Parallel Branches in Workflows
In this episode, you will build a workflow to train multiple models in parallel. This is done using the branching pattern of Metaflow. Specifically, you will see how to define steps so that Metaflow knows to execute them in parallel on multiple CPU cores or cloud instances. To show this you will combine the previous two flows into and train the RandomForestClassifier and XGBoostClassifer in parallel.
1Write Your First Branching Flow
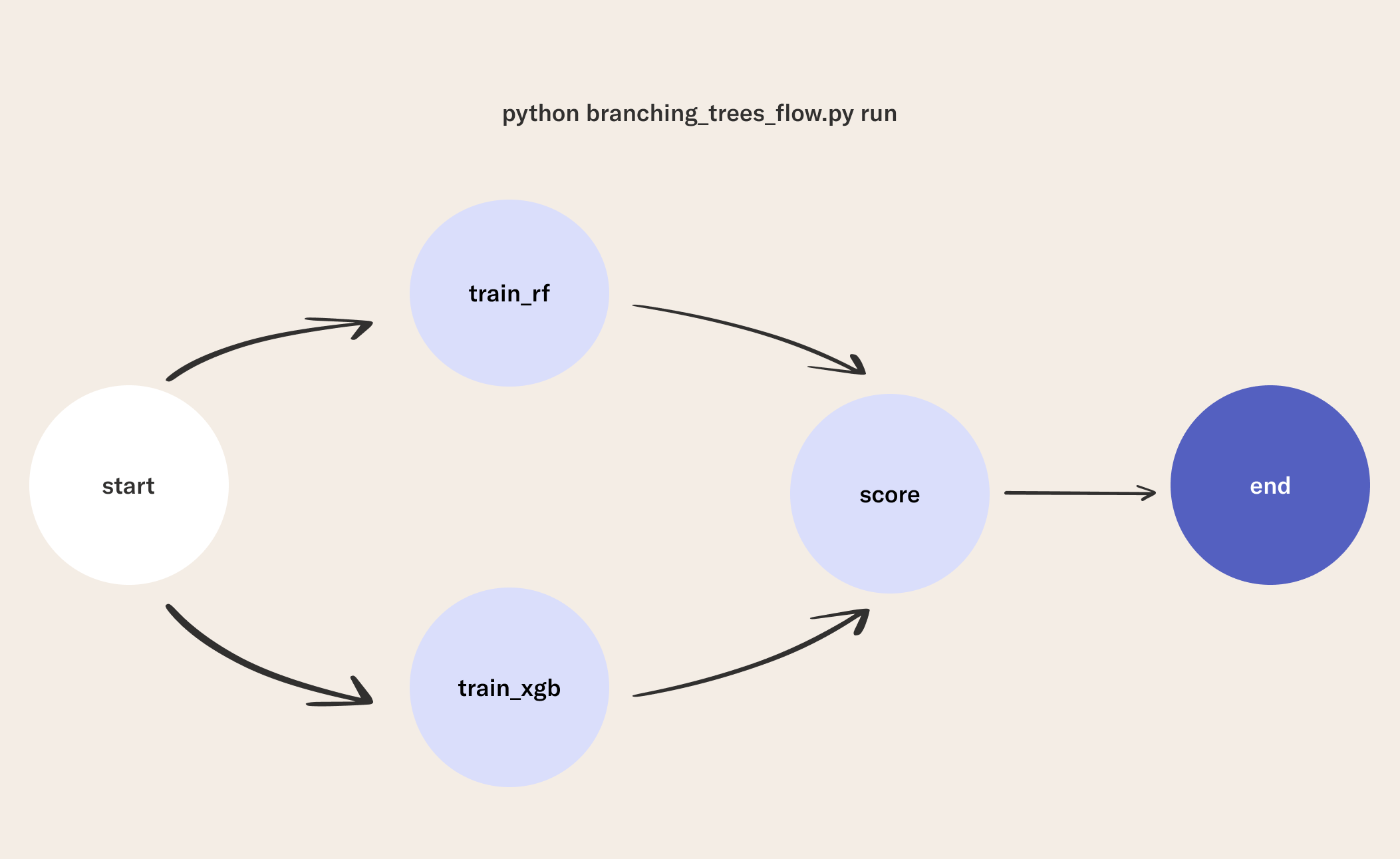
The flow has the following structure:
- Parameter values are defined at the beginning of the class.
- The
startstep loads and splits a dataset to be used in downstream tasks.- Notice that this step calls two downstream steps in
self.next(self.train_rf, self.train_xgb). This is called branching. This means thetrain_rfandtrain_xgbsteps will be run in parallel.
- Notice that this step calls two downstream steps in
- The
train_rfstep fits asklearn.ensemble.RandomForestClassifierfor the classification task using cross-validation. - The
train_xgbstep fits axgboost.XGBClassifierfor the classification task using cross-validation. - The
scorestep evaluates each classifier on a held-out dataset for testing.- This step is referred to as a join step.
- It takes in an extra argument that contains the results of the tasks that call
self.next(self.score).
- The
endstep prints the accuracy scores for each classifier.
branching_trees_flow.py
from metaflow import FlowSpec, step, Parameter
class ParallelTreesFlow(FlowSpec):
max_depth = Parameter("max_depth", default=None)
random_state = Parameter("seed", default=21)
n_estimators = Parameter("n-est", default=10)
min_samples_split = Parameter("min-samples", default=2)
eval_metric = Parameter("eval-metric", default='mlogloss')
k_fold = Parameter("k", default=5)
@step
def start(self):
from sklearn import datasets
self.iris = datasets.load_iris()
self.X = self.iris['data']
self.y = self.iris['target']
self.next(self.train_rf, self.train_xgb)
@step
def train_rf(self):
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
self.clf = RandomForestClassifier(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
min_samples_split=self.min_samples_split,
random_state=self.random_state)
self.model_name = "Random Forest"
self.scores = cross_val_score(
self.clf, self.X, self.y, cv=self.k_fold)
self.next(self.score)
@step
def train_xgb(self):
from xgboost import XGBClassifier
from sklearn.model_selection import cross_val_score
self.clf = XGBClassifier(
n_estimators=self.n_estimators,
random_state=self.random_state,
eval_metric=self.eval_metric,
use_label_encoder=False
)
self.model_name = "XGBoost"
self.scores = cross_val_score(
self.clf, self.X, self.y, cv=self.k_fold)
self.next(self.score)
@step
def score(self, modeling_tasks):
import numpy as np
self.scores = [
(model.model_name,
np.mean(model.scores),
np.std(model.scores))
for model in modeling_tasks
]
self.next(self.end)
@step
def end(self):
self.experiment_results = []
for name, mean, std in self.scores:
self.experiment_results.append((name,mean,std))
msg = "{} Model Accuracy: {} \u00B1 {}%"
print(msg.format(name, round(mean, 3), round(std, 3)))
if __name__ == "__main__":
ParallelTreesFlow()
2Run the Flow
python branching_trees_flow.py run
In this episode, you trained two models in parallel using multiple CPU cores. In the next episode, you will transition from authoring and running flows to focusing on how to analyze the results produced by flows. See you there!