


In this series of two posts, we dive into the world of techniques to customize large language models (LLMs). We start with a gentle overview, highlighting the benefits of instruction tuning, a popular approach that makes it more tractable to build custom models. We cover typical issues companies will face as they explore custom LLMs. In the second part, we get into technical details and show how to use Metaflow to apply instruction tuning in a customizable LLM workflow.
Federico is a post-doctoral researcher at Stanford University, working on NLP and Large Language Models. He frequently releases research projects as open-source tools that have collectively gathered thousands of GitHub stars.
Introduction
Recent advances in large language models (LLMs) have fundamentally transformed how consumers and developers perceive machine-learning-driven products, making it possible to leverage natural language as a user interface to various systems in novel ways. People are actively incorporating LLM-driven tools and applications, such as OpenAI's ChatGPT, Microsoft's Bing, and Google's Bard, in their professional and personal lives; meanwhile, organizations are making substantial investments and betting on the continued expansion of the generative AI ecosystem.
In this post, we delve into a practical exploration of LLM concepts and their applications, driven by a demonstration of a powerful new fine-tuning method called instruction tuning. We describe how data scientists can use instruction tuning to ensure language models adhere to specific instructions and generate appropriate responses for the desired use case. Next, we briefly introduce LLMs and the LLaMA family of models and then motivate instruction tuning.
Large language models
From a statistical perspective, the recently trending language models (LM) have a structure that estimates the probability distribution of sequences of tokens, where tokens can refer to single characters, subwords, or whole words.
In essence, LMs are predictors for the subsequent token in a sequence. To achieve this, most LMs undergo an extremely resource-intensive training process, in which they learn to predict the next token by packaging extensive text collections such as books, Wikipedia articles, or even the entire Internet as training datasets.
The "largeness" of a language model refers to its parameter count and the scale of its training corpus. Typically, the term “large language model” is reserved for models with billions of parameters and internet-scale training datasets.
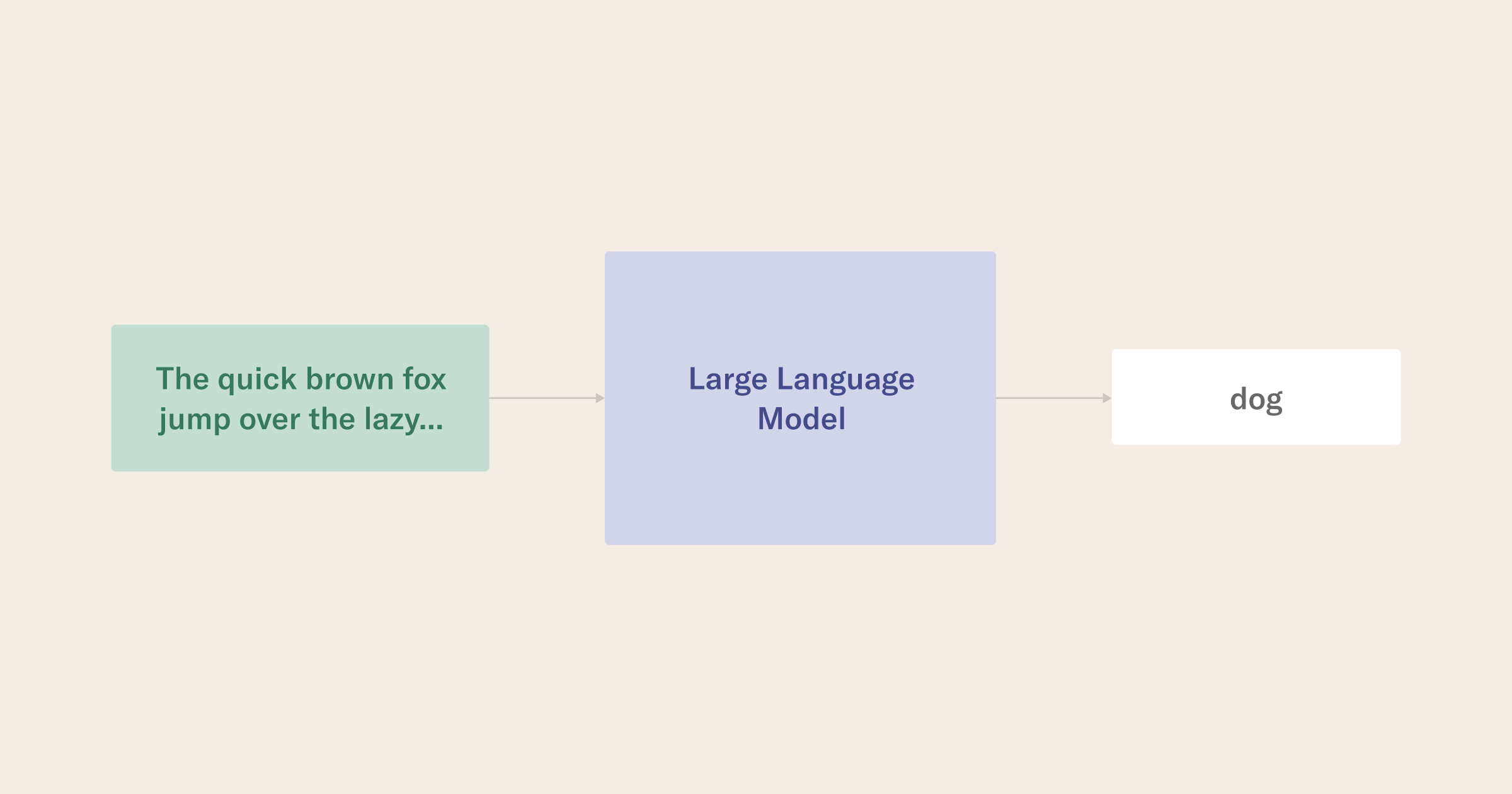
The language modeling process, at scale, enables the model to mimic human linguistic behavior, answer questions, and classify text into different categories (e.g., classify if a news article is about sports or politics).
Increasingly, recent LLMs such as Codex, PaLM, ChatGPT, and GPT-4 even appear to demonstrate emergent capabilities (see Wei et al., 2022 and Suzgun et al., 2022) such as medical and legal knowledge (see Nori et al., 2023 and Katz et al., 2023) and human-level reasoning capacity on professional benchmark exams.
Language models have shown surprising abilities at different scales, so it is crucial to be mindful that while the first large language models we used a couple of years ago had millions of parameters, modern models now have (sometimes hundreds of) billions of parameters. Thus far, the bigger the models are, the better they appear at solving complex tasks that require emergent behavior.
A rise in open-source LLMs
While language models have a long history that spans many decades, only recently, thanks to the availability of large computing and large datasets, along with hardware developments (see Hooker, 2020), have we been able to train them at billion parameter scales on large amounts of data. Much of the capacity to source these datasets and to access the compute required to train state-of-the-art LLMs is limited to organizations with large budgets for experimental AI projects. Thus, commercial entities such as OpenAI, ChatGPT, Google, and Microsoft have driven the recent hype in the language modeling space.
Indeed, the ChatGPT product and the GPT-3/GPT-4 models that power it may be the fastest-growing product in history. A core observation of the reasoning behind this post is that adapting what these commercial models do with instruction tuning workflows has proven a critical success factor in using these models in products; for example, in the wave of chatbot and personal assistant products that have emerged over the last year.
Meanwhile, there has been a notable surge in open-source LLM development of late, with advancements occurring within hours and public code repositories swiftly attracting thousands of enthusiastic developers on GitHub. With the increased speed of such improvements, practitioners and companies can increasingly experiment with owning more of their LLM stack.
What is instruction tuning?
Instruction tuning is a specific kind of fine-tuning that has been introduced in different ways in different papers (see Ouyang et al., 2022 but also Sanhm, Webson, Raffel, and Bach et al., 2022 and Wei et al., 2022). The idea, at least in the modern adaptation, is simple: we fine-tune the models on a new language modeling task, with examples that have an additional structure built into how the model prompts.
The instruction-tuned model receives pairs of inputs and outputs that describe tasks that guide the model. For example,
Instruction: Write a list of fun things to do on weekends
Output: Hikes, spend a day at the park, picnics, movie night
Behind the scenes, we ask the model to learn to do language modeling on the entire string of text “Instruction: Write a list of fun things to do on weekends Output: Hikes, spend a day at the park, picnics, movie night.” This change to the structure of data samples the model sees is the main methodological difference between generic single-task fine-tuning (see BERT) and instruction tuning.
Instructions can be any text, such as writing emails, editing sentences, etc. Since we can make very general and diverse instructions, we expect the model to generalize well on many instruction-driven tasks.
Training in this way, when compared with purely computing a loss function on the next token prediction of entire documents, models learn to follow the pattern of instructions and outputs and become much more valuable in answering questions like those humans are often interested in. In other words, instruction training improves the quality of the answers given by language models by training the model to respond in a format aligned with how humans tend to give and receive instructions.

While instruction tuning was popularized by and has been in the works at Google, Meta, and OpenAI for a while, we have had a revolution in the field in the last couple of months. Meta AI released the LLaMA models, a first set of high-quality and open-source large language models of different sizes. After LLaMA, the Stanford NLP group released Alpaca: an instruction-tuned model that starts from LLaMA and uses instructions generated by GPT-3 as a dataset. These are some examples of instructions used to train Alpaca:
| Instruction | Output |
|---|---|
| Give three tips for staying healthy. | 1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases. 2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week. 3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night. |
| Give two examples of a liquid. | Here are two examples of a liquid: 1. Water: Water is a clear, colorless and odorless liquid that is vital for all forms of life. It exists in lakes, rivers, oceans, and even underground. 2. Oil: Oil is a viscous liquid that is derived from petroleum. It is typically used as a fuel or lubricant in various industries, such as transportation and manufacturing. |
Many derivative models have been released in response to LLaMA and Alpaca. Even if smaller models cannot directly compare with large scale models like ChatGPT/GPT, the quality of their output makes them very useful for many applications.
Why instruction tuning?
Language models produce fascinating results, but getting meaningful output from an LLM can be challenging. A prompt completion may initially make sense, then quickly diverge from a natural response, not following the intended guide and veering further off track with each prediction.
It is the nature of autoregressive models - which next-token predicting LLMs are - that what the model sees as the next best token to predict can be seen by an observer as an error that propagates and is exacerbated each time the previous model output becomes the next time step’s input.
Indeed, if you have used a plain LLM in the past, you might have seen that simple next-word completion doesn’t always give you the results you expect. Moreover, language models are often not easy to apply to specific tasks; for example:
- How would you “tell” the model it should classify documents in its generated output tokens?
- How do we make them do valuable tasks such as writing emails or answering questions?
Is instruction tuning right for my use case?
If you want to use an LLM to power a product experience, you will likely need an approach to the challenge raised in the previous section. There are ongoing conversations around whether these specific, task-driven LLM use cases require fine-tuning (as demonstrated in our follow-up post) or if skillful prompt engineering of foundation LLMs like OpenAI’s GPT family is sufficient for guiding model responses.
When to prompt
When starting a new project, consider using GPT-4 - or any model already trained to respond to instructions - to solve the task(s). Starting with an external API will help you get going quickly and see whether out-of-the-box performance is good enough for your use case. Prompt engineering is the process of designing prompts that guide an LLM to solve a particular language task. A key consideration is that the original training datasets for LLMs come from a general sampling of text on the internet. So if you expect the model’s training set to cover your instruction-like use cases well, then fine-tuning may not necessarily add many benefits to how the model performs. In this case, clever prompt engineering can take you very far and reduce your operational burden significantly.
However, this might not always be the case, as a foundation model’s training dataset might not cover the desired instruction-driven data likely to appear in your task domain, or API latency and costs may block your desired use patterns. You may also want to use proprietary data in fine-tuning workflows that you don’t want to expose to external APIs. In these cases, fine-tuning may be a better approach.
For more on the prompt engineering decision space, Chip Huyen recently provided an overview of LLMs in production with a focus on the continuum between prompt engineering and fine-tuning.
When to apply instruction tuning
Increasingly many companies have proprietary data and desire LLM use cases that require the model to perform better on tasks than off-the-shelf foundation models. Moreover, despite prompt engineering efforts with the foundation model, you may want to own the fine-tuning process and possibly even the complete training lifecycle. Importantly, instruction tuning is one path to giving developers greater control over LLM behavior and makes it possible to build uniquely functional and differentiated product experiences in a world where many users are increasingly familiar with generic ChatGPT-level results.
While tuning requires a higher initial investment, it can lower operational costs by reducing inference costs around expensive API calls and making operations more predictable by removing a dependency on a 3rd party vendor.
To summarize, instruction tuning is fine-tuning with a particular training dataset containing examples that prepend context to inputs the model sees about the task we want the LLM to perform as it predicts token sequences. Thus, working with instruction-tuning workflows is similar to general LLM workflows, and we can generalize learnings.
The choice between instruction-tuning and prompt engineering doesn’t have to be either-or. You can use prompting to additively improve the performance and constrain the output space of your instruction-tuned large language model on the fly.
Considerations for applying LLMs
Despite the fun demos that generative AI has saturated the internet with, working with LLMs in an organization with an established product line and brand is a serious design and engineering endeavor, particularly if you want to move beyond making generic, external API calls. This section highlights three categories of issues we are paying attention to and desire to explore with our customers.
Hardware access
If you only want to run inference or are just experimenting with models, open-source tools that help you do this with limited hardware are emerging rapidly. For example, the GPT4All project allows you to prompt some billion-parameter LLMs on your laptop, drastically reducing access barriers to learning how to work with these models in your programs.
However, this post and our subsequent hands-on post focus on workflows where you can own the infrastructure stack and observe the contents of datasets, model weights, and code. In this realm, GPUs are typically a hard requirement. Moreover, despite advances in reduced precision and parameter-efficient training, efficiently operating LLM workflows will most likely require on-device GPU memory beyond what all but the latest GPUs afford.
Organizations with ambitions to use LLMs in this way must stay aware of GPU market conditions and have an ongoing GPU accessibility plan. Without a plan, you will likely encounter moments that negatively affect a data scientist’s productivity.
Consider the recent all-too-common scenario where a data scientist’s workflow depends on accessing a cloud service provider’s GPUs, and their workflow is blocked because some other customer of the cloud service provider decided to consume all the VM instances with the latest GPUs on them. What do you do in this situation? Shifting workflows to another resource provider can take days or more. It may also require slow processes where DevOps and business leaders need to get involved in approving new infrastructure and cost drivers while data scientists do other work or remain idle on the project.
Dedicated GPU clouds
At Outerbounds, we encounter this problem too and recently have been using a mixture of GPU providers since generative AI has upended the market. In addition to all the major clouds, AWS, Azure, and GCP that Metaflow supports, we have been exploring dedicated GPU clouds such as CoreWeave.
A benefit of CoreWeave is that they let you compose granular resource settings, such as memory and disk space, on each GPU instance you ask for. CoreWeave’s supply of state-of-the-art machines, and a large selection of various GPU types, multiplies the benefits of granular resource selection on VM instances, allowing you to access GPUs with 80GB of on-device memory. Access to the latest hardware advances can drastically simplify the required software stack, as huge models can fit in 80GB of on-device memory, obviating the need for extremely complex distributed training approaches.
For example, when working with LLMs, you may want to select only one or two accelerators at a time and attach a lot of extra RAM and disk space to this instance to deal with huge datasets and in-memory requirements of model parameters. CoreWeave makes it easy for us to customize such resources and saves us money by letting us make granular choices about the hardware our workflows need, compared to reserving either zero or eight A100s at a time and letting most of them go unused. In our example, we found the training to work well up to 33B parameters on an instance with two A100 processors, and also on an instance with two A6000 processors.
Learning to operate LLMs to power real-world products
Much of the applied content on the internet about LLMs centers on flashy but brittle demos that cannot be used in production contexts as such. These demos also tend to rely on external APIs, and companies with established brands realize they cannot risk outsourcing a core part of their product’s supply chain to such external services that can change their behavior on a whim.
Also, you don’t only adopt an LLM once. Like other technical product features, they should be subject to constant maintenance and improvement as the world around them evolves. LLMs may be new and shiny in the spring of 2023, but LLMs adopted today will turn into table stakes or, worse, legacy technical debt in a few years.
In a previous post, we went into detail about how we expect LLMs will affect these issues and the future of the ML infrastructure stack more broadly.
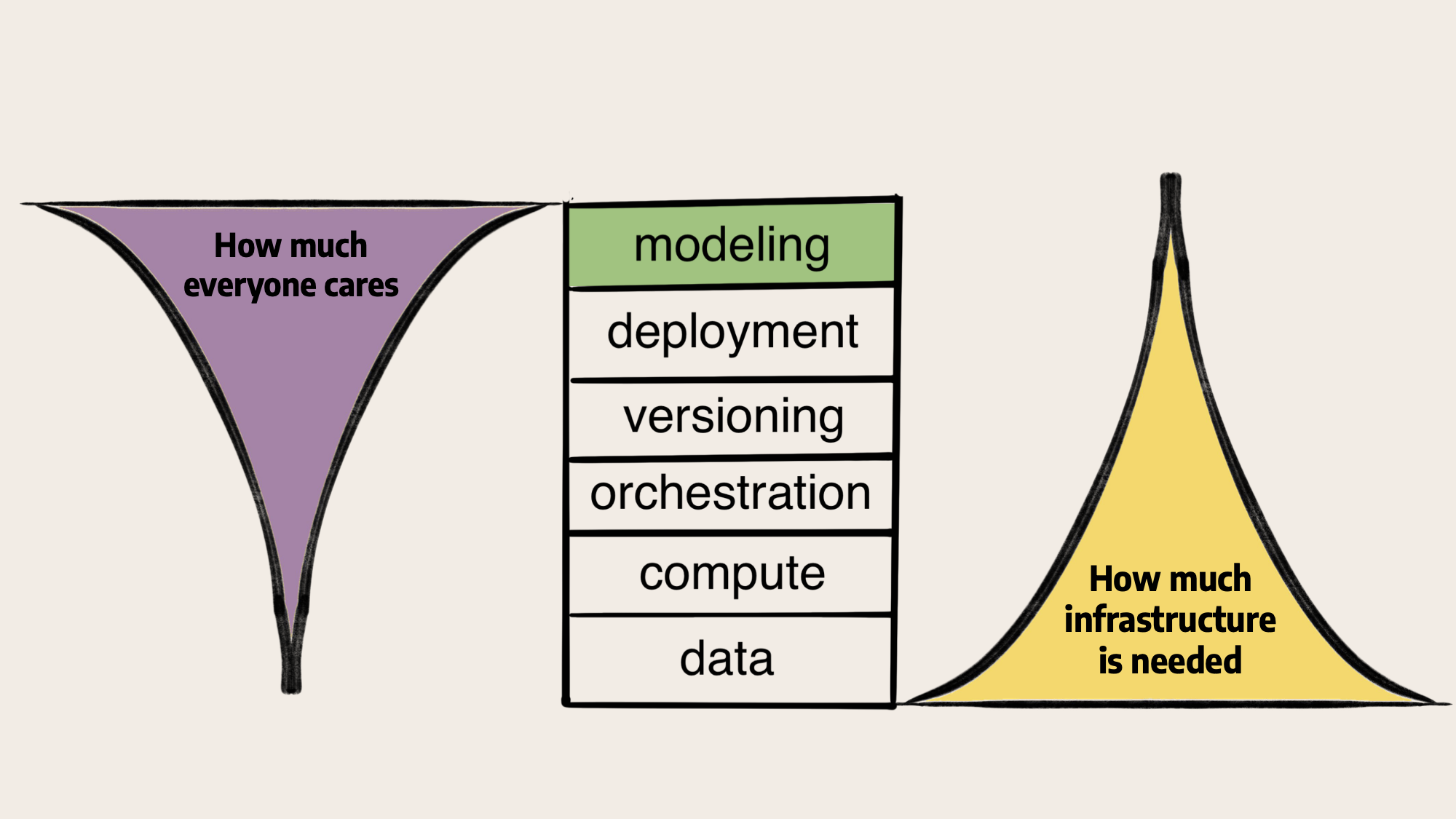
A core observation is that although the recent discussion has much focused on the models themselves and the data to train them, operationally custom LLMs require similar infrastructure and tooling as any other ML model: You need to be able to feed them with data from your databases, run them at scale, orchestrate them as a part of larger systems, and track, version, and experiment with them confidently. And, importantly, make the whole production-grade toolchain easily accessible to your ML engineers so that they can iterate quickly.
Ethical issues
Besides engineering challenges, there are complex ethical considerations when deploying large language models in production. There is a lot of concern among AI researchers and the general public around issues that might arise from LLMs and their usage. The models, such as many mentioned in this post, have known biases (Abid et al., 2021), and their use can be harmful in practice if you are not careful to constrain their input and output spaces. These issues are common to all the generative AI landscape, including text-to-image generation models such as DallE and Stable Diffusion (Bianchi et al., 2023). We hope to cover this deep topic in detail in future posts and conversations.
Next steps
In this post, we covered an introduction to instruction tuning. In the following article, we will describe a small experiment we ran using HuggingFace and Metaflow. Join us on Slack about your experiences and goals in working with LLMs, and stay tuned to the blog for more posts like this one.
Acknowledgments
We would like to thank Mert Yuksekgonul, Mirac Suzgun, Patrick John Chia, Silvia Terragni, Giuseppe Attanasio, and Jacopo Tagliabue for feedback and suggestions on a previous version of this blog post.