Why Should I Care About DAGs and Workflows in Data Science?
DAGs and Data Science Workflows
The complexity of machine learning and data science workflows can become complicated very quickly. To avoid a jungle of data pipelines and models, we need organizational principles for our workflows, and directed acyclic graphs aka DAGs have become a standard for this:
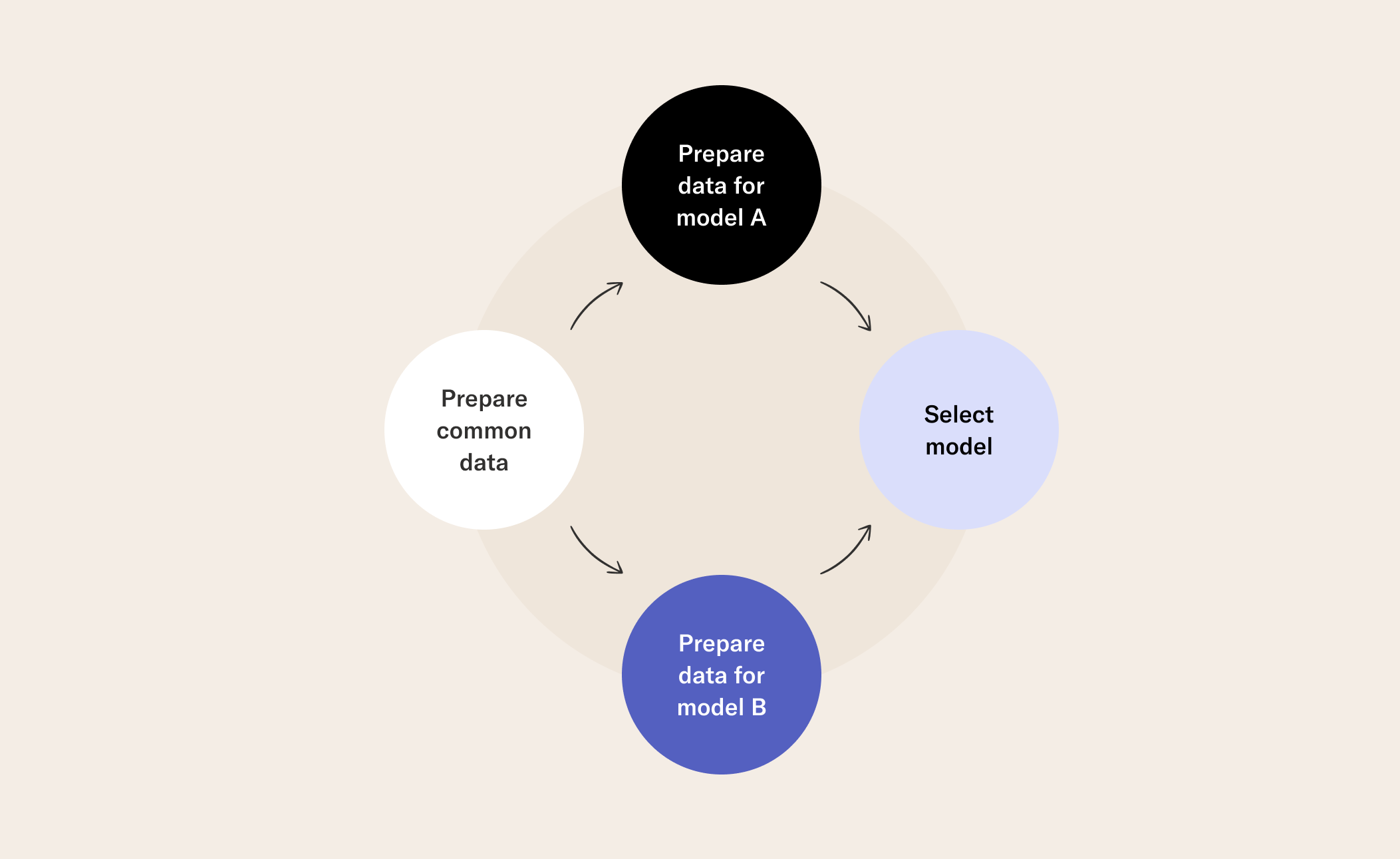
DAGs don’t only exist to tame complexity in the abstract, but are practically useful for several reasons:
They provide a common vocabulary of steps (the nodes) and transitions between them (the edges), which make it easier to write and understand nontrivial applications that are structured as DAGs. They both encourage and force us to be explicit about the order in which our workflows are executed. This is particularly useful when the order is anything more complicated than a linear flow, such as you would see in a notebook. Being explicit about the order of operations helps us to manage what could be a jungle of models and data pipelines. Using DAGs, we can signal when the order of operations doesn’t matter, such as when training independent models. We can parallelize these operations automatically, which is essential for performant code.
In summary, it is helpful to view DAGs as a language, not a programming language per se, but rather a formal construct for human-to-human communication. With DAGs, we can speak about complex sequences of operations in a concise and understandable manner.
What exactly is DAG?
It is worth defining explicitly what a DAG is: Directed Acyclic Graph may sound like a mouthful but you can think of DAGs as follows:
- A graph is a set of nodes connected by edges
- A graph is directed if each edge is an arrow (that is, pointing from one node to another)
- Acyclic means there are no cycles
The nodes of the DAG of a data science or machine learning workflow are the steps in your workflow, such as (but not limited to) getting your data, training a model, or choosing the best model, as in the DAG above. In the case of Metaflow, a step can contain any Python code - like a cell in a notebook. The edges tell you which step(s) follow from other steps and this is why they need to be directed. The reason we don’t want cycles may now be clear: we don’t want our pipelines to end up in infinite loops!
In an industrial setting, DAGs can be and often are far more complicated than the toy case above:
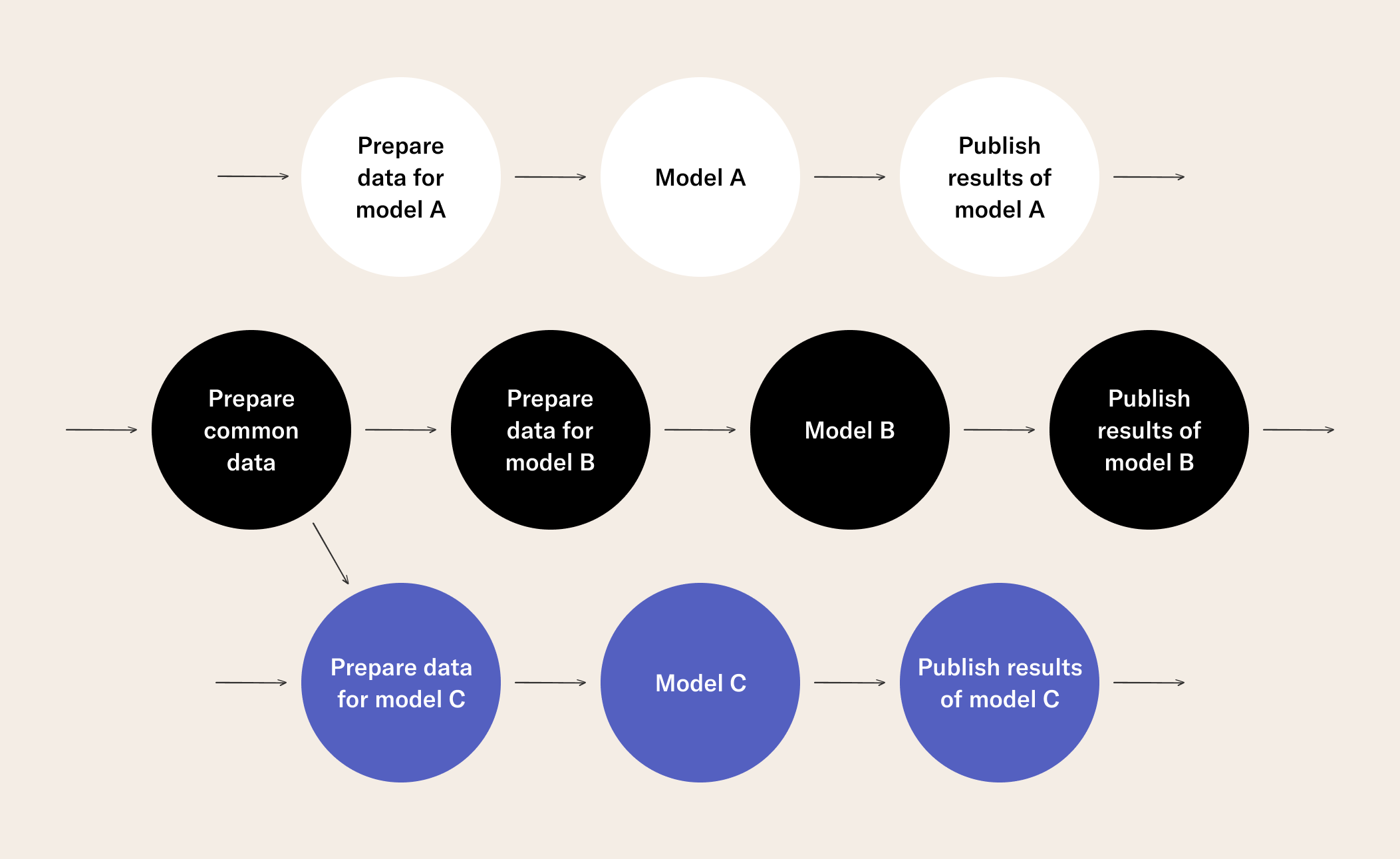
To be explicit here, DAGs are important in order to tame the complexity of machine learning workflows. There is an important corollary: not all data science workflows are DAGs, rather, DAGs are a particular type of workflow.
Orchestrating Workflows
Once we have a DAG, in order to perform our computation, we require a workflow orchestrator. The workflow orchestrator needs to perform a seemingly simple task: given a workflow or DAG definition, execute the steps defined by the graph in order. The orchestrator walks through the graph, sending each step to a separate compute layer that is responsible for executing the code contained in a step. For data-intense, distributed workflows a compute layer like Spark or Kubernetes can be used, whereas local processes suffice for prototyping. In contrast to prototyping, production workflows need to run automatically and reliably without human intervention. Workflow orchestrators play key roles in ensuring that production workflows, such as those training models and producing predictions regularly, execute in a scalable and highly available manner. Hence it makes sense to use a battle-hardened, proven system in production such as:
- Argo, a modern orchestrator that runs natively on Kubernetes
- Airflow, a popular open-source workflow orchestrator
- or a low-maintenance managed solution such as Google Cloud Composer or AWS Step Functions
Developing Workflows
Earlier, data science applications were often developed as independent modules which were glued together as a DAG afterwards, sometimes even by a separate team. As a result, it was hard to ensure that the whole application worked correctly end to end. Debugging workflow failures was often a painful experience as issues couldn’t be easily reproduced and fixed locally. A better approach is to consider the whole workflow as a key deliverable of a data science project, which is developed, tested, and deployed as a functional unit. When using a local orchestrator like the one provided by Metaflow, you can rapidly prototype end-to-end workflows almost as easily as how you develop code in a notebook. After the workflow works locally, it can be deployed to a production orchestrator without any changes in the code. After all, a data science workflow is just a DAG of steps that can be orchestrated by many different systems.
How do I?
Pass artifacts between steps in Metaflow flows
Schedule Metaflow flows on AWS Step Functions