Intermediate Recommender Systems: Episode 2
1What about feature engineering?
Once the data is available through SQL, we make use of Python for the final feature engineering. As is common in deep learning workflows, feature engineering is minimal, and here it is mostly bookkeeping for categorical variables. This bookkeeping helps us make sure the same exact transformations happen uniformly at training time and test time.
The build_workflow step uses NVTabular, an Nvidia library for tabular processing, to go from the "human-readable" datasets we had to the machine-optimized datasets we need for the deep learning model. Once the datasets are ready, we take notes of all the available IDs for both shoppers and items, as Merlin will use its own ids for training and predictions: the two mappings (self.id_2_user_id and self.id_2_item_id) will be crucial at the end to translate the model IDs into human-readable entities.
2What are we doing again? 🤷
Before going too deep into the model, let's recall the learning task. At test time, our model will receive a user identifier as the query and will be tasked with suggesting k (fashion) items that she is likely to buy. How are we going to accomplish this? The easiest way to build our intuition for this user-item model is to start from our previous recommender system tutorial, where we build a model to recommend new songs to continue a playlist. In that case, we built a latent space for the songs and "placed" the user based on what she was listening to - the goal is to represent user interests through the latest song in a list: recommendations then boiled down to a KNN search in that space - what is the most similar song to the one I'm listening now?
Our new model goes one step further, and builds an explicit representation for users, through their own embeddings: we call this architecture a two-tower model because it builds a latent space containing both users and items in parallel.
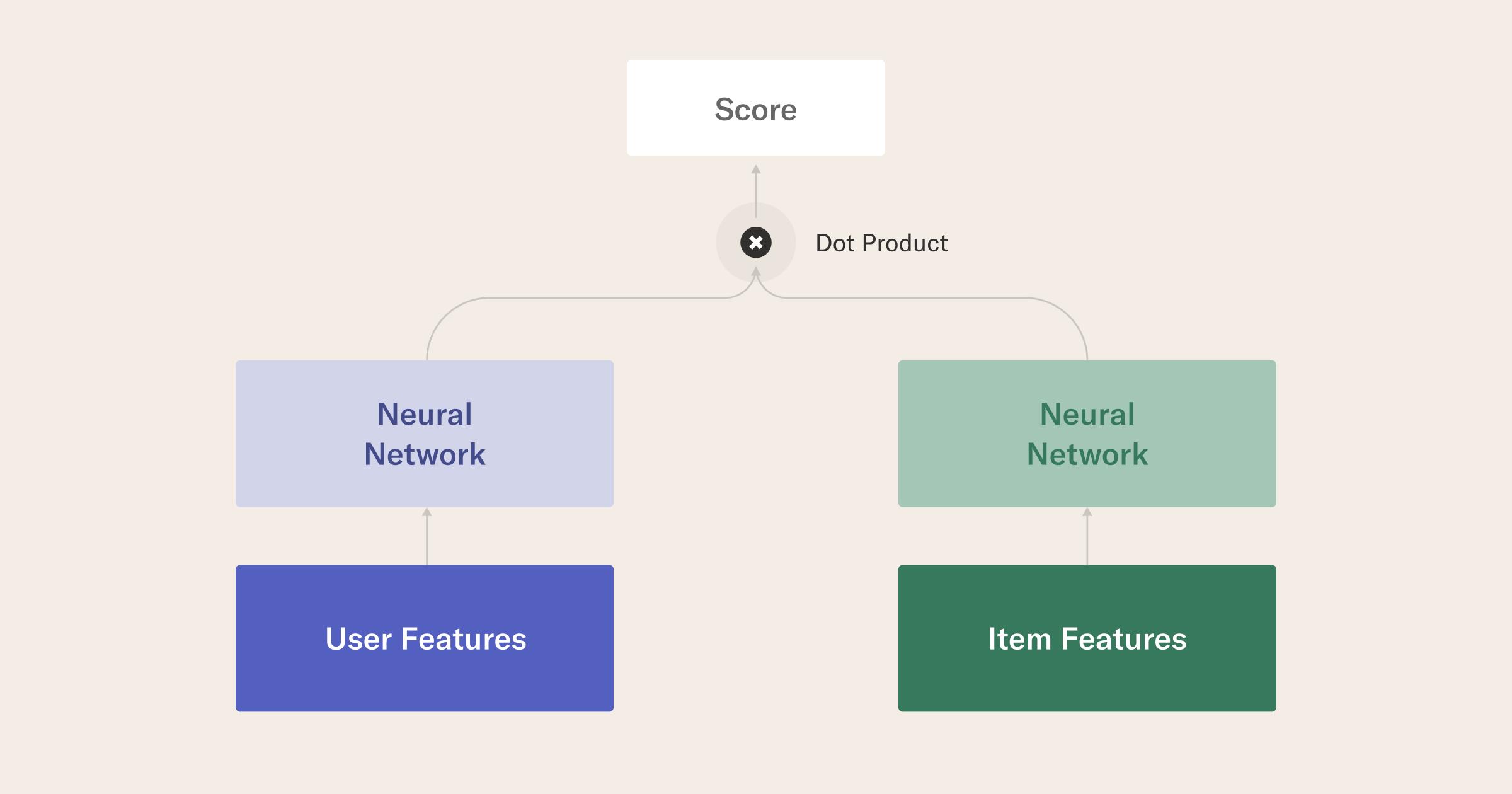
If the previous model could be trained "implicitly" by relying on the sequential nature of playlists, this model requires "explicit" feedback in the form of past transactions: when we train our network, user and item embeddings will adjust depends on the historical transactions that actually happened. Why go through the additional trouble? In a nutshell, two-tower models are very flexible, and allow us to incorporate user and item meta-data into our algorithm: thanks to deep learning's inherent flexibility, the model learns not only from purchases but also from the features associated with each transaction - how old was the shopper? How expensive was the item?
Implementing such a model seems complex - and it is! Thankfully, our friends at Nvidia Merlin are developing an open-source library for deep learning recommendations to allow us to implement this state-of-the-art architecture in few lines of code. The training code is remarkably straightforward for such a complex system, resembling the simplicity of Keras-like models. We define user and item schemas in parallel, including their embedding dimensions, and then fit the model on our training data set with standard information retrieval metrics: the model is evaluated on the validation set and then serialized and versioned.
The usage of sampling and the default number of epochs will allow the flow to run reasonably fast in a local or hybrid environment with no GPU. However, one of the most useful features of Metaflow when scaling large models is the ease of adding the gpu parameter to the @batch decorator, and benefit from the hardware speed-up. Like many data science scenarios, the same code will work on CPU or GPU setup in this tutorial, but to train the model to good performance levels a GPU is needed.
Finally, we introduce a Metaflow customization @magicdir. Since Merlin flows are parquet-based, intermediate computations are often stored as a series of files. The @magicdir decorator comes in handy dealing with this situation, allowing us to serialize and deserialize the merlin folder and seamlessly make sure these intermediate files are available to any step, local or remote!
3What does the model consider good? 🎯
There are two metrics that guide how model.compile is instantiated in the train_model step.
model.compile(
optimizer=opt,
metrics=[mm.RecallAt(int(self.TOP_K)), mm.NDCGAt(int(self.TOP_K))],)
Recall@K: Also known as HitRate@K. This measures whether a relevant/correct item is among the recommended items list.
Normalized Discounted Cumulative Gain (NDCG@K): NDCG accounts for rank, and is a more nuanced measure than hit rate. It is a normalization of a measure called Discounted Cumulative Gain (DCG). The G, gain, measures the relevance of an item our model can recommend to someone. Relevance labels can be whether a user actually interacted with an item or where an item placed in search rankings. DCG penalizes highly relevant items being placed at the bottom of the recommendation list.
4Train your model with Nvidia Merlin
from metaflow import FlowSpec, step, batch, Parameter, current
from custom_decorators import magicdir
import json
from datetime import datetime
class TrainMerlin(FlowSpec):
### MERLIN PARAMETERS ###
MODEL_FOLDER = Parameter(
name='model_folder',
help='Folder to store the model from Merlin, between steps',
default='merlin_model'
)
### DATA PARAMETERS ###
ROW_SAMPLING = Parameter(
name='row_sampling',
help='Row sampling: if 0, NO sampling is applied. Needs to be an int between 1 and 100',
default='1'
)
#NOTE: data parameters - we split by time, leaving the last two weeks for validation and tests
# The first date in the table is 2018-09-20
# The last date in the table is 2020-09-22
TRAINING_END_DATE = Parameter(
name='training_end_date',
help='Data up until this date is used for training, format yyyy-mm-dd',
default='2020-09-08'
)
VALIDATION_END_DATE = Parameter(
name='validation_end_date',
help='Data up after training end and until this date is used for validation, format yyyy-mm-dd',
default='2020-09-15'
)
### TRAINING PARAMETERS ###
VALIDATION_METRIC = Parameter(
name='validation_metric',
help='Merlin metric to use for picking the best set of hyperparameter',
default='recall_at_10'
)
N_EPOCHS = Parameter(
name='n_epoch',
help='Number of epochs to train the Merlin model',
default='1' # default to 1 for quick testing
)
TOP_K = Parameter(
name='top_k',
help='Number of products to recommend for a giver shopper',
default='10'
)
@step
def start(self):
"""
Start-up: check everything works or fail fast!
"""
# print out some debug info
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("username: %s" % current.username)
# we need to check if Metaflow is running with remote (s3) data store or not
from metaflow.metaflow_config import DATASTORE_SYSROOT_S3
print("DATASTORE_SYSROOT_S3: %s" % DATASTORE_SYSROOT_S3)
if DATASTORE_SYSROOT_S3 is None:
print("ATTENTION: LOCAL DATASTORE ENABLED")
# check variables and connections are working fine
assert int(self.ROW_SAMPLING)
# check the data range makes sense
self.training_end_date = datetime.strptime(self.TRAINING_END_DATE, '%Y-%m-%d')
self.validation_end_date = datetime.strptime(self.VALIDATION_END_DATE, '%Y-%m-%d')
assert self.validation_end_date > self.training_end_date
self.next(self.get_dataset)
@step
def get_dataset(self):
"""
Get the data in the right shape using duckDb, after the dbt transformation
"""
from pyarrow import Table as pt
import duckdb
# check if we need to sample - this is useful to iterate on the code with a real setup
# without reading in too much data...
_sampling = int(self.ROW_SAMPLING)
sampling_expression = '' if _sampling == 0 else 'USING SAMPLE {} PERCENT (bernoulli)'.format(_sampling)
# thanks to our dbt preparation, the ML models can read in directly the data without additional logic
query = """
SELECT
ARTICLE_ID,
PRODUCT_CODE,
PRODUCT_TYPE_NO,
PRODUCT_GROUP_NAME,
GRAPHICAL_APPEARANCE_NO,
COLOUR_GROUP_CODE,
PERCEIVED_COLOUR_VALUE_ID,
PERCEIVED_COLOUR_MASTER_ID,
DEPARTMENT_NO,
INDEX_CODE,
INDEX_GROUP_NO,
SECTION_NO,
GARMENT_GROUP_NO,
ACTIVE,
FN,
AGE,
CLUB_MEMBER_STATUS,
CUSTOMER_ID,
FASHION_NEWS_FREQUENCY,
POSTAL_CODE,
PRICE,
SALES_CHANNEL_ID,
T_DAT
FROM
read_parquet('filtered_dataframe.parquet')
{}
ORDER BY
T_DAT ASC
""".format(sampling_expression)
print("Fetching rows with query: \n {} \n\nIt may take a while...\n".format(query))
# fetch raw dataset
con = duckdb.connect(database=':memory:')
con.execute(query)
dataset = con.fetchall()
# convert the COLS to lower case (Keras does complain downstream otherwise)
cols = [c[0].lower() for c in con.description]
dataset = [{ k: v for k, v in zip(cols, row) } for row in dataset]
# debug
print("Example row", dataset[0])
self.item_id_2_meta = { str(r['article_id']): r for r in dataset }
# we split by time window, using the dates specified as parameters
# NOTE: we could actually return Arrow table directly, by then running three queries over
# a different date range (e.g. https://duckdb.org/2021/12/03/duck-arrow.html)
# For simplicity, we kept here the original flow compatible with warehouse processing
train_dataset = pt.from_pylist([row for row in dataset if row['t_dat'] < self.training_end_date])
validation_dataset = pt.from_pylist([row for row in dataset
if row['t_dat'] >= self.training_end_date and row['t_dat'] < self.validation_end_date])
test_dataset = pt.from_pylist([row for row in dataset if row['t_dat'] >= self.validation_end_date])
print("# {:,} events in the training set, {:,} for validation, {:,} for test".format(
len(train_dataset),
len(validation_dataset),
len(test_dataset)
))
# store and version datasets as a map label -> datasets, for consist processing later on
self.label_to_dataset = {
'train': train_dataset,
'valid': validation_dataset,
'test': test_dataset
}
# go to the next step for NV tabular data
self.next(self.build_workflow)
# NOTE: we use the magicdir package (https://github.com/outerbounds/metaflow_magicdir)
# to simplify moving the parquet files that Merlin needs / consumes across steps
@magicdir
@step
def build_workflow(self):
"""
Use NVTabular to transform the original data into the final dataframes for training,
validation, testing.
"""
from workflow_builder import get_nvt_workflow, read_to_dataframe
import pandas as pd
import nvtabular as nvt # pylint: disable=import-error
import itertools
# read dataset into frames
label_to_df = {}
for label, dataset in self.label_to_dataset.items():
label_to_df[label] = read_to_dataframe(dataset, label)
full_dataset = nvt.Dataset(pd.concat(list(label_to_df.values())))
# get the workflow and fit the dataset
workflow = get_nvt_workflow()
workflow.fit(full_dataset)
self.label_to_melin_dataset = {}
for label, _df in label_to_df.items():
cnt_dataset = nvt.Dataset(_df)
self.label_to_melin_dataset[label] = cnt_dataset
workflow.transform(cnt_dataset).to_parquet(output_path="merlin/{}/".format(label))
# store the mapping Merlin ID -> article_id and Merlin ID -> customer_id
user_unique_ids = list(pd.read_parquet('categories/unique.customer_id.parquet')['customer_id'])
items_unique_ids = list(pd.read_parquet('categories/unique.article_id.parquet')['article_id'])
self.id_2_user_id = { idx:_ for idx, _ in enumerate(user_unique_ids) }
self.id_2_item_id = { idx:_ for idx, _ in enumerate(items_unique_ids) }
# sets of hypers
self.LEARNING_RATE = 0.05
self.BATCH_SIZE = 4096
self.next(self.train_model)
@batch(
gpu=1,
memory=24000,
image='public.ecr.aws/outerbounds/merlin-reasonable-scale:22.11-latest'
)
@magicdir
@step
def train_model(self):
"""
Train models in parallel and store artifacts and validation KPIs for downstream consumption.
"""
import hashlib
import merlin.models.tf as mm # pylint: disable=import-error
from merlin.io.dataset import Dataset # pylint: disable=import-error
from merlin.schema.tags import Tags # pylint: disable=import-error
import tensorflow as tf # pylint: disable=import-error
train = Dataset('merlin/train/*.parquet')
valid = Dataset('merlin/valid/*.parquet')
print("Train dataset shape: {}, Validation: {}".format(
train.to_ddf().compute().shape,
valid.to_ddf().compute().shape
))
# train the model and evaluate it on validation set
user_schema = train.schema.select_by_tag(Tags.USER) # MERLIN WARNING
user_inputs = mm.InputBlockV2(user_schema)
query = mm.Encoder(user_inputs, mm.MLPBlock([128, 64]))
item_schema = train.schema.select_by_tag(Tags.ITEM)
item_inputs = mm.InputBlockV2(item_schema,)
candidate = mm.Encoder(item_inputs, mm.MLPBlock([128, 64]))
model = mm.TwoTowerModelV2(query, candidate)
opt = tf.keras.optimizers.Adagrad(learning_rate=self.LEARNING_RATE)
model.compile(
optimizer=opt,
run_eagerly=False,
metrics=[mm.RecallAt(int(self.TOP_K)), mm.NDCGAt(int(self.TOP_K))],)
model.fit(
train,
validation_data=valid,
batch_size=self.BATCH_SIZE,
epochs=int(self.N_EPOCHS))
self.metrics = model.evaluate(valid, batch_size=1024, return_dict=True)
print("\n\n====> Eval results: {}\n\n".format(self.metrics))
self.model_path = 'merlin/model/'
model.save(self.model_path)
print(f"Model saved to {self.model_path}!")
self.next(self.end)
def get_items_topk_recommender_model(
self,
train_dataset,
model,
k: int
):
from merlin.models.utils.dataset import unique_rows_by_features # pylint: disable=import-error
from merlin.schema.tags import Tags # pylint: disable=import-error
candidate_features = unique_rows_by_features(train_dataset, Tags.ITEM, Tags.ITEM_ID)
topk_model = model.to_top_k_encoder(candidate_features, k=k, batch_size=128)
topk_model.compile(run_eagerly=False)
return topk_model
@step
def end(self):
"""
Just say bye!
"""
print("All done\n\nSee you, recSys cowboy\n")
return
if __name__ == '__main__':
TrainMerlin()
5Run your flow ▶️
python train_merlin.py run
In this tutorial, you built on the data workflow from the previous lesson and extended your flow by adding a modeling step with Nvidia Merlin. You also learned about the two-tower model and a little bit about how it relates to our user-item recommendation task. In the next lesson, we will keep moving forward, improving model performance by adding hyperparameter tuning and model selection steps. See you there!