on your machine.
One benefit of using Whisper with Metaflow is that you can use Metaflow to manage compute environments with dependencies like ffmpeg packaged. This saves development time when moving between compute environments, whether they are local or remote.
After installing Whisper you can use it as a command line tool or Python module. For example, this Python snippet shows how to transcribe any audio.mp3 file using the tiny version of Whisper:
import whisper
model = whisper.load_model('tiny')
result = model.transcribe('audio.mp3')
print(result['text'])Let’s use the pytube package to extend this code. The transcribe_video function will extract the audio of a YouTube video using pytube and then transcribe the speech using Whisper:
def transcribe_video(url, output_path = './', filename = 'audio.mp3'):
import whisper
from pytube import YouTube
audio = YouTube(url).streams.get_audio_only()
audio.download(output_path, filename)
model = whisper.load_model('tiny')
result = model.transcribe(output_path + filename)
return result['text']In eight lines of Python code, you have a function to transcribe any YouTube video! You can use the function from a notebook or Python script to make the magic happen. Let’s transcribe the famous Charlie bit my finger! video:
url = 'https://www.youtube.com/watch?v=0EqSXDwTq6U'
transcription = transcribe_video(url)
print(transcription)I’m pretty upset. Go! Ha ha! Charlie! Charlie bit me! I don’t see you. I don’t see you. Ha ha! Oh! Ouch! Ouch! Ouch! You’re out! Charlie! Ouch! Charlie! That really hurt! No, Charlie bit me! And that really hurt Charlie. I’m still hurt Charlie.
Whisper tiny interpreting the Charlie bit my finger! video
The tiny model achieves decent results quickly, yet the transcription quality is lacking. To improve the model’s performance you can change the model_type to one of the bigger versions of Whisper.
Effects of Whisper Model Size
The CLI and Python module for Whisper make changing between these model sizes one argument. Having various model sizes is relevant to MLOps because it affords easy ways to evaluate and compare the performance and cost of different models. Developers can then more easily experiment with the trade-off between infrastructure costs required to operate bigger models with the benefits of more precise models.
In the case of Whisper, there are significant performance improvements as the model size increases. This increases the importance of being able to experiment and study the size and performance trade-off across environments.
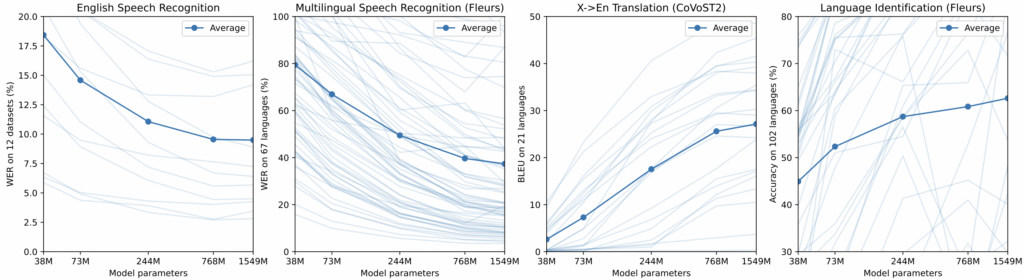
For a specific inference example, compare these two Whisper-generated transcriptions of “Fly Me to the Moon” by Frank Sinatra.
Running the tiny Whisper model with the YouTubeTranscriptionFlow
python youtube_video_transcriber.py run \
--url 'https://www.youtube.com/watch?v=ZEcqHA7dbwM' \
--model tinyLet me play among the stars. Let me see what spring is like on. As you put a mask, in other words, hold my hand. In other words, baby kiss me. Fill my heart with song and let me sing forevermore. You are all I long for, all I worship and the dawn. In other words, please be true. In other words, I love you. Fill my heart with song and let me sing forevermore. You are all I long for, all I worship and the dawn. In other words, please be true. In other words, in other words, I love you. You.
Whisper tiny transcribing “Fly Me to the Moon”
Running the large Whisper model with the YouTubeTranscriptionFlow
python youtube_video_transcriber.py run \
--url 'https://www.youtube.com/watch?v=ZEcqHA7dbwM' \
--model largeFly me to the moon, let me play among the stars Let me see what spring is like on Jupiter and Mars In other words, hold my hand In other words, baby, kiss me Fill my heart with song and let me sing forever more You are all I long for, all I worship and adore In other words, please be true In other words, I love you Fill my heart with song and let me sing forever more You are all I long for, all I worship and adore In other words, please be true In other words, in other words, I love you.
Whisper large transcribing “Fly Me to the Moon”
Whisper Operations with Metaflow
Metaflow and Whisper make it easy to develop workflows and test with smaller, cheaper models locally and then run an experiment or move to production with a larger, better optimized model on whatever hardware it requires. In the case of Whisper, the difference in the number of parameters between the large and tiny models is about 50-60x. This makes it crucial from a cost-effectiveness point-of-view to iterate on workflows with the tiny version and only scale to the large version when necessary. These benefits come together to increase the focus of the developer on building expertise around the data, iterating quickly, and designing experiments; while Metaflow ensures they have access to infrastructure and that workflows are:
- scalable horizontally and vertically – including to access GPUs in the cloud,
- able to be scheduled and triggered on production-grade workflow orchestrators like Argo Workflows or AWS Step Functions,
- versioned,
- reproducible,
- easy to visualize,
- and most importantly can be used in a production-grade, highly-available application.
To highlight an application of Whisper, we set up this repository to help you transcribe YouTube videos. Depending on your use cases, you can readily adapt the flow code for a transcription and/or translation service in the 96 languages Whisper has learned.
Like all Metaflow code, the workflow is defined as a directed acyclic graph. It consists of the following steps:
startprocesses the Flow parameter values to create a list calledself.pending_transcription_task. This list is what determines theforeachcall.transcriberuns inference with Whisper for each task in the list created during thestartstep.postprocesscollects results in a dataframe. It also creates a word cloud and embeds the text of concatenated transcriptions using word2vec. This is then visualized in 2-dimensions using PCA.endprints to console how many transcriptions were recorded.
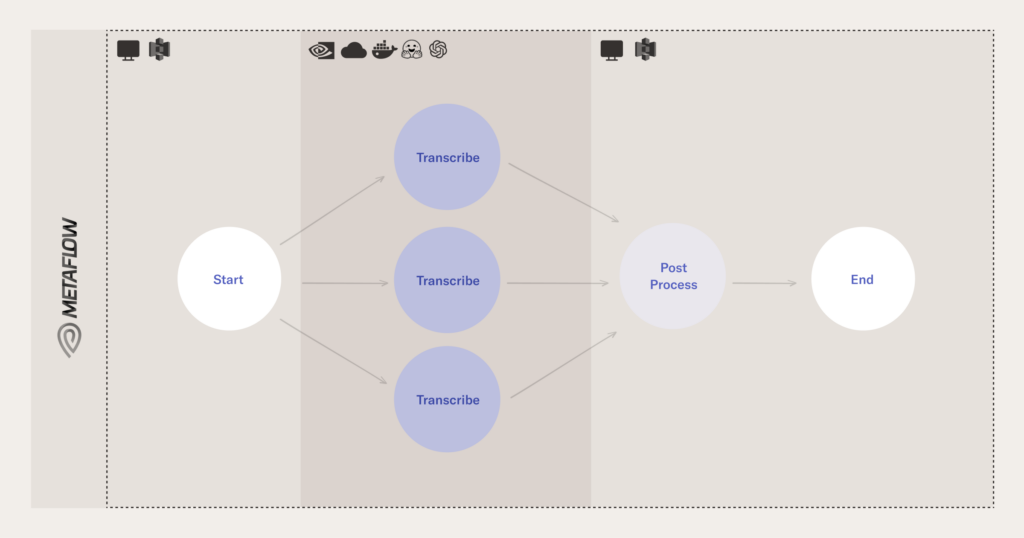
Run the Code
You can use the flow to transcribe one video, each video in a playlist, or a file with a list of video URLs in it. When you pass multiple videos via a playlist URL or file the flow will run each transcribe task in parallel.
In an example where GPUs provided us significant speedup, we used this workflow to transcribe a number of Fireside Chats, an interview series with ML experts that is hosted by Outerbounds. We transcribed each episode of the Fireside Chat using the following command to run the YouTubeVideoTranscription flow:
python youtube_video_transcriber.py run \
--model large \
--min-ct 25 \
--title 'Fireside Chats' \
--url 'https://www.youtube.com/playlist?list=PLUsOvkBBnJBeL8tsNGMdDKQjjOdU29sME'Here is how the largest and smallest Whisper variants performed on a small section of one Fireside chat:
Whisper tinyWhisper largeAudio‘I feel like we need some elevated music or something, but I my beatboxing skills on up to scratch.’‘I feel like we need some elevator music or something. My beatboxing skills aren't up to scratch.’Fireside chat #1: How to Produce Sustainable Business Value with Machine Learning at 1:20
Whisper in the Cloud
To produce Fireside Chat transcriptions with Whisper we used Metaflow’s AWS Batch integration to run the tasks on a P3 instance with 16 GB of memory, 1 GPU, and 8 CPUs. Metaflow makes these settings easy to configure through decorators like @batch and @kubernetes:
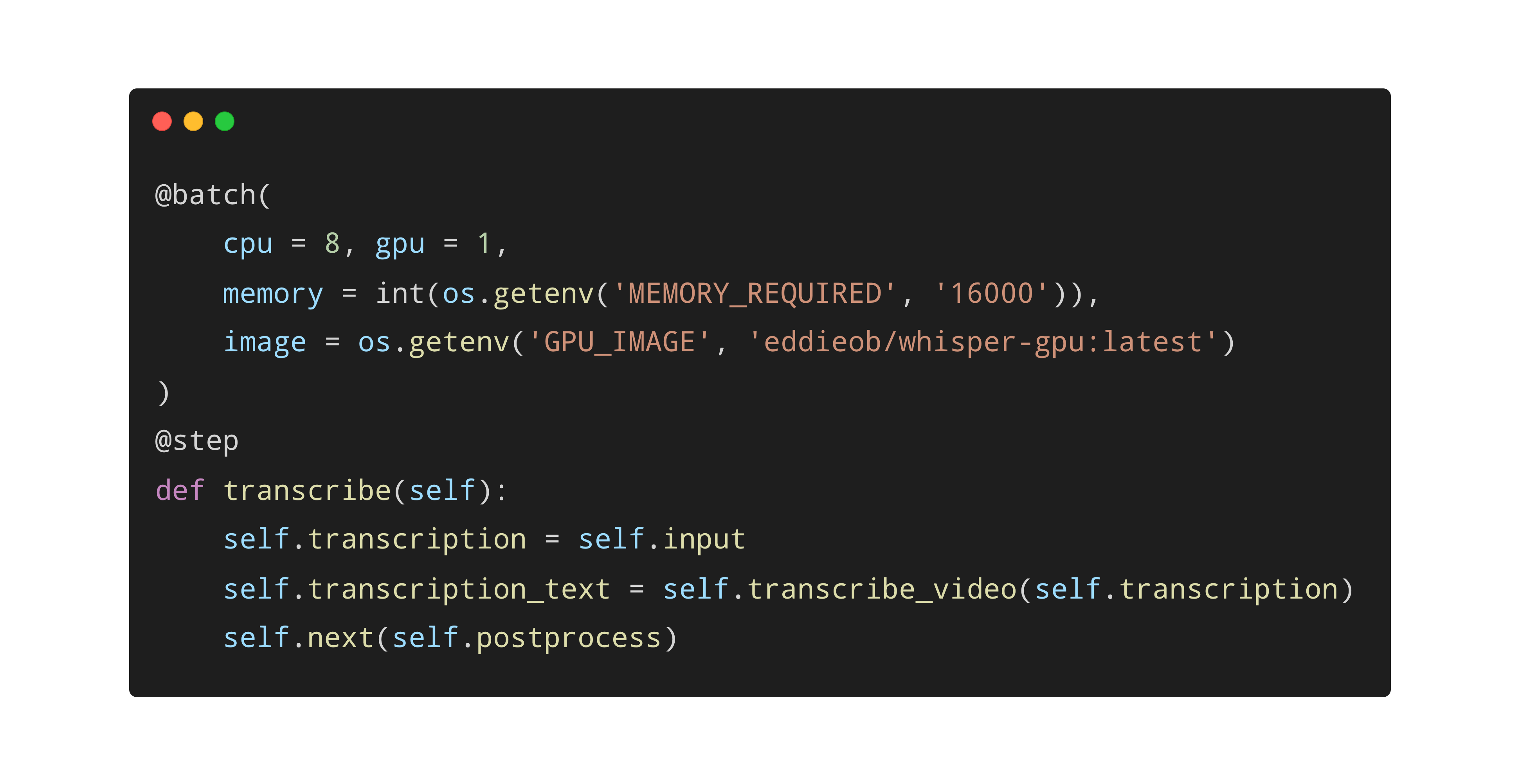
The total time to transcribe all five Fireside chats – totaling about 6½ hours of video – was about 30 minutes, at least an order of magnitude faster than running locally with the large model.
Also, by using the resume command you can speed up your development cycles by avoiding repeated computation of expensive steps. This is beneficial in many machine learning development contexts, where it is desirable to develop downstream steps of a flow iteratively without rerunning earlier, expensive steps like transcribe.
Another dimension of MLOps that Metaflow helps with is moving data scientists’ workflows from the prototyping environment to a production orchestrator. Metaflow allows you to schedule and trigger flows with orchestrators like Argo and AWS Step Functions. Consider a scenario where you want to run a flow like YouTubeVideoTranscription on a daily cadence on Argo. What is the easiest way to move your Python code to the production environment and ensure it runs when you want? With Metaflow this only requires adding a @schedule decorator above the flow.
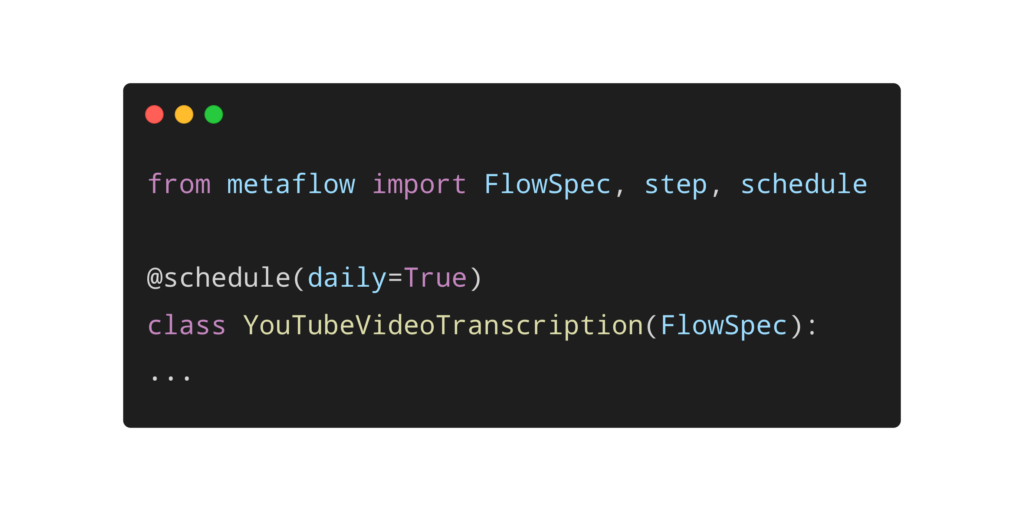
Then to run the flow reliably in production – without human supervision – you can deploy the flow to Argo:
python youtube_video_transcriber.py --with retry argo-workflows createStore, Visualize, and Access Results with Metaflow
Metaflow stores every value assigned to self in a common data store, such as S3 when deploying Metaflow on AWS. A shared data store makes results produced in one step accessible from steps that run in different compute environments. This enables Metaflow to automatically track and version variables measured during your flow’s runtime, regardless of the execution environment. Then you can inspect all results and intermediate states, such as transcriptions, easily in a notebook. In our example, these state variables include Whisper transcriptions. Writing your Metaflow code to leverage self enables access to the artifacts in a notebook or any Python script using the Metaflow Client API. This means we can now look up the transcriptions any time we want, and trust that Metaflow has them versioned in the data store!
In the postprocess step Metaflow also stored the text in a Metaflow card. You can see sample card output for YouTubeVideoTranscription here. After you run the flow, you can access cards associated with the postprocess step like this:
python youtube_video_transcriber.py card view postprocessAn added benefit of Metaflow for teams is that once the ML stack is shared, data scientists and engineers can easily generate and share notebooks, UI views, and cards with data produced in any tasks.
Conclusion
This post gave a quick overview of the key features of using Metaflow to power a modern foundation model like Whisper:
- It is easy to structure the whole application as a workflow, making the code more robust and readable.
- You can parametrize the workflow to use different sizes of the model, making it quick to develop the workflow without sacrificing the quality in production.
- You can leverage parallelism to speed up processing.
- The workflow can be readily executed in the cloud, including cloud GPU instances.
- You can deploy the workflow to run in production without human supervision with a single command.
If you would like to discuss any related topics in more detail with us, or if you want to get started with your own Metaflow deployment today, please join us in the #ask-metaflow channel on our community slack.

Start building today
Join our office hours for a live demo! Whether you're curious about Outerbounds or have specific questions - nothing is off limits.
We can't wait to meet you soon! Keep an eye out for a confirmation email with the deets.






