

In December, several of us from Metaflow and Outerbounds were fortunate enough to speak at PyData Global. In fact, collectively we presented 2 talks and 2 workshops! They are all online now so we wanted to collect them all in one place and say a few words about them:
- Orchestrating Generative AI Workflows to Deliver Business Value: How can you embed LLMs and foundation models into your pre-existing software stack? What are the fundamental building blocks emerging in LLM-based application design;
- Full-stack Machine Learning and Generative AI for Data Scientists: A hands-on, practical, Python-based introduction to taking models from prototype to production using OSS enterprise-grade software stack;
- Compute Anything With Metaflow: An overview of the changing landscape for compute and how open-source Metaflow allows Python developers to leverage various compute platforms easily;
- HPC in the Cloud: A tutorial highlighting how modern cloud frameworks can serve data scientists looking to build production-grade applications and can help them run HPC-style jobs like MPI programs and distributed AI training.
Collectively, these talks and tutorials give a practical overview of how you can build ML and AI systems today, particularly how to work the compute layer of the machine learning infrastructure stack.
Orchestrating Generative AI Workflows to Deliver Business Value
In this talk, you will learn:
- How you can embed LLMs and foundation models into your pre-existing software stack,
- How you can do so using Python, and
- Common failure modes, challenges, and solutions for GenAI models in production.
More details
In this talk, Hugo explored a framework for how data scientists can deliver value with Generative AI, including how you can embed LLMs and foundation models into your pre-existing software stack, how can you do so using open source Python, what changes about the production machine learning stack, and what remains the same.
Much of this talk emerged from Outerbounds's work with NLP expert Federico Bianchi from Stanford University. These are a few things Hugo covered, but check out the talk for more details!
- Introduction to Generative AI Workflows: How can you orchestrate generative AI workflows and what are the challenges in building machine learning software compared to traditional software?
- Components of Machine Learning Software Stack: Traditional software involves a software engineer and a reliable system producing correct results. In contrast, machine learning introduces data, machine learning models, and the role of a data scientist with distinct skills.
- Building Blocks of Generative AI: The key building blocks are data, models, and code, which need to interact through computation. As generative AI becomes more computationally intensive, it will be crucial for you to leverage cloud resources and orchestration.
- Importance of Versioning and Deployment: With models built by data scientists, versioning of code, data, and models becomes essential. Deployment involves various methods such as setting up APIs, batch inference, or generating slide decks for executives.
- Generative AI Challenges and Considerations: Transitioning from machine learning to generative AI brings challenges in handling diverse data types like natural language and images. You'll discover the importance of considering risks, costs, and versioning when adopting AI vendor APIs and open-source foundation models.
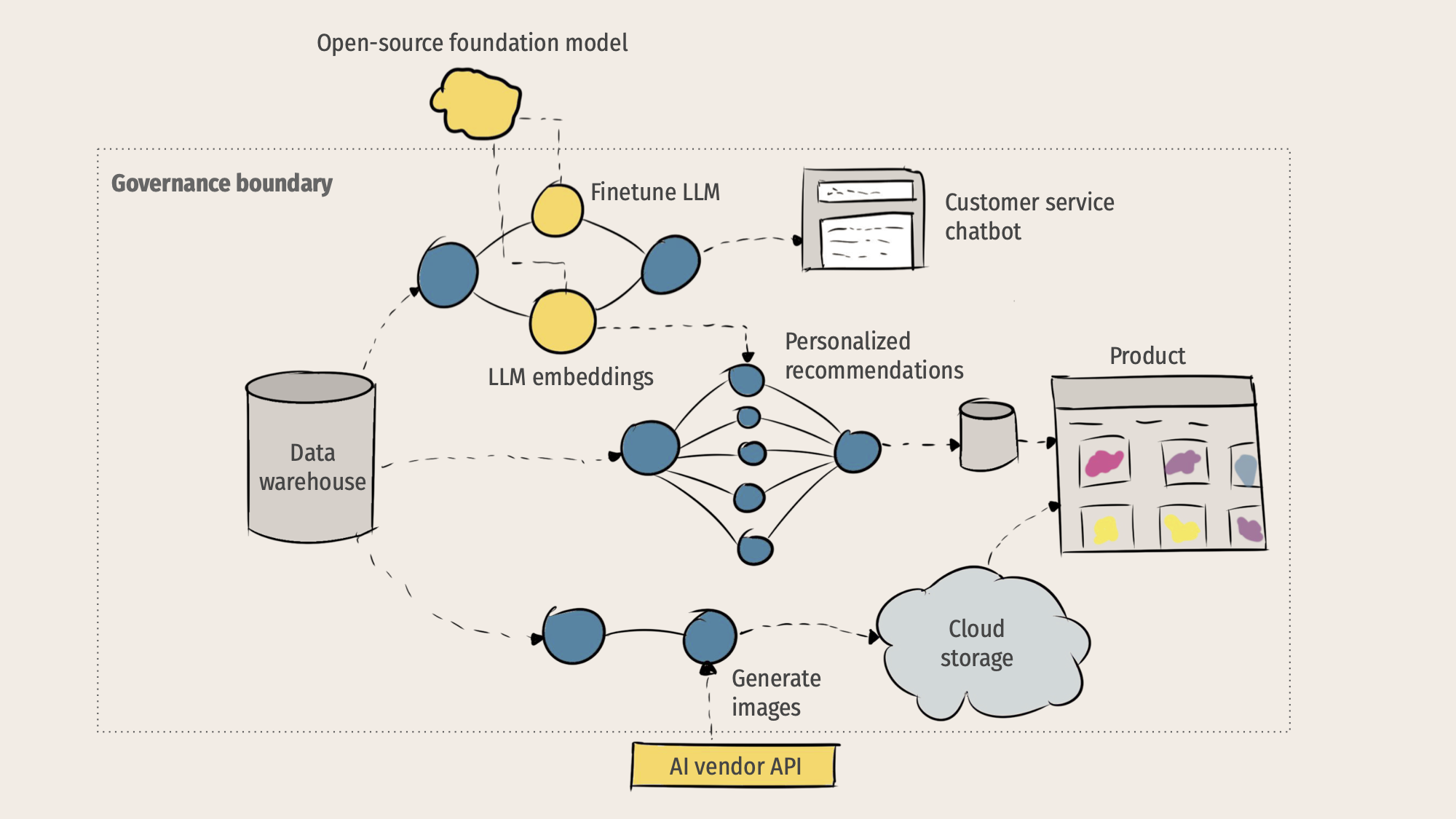
Hugo also highlighted many of the challenges involved in talking GenAI products all the way through to robust production, including:
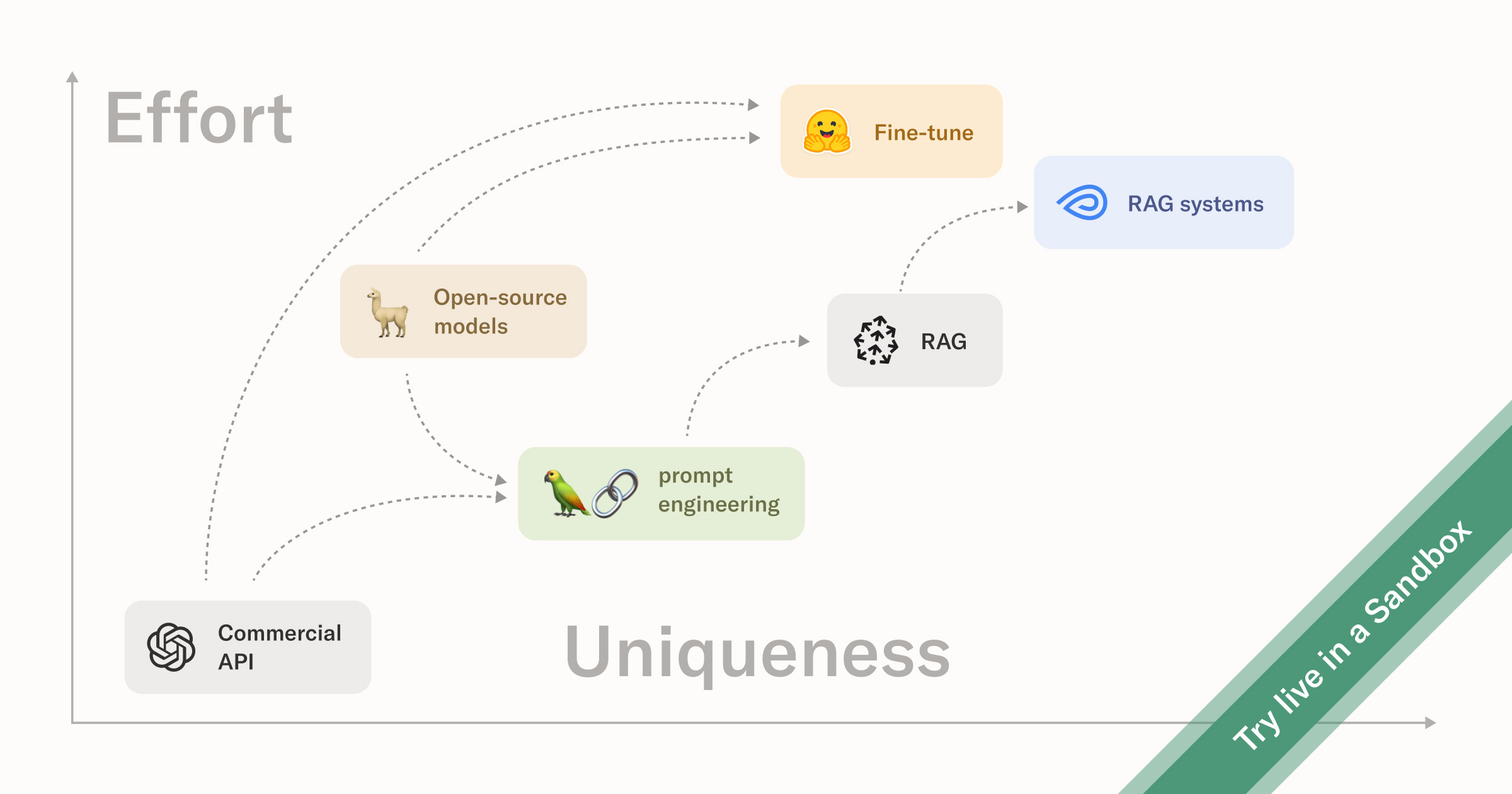
- How you can deal with LLM hallucinations using both fine-tuning and RAG;
- Data freshness issues and how to solve them by scheduling and triggering flows;
- Navigating closed- vs. open-source APIs;
- Removing single points of failure with workflows to compare/swap API backends easily;
- Cost reduction of expensive fine-tuning.
Full-stack Machine Learning and Generative AI for Data Scientists
In this tutorial, you will learn:
- How to think about setting up machine learning and AI systems, with an emphasis placed on creating a culture of experimentation, testing ideas, and nurturing experiments to derive actual value;
- How to write Python and Metaflow code to interact with the full stack of ML infrastructure;
- Applications in the world of generative AI, including the RAG pattern, vector databases, and building a constantly updating, production RAG system with Metaflow.
More details
After an introduction delving into how to think about setting up machine learning and AI systems, with an emphasis placed on creating a culture of experimentation, testing ideas, and nurturing experiments to derive actual value, Hugo and Eddie dove into the Metaflow sandbox (a super-powered, browser-based VSCode, in which we’ve provisioned the full-stack of ML infrastructure for you – try it out yourself!) with learners, covering
- How to orchestrate machine learning workflows;
- ML and AI artifacts and versioning;
- Parallel processing and monitoring;
- Scaling out to the cloud and production-ready environments (including dependency management!)
- Deploying workflows robustly and reactive ML.
They then dove into how this can all be applied in the world of Generative AI, covering
- The Retrieval Augment Generation (RAG) pattern,
- Vector databases, and
- Building a constantly updating, production RAG system with Metaflow.
If you’re interested in a longer version of the GenAI part of the workshop, make sure to check out our LLMs, RAG, and Fine-Tuning: A Hands-On Guided Tour.
Compute Anything with Metaflow
In this talk, you will learn
- About the historical progression of cloud compute and where we are today,
- Challenges in horizontally scalable systems, such as mapreduce, focusing on networking overhead and optimization issues,
- The current computing landscape and how Metaflow can be utilized as an efficient solution for managing and optimizing compute resources in such a heterogeneous and fragmented landscape.
You can also check out our Compute Anything with Metaflow post for more!
More details
In this talk, you'll get an overview of the changing landscape for compute and also understand how open-source Metaflow allows Python developers to leverage various compute platforms easily. In particular,
- The historical progression spans punch cards, minicomputers, database appliances, and the advent of Google's map-reduce paradigm in the early 2000s.
- The 2017 shift towards cloud computing, enabling scalable solutions and moving away from extensive data center constructions.
- Challenges in horizontally scalable systems, such as mapreduce, focusing on networking overhead and optimization issues.
- The current computing landscape, emphasizing cloud service diversification, the mature PyData ecosystem, and the growing demand for compute resources, particularly with the emergence of large-scale AI models. Metaflow is introduced as an efficient solution for managing and optimizing compute resources.
“The compute landscape is getting much more diverse. Gone are the days when you relied on a single paradigm for all distributed computing or just ran everything on AWS. It is very exciting that the PyData ecosystem is now much more mature - think of highly optimized AI libraries and new data tools like Arrow, Polars, and DuckDB - so our Python-based tooling can handle many more workloads efficiently.”
HPC in the Cloud
In this tutorial, you will learn,
- the basic building blocks of distributed training and HPC workloads,
- how new distributed training frameworks relate to old computing standards, and
- how to use familiar cloud computing technology to establish a high-performance computing environment at your organization.
More details
High-performance computing has been a key tool for computational researchers for decades. More recently, cloud economics and the intense demand for running AI workloads have led to a convergence of older, established standards like MPI and a desire to use them to scale AI code, such as PyTorch training runs, on modern cloud infrastructure like Kubernetes.
In this tutorial, Eddie discussed the historical arc of massively parallel computation, focusing on how modern cloud frameworks like Kubernetes can both serve data scientists looking to build production-grade applications and run HPC-style jobs like MPI programs and distributed AI training.
The session mainly focused on practical examples of submitting these jobs in a few lines of Python code. We also discuss the fundamental infrastructure components that a DevOps or platform engineer would work with to enable data scientists to use these systems. Finally, we show how to use Metaflow to plug high-performance computing primitives into a system, enabling the full machine learning stack referenced in earlier sections of this post.
Join us for more such talks!
If this type of content appeals to you, join our growing Slack community of over 3,000 data scientists to have more such conversations. Also, join our next fireside chat The Zen of Python, Unix, and LLMs with Simon Willison, creator of Datasette, an open-source tool for exploring and publishing data, co-creator of Django, member of the PSF Board, LLM aficionado, coiner of the term “prompt injection”, and an active poster on Hacker News.
