

Helping scientists do better science
The immense impact of getting the right tools in front of the right people and building an educational (or wisdom) layer around them.
I’ve devoted a large part of my career so far to helping scientists do better science and I want to double down on that. This was initially a result of working in basic scientific research at the intersection of biology, physics, and mathematical modeling. At both the Max Planck Institute (MPI) for Cell Biology in Dresden, Germany (2011-2013), and Yale University (2013-2016), I worked in biology labs with experimentalists, who were generating increasingly large and complex datasets. I worked with world-class scientists who were ill-equipped to analyze their data and experiments, both in terms of a lack of statistical knowledge and a lack of good tooling (not to mention documentation and education!). At this time,
I started working in what was then known as the IPython notebook and realized the big wins that this type of literate programming could bring to research science. So while continuing research, I began teaching workshops on Practical statistical Inference for Research Scientists at both the MPI and Yale and discovered the immense impact you can have by getting the right tools in front of the right people and building an educational (or wisdom) layer around them.
Sufficiently jaded by academia (a conversation for another time), I joined a then early-stage startup called DataCamp, where we built online data science and machine learning courses. Here we worked to bring many data science tools, including the PyData stack and Tidyverse tools, to the masses, and I was fortunate enough to get experience in industrial data science, curriculum building, product management, marketing, and evangelism (such exposure is one pro of joining an early-stage startup).
I then joined Coiled as Head of Marketing and Evangelism, where we built a SaaS platform that helps data scientists scale their workflows to the cloud using the PyData stack and open source tools. In this job, I had many exciting opportunities, including the experience of building a business to help other organizations use OSS tools. This is worth taking a beat on. As Brian Granger, co-founder of Project Jupyter, once said to me:
Open-source software is undergoing a phase transition from having individual users in organizations to having large-scale institutional adoption.
At Coiled, I discovered first-hand how OSS is great at meeting the needs of individual scientists but also that institutions have more needs than OSS solves for and we need companies to support the OSS ecosystem so that it can meet these needs. So how important actually are tools? And why?
Data tools and wisdom layers
Practitioners need not only tools but access to education about the tools and how they can help them do their job.
There’s a paradox of tooling in that, although they’re just means to an end, tools are not only indispensable but need to be molded to both the needs and characteristics of their users. Take a coffee mug, for example:
- It needs to be able to hold coffee in it,
- It needs a handle or to be insulated enough so that the outside isn’t too hot, and
- Any handle needs to be comfortably grippable by a human hand.
Similarly, data science tools
- exist to serve a purpose, for example, pandas and dplyr are for data wrangling, and
- need to meet users where they are.

- Interoperating with other tools in the user’s stack,
- Reflecting the user’s mental model of the underlying computational and statistical processes (this is why some data scientists prefer the Tidyverse to parts of the PyData stack), and
- Being something your IT team will sign off on!
We require ergonomic tools that solve challenges we have when working with data. I’m convinced that one of the first big wins of pandas was allowing Pythonistas to convert CSVs into DataFrames. Moreover, a large part of the success of the PyData and Tidyverse tooling landscapes is due to the fact that it wasn’t built by computer scientists or software engineers, but by research scientists who needed tools yesterday to do their work.
But tooling itself isn’t enough, as I discovered in my time in research science: practitioners need not only tools but access to education about the tools and how they can help them do their job. As the tooling landscape grows and does so increasingly faster, this need becomes more pressing: good tooling requires a robust wisdom layer, including API references, tutorials, comprehensive examples, and a community of users excited to educate and help each other. One of the reasons scikit-learn has garnered such wide adoption is their fantastic documentation and it’s no surprise that they practice Documentation-Driven Development: the wisdom layer is a first-call citizen in their development process.
Why Metaflow? Why Outerbounds?
Building human-centric tools for data scientists and developers.
Having taught frameworks and built products that help (data) scientists with a lot of different aspects of their work, it became clear that, although there are wonderful tools for many parts of the pipeline, not only is the deployment story woefully incomplete (this is partially due by the tools being built by academic researchers), but we don’t even necessarily have shared mental models and canonical tools of what the statistical inference and ML deployment story should look like. To be clear, what we need is a shared paradigm (including tooling, workflows, division of labour, education, and more) for building and integrating data-powered software into business and decision-making systems.
To state the problem another way, many of the tools needed to build data-powered software that is integrated correctly into business and decision-making systems (while staying isolated from business logic so that errors don’t propagate) do exist but the last mile is missing. All the moving parts are there: you can work with your tabular data in pandas, .fit() and .predict() with scikit-learn, containerize with Docker and/or Kubernetes, and deploy a REST API on {insert cloud provider of choice here}. But all too often, the solution is developed ad hoc for each case in a brittle manner that won’t generalize. We’re finding ourselves at an historical stage analogous to the craft method of assembling cars by bringing all the parts to a single location, before the advent of interchangeable parts and the production line. There is a huge opportunity here to define not only what tooling and wisdom look like here, but also what division of labour looks like: what does an ML engineer do? What about an infrastructure engineer? What layers of the stack should a data scientist need to care about?
These are some of the things I’m really excited to work on, think about, and contribute to, which aligns well with the vision and worldview of open-source Metaflow that we are continuing to develop at Outerbounds. At Outerbounds, we think deeply about which layers of the stack data scientists should (and, for the most part, do) care about, so that they can do their most productive work:
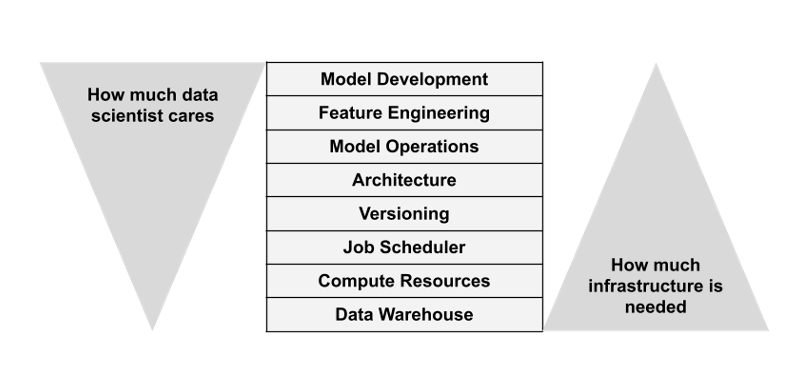
As always, my mission remains to help scientists do better science and Outerbounds is a place where I feel I can achieve this through a combination of OSS tool building, product development, education, and, in particular, interaction with the community and customers. These are a few thoughts about where we’re at as a discipline, what I’m excited about, and why I joined Outerbounds as Head of Developer Relations. If these ideas resonate with you, I’d love to hear from you! Take a look at our open positions or, if you just want to chat, join me and over 1000 data scientists and engineers on the Metaflow Community Slack 👋