

We recently sat down with Jules Belveze, an MLOps Engineer at Hypefactors where they apply NLP and AI for media intelligence, to discuss how his team uses Metaflow, among many other great tools, and how it has impacted machine learning more generally at Hypefactors.
What type of ML questions do you work on at Hypefactors and what type of business questions do they solve?
At Hypefactors we apply AI for media intelligence. We leverage AI-based automation to derive and massively scale the real-time insights from the ongoing media landscape and handle the increasing volume of data.
We have a plethora of models, ranging from transformer-based NLP, computer vision, statistical models, and automated reasoning models. In terms of NLP, we do tasks ranging from sequence classification to text generation and span classification tasks.
All those models enable us to digest the media landscape in real-time and extract information for our clients. Some of our models, for example, our named-entity recognition model, are fundamental to powering our use cases. Our approach is to scale the AIs to comprehend hundreds of languages that are in use in the media. This allows us to cover and monitor a vast range of media sources from all corners of the world, which would be intractable without AI.
What did your ML stack look like before you adopted Metaflow and what pain points did you encounter?
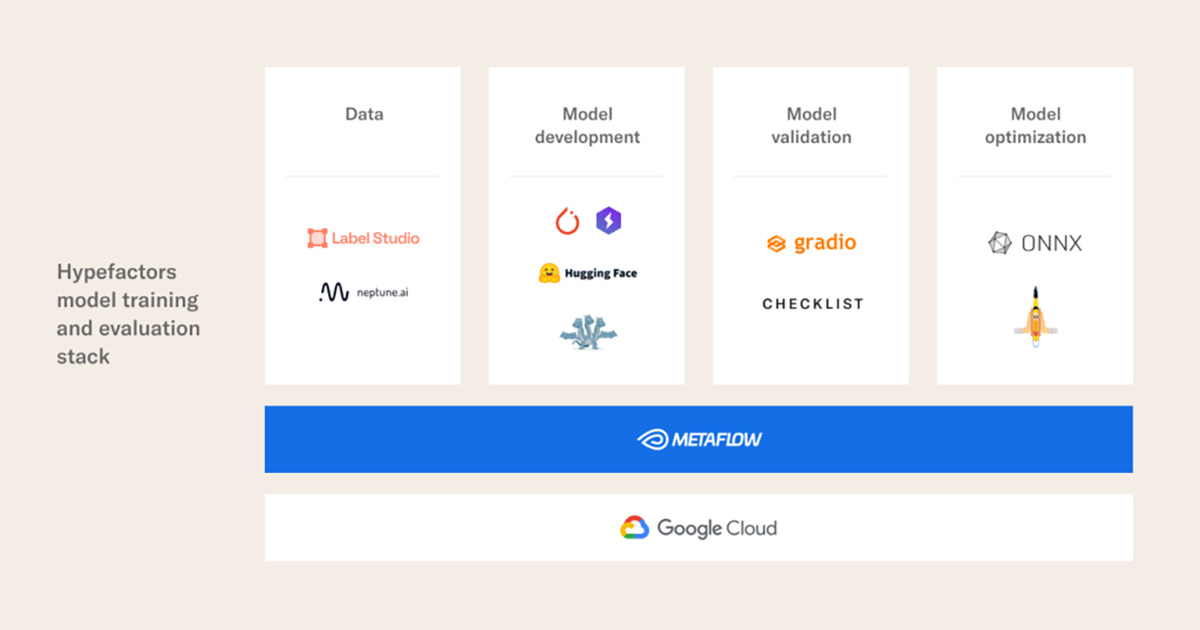
I would first split our tool stack into 4 components: data, modeling, testing, optimization, and inference.
On the data part, we typically use Label Studio for data annotation and an in-house tool called “bundler” for label QA and exploration. We then version our experiments and associated data using Neptune.ai and another in-house tool.
Regarding model development, we use a combination of PyTorch Lightning and the Hugging Face ecosystem. Hydra enables us to experiment with different configurations faster and is also used along with Neptune for experiment tracking.
Once we are satisfied with the trained models we go on and validate them. We have several tools at our disposal, among which are Checklist for behavioral testing and Gradio for ad-hoc testing.
Finally, we optimize our models for handling billions of GPU-accelerated LLM inferences a day. This is a huge workload. Also here we have a plethora of tools we apply. ONNX‘s facilities and BERT squeeze are what we use most frequently.
Regarding pain points, you can probably see that our machine learning workflows result in many different tools which require a non-neglectable time to get a grasp on all of them. It’s a very polished workflow with many interconnected cogs resulting from years of continuous improvement on our in-house MLOps processes.
But to me, the main pain point of this stack is the amount of manual work needed to stitch the 4 components together. I had to
- manually pull data, transform it and version it;
- use that data to train different model configurations;
- test the most promising one before finally optimizing and deploying it.
The main reason for such a stack choice is that we started adopting tools incrementally based on our immediate needs. This required a lot of redundant work and quite some productivity downtime, mainly to wait for one task to finish before running the next one.

What questions do you think about answering when adopting new ML technologies and how do you make decisions about what to adopt?
Before even considering adopting a new ML tool or techno it needs to answer at least one of the following questions:
- Is it automating something we are doing manually?
- Is it improving something we are already doing?
- Or is it doing something we want to do, such that we do not have to reinvent the wheel?
If it does then we assess it on a bunch of criteria:
- We start by evaluating its ease of adoption. Indeed, being a relatively small team we cannot afford to spend two months setting up an experiment tracker;
- I personally like to check the quality of the tool’s docs and ask the community for feedback before adopting it;
- Finally, a non-neglectable aspect is whether it is open-source and if not how much does it cost?
Why did you choose Metaflow?
When we identified the pain points of our ML stack an obvious solution was to find a way to stitch together the different components of our workflow. Automating it would save us a consequent amount of time and enable faster iteration. For this reason, we started looking for a workflow orchestrator and a bunch of options were in front of us. One of the main reasons we chose Metaflow was its ease of adoption and maintenance. After a few hours, we had a POC running. Also, as you might have noticed from our tool choices we tend to go for tools that do one thing and do it well. Instead of having one tool that tries to encompass many components of the ML workflow or with superfluous features. In the end, Metaflow
- Perfectly answered our needs without extra components,
- It’s easy to use and maintain, and
- We then discovered other cool features, such as flow inspection and debugging.
Before adopting Metaflow we also looked into Kubeflow and Airflow. The reasons we chose Metaflow were that it’s easy to set up and maintain even by a small data team. In addition, Metaflow’s ability to share data and other components between steps was a huge plus for us.
What did you discover about Metaflow after using it? What Metaflow features do you use and what do you find useful about them?
As described earlier when we adopted Metaflow we were primarily using it as a workflow orchestrator but with time we started using more of its components.
Currently, a feature that is a key element of our workflows is Metaflow’s Card. We have extended Jacopo’s model cards to generate a training report for each experiment we run. Those reports feature information about the model used, the datasets, various metrics of interest, and the results of behavioral tests written for this specific task. We then share these reports with different stakeholders.
As our data pre-processing is part of our workflow we also leverage Metaflow’s parallelization feature. Another feature that became quite handy is the client API. By using it we keep track of and inspect the data state during the different processing steps.
We are extremely excited about the upcoming GKE integration and cannot wait to deploy it to our Kubernetes cluster with Argo!
How has using Metaflow changed ML at Hypefactors?
The adoption of Metaflow has surely smoothened the whole data science workflow and iteration process but I see two obvious benefits.
First of all, it has enabled us to save a significant amount of time. We now only need to trigger one workflow to run the whole pipeline. No need to wait for one step to finish before running the next one. That way we can focus on something else while the workflow runs.
Also, it saves us time as most components of our workflows are reusable across projects. This is also quite valuable when onboarding new people. In the past, it was quite difficult for newcomers to assimilate all the different tools and how they articulate with each other. Now they can extend the templates we have according to their needs without having to deeply understand all the machinery behind it.
Next Steps
If these topics are of interest, you can find more interviews in our Fireside Chats and come chat with us on our community slack here.