Service Architecture
Metaflow can be used in the local mode, e.g. on a laptop, without any connection to the outside world. The local mode is the default out-of-the-box when you pip install metaflow. In this mode, all computation is performed locally as subprocesses and all data and metadata is persisted in a local directory.
To benefit from the centralized experiment tracking and sharing via Client API, scalable computation, dependency management, and production deployments, we recommend that an administrator sets up infrastructure that allows Metaflow to be used in the shared mode.
Shared Mode Architecture
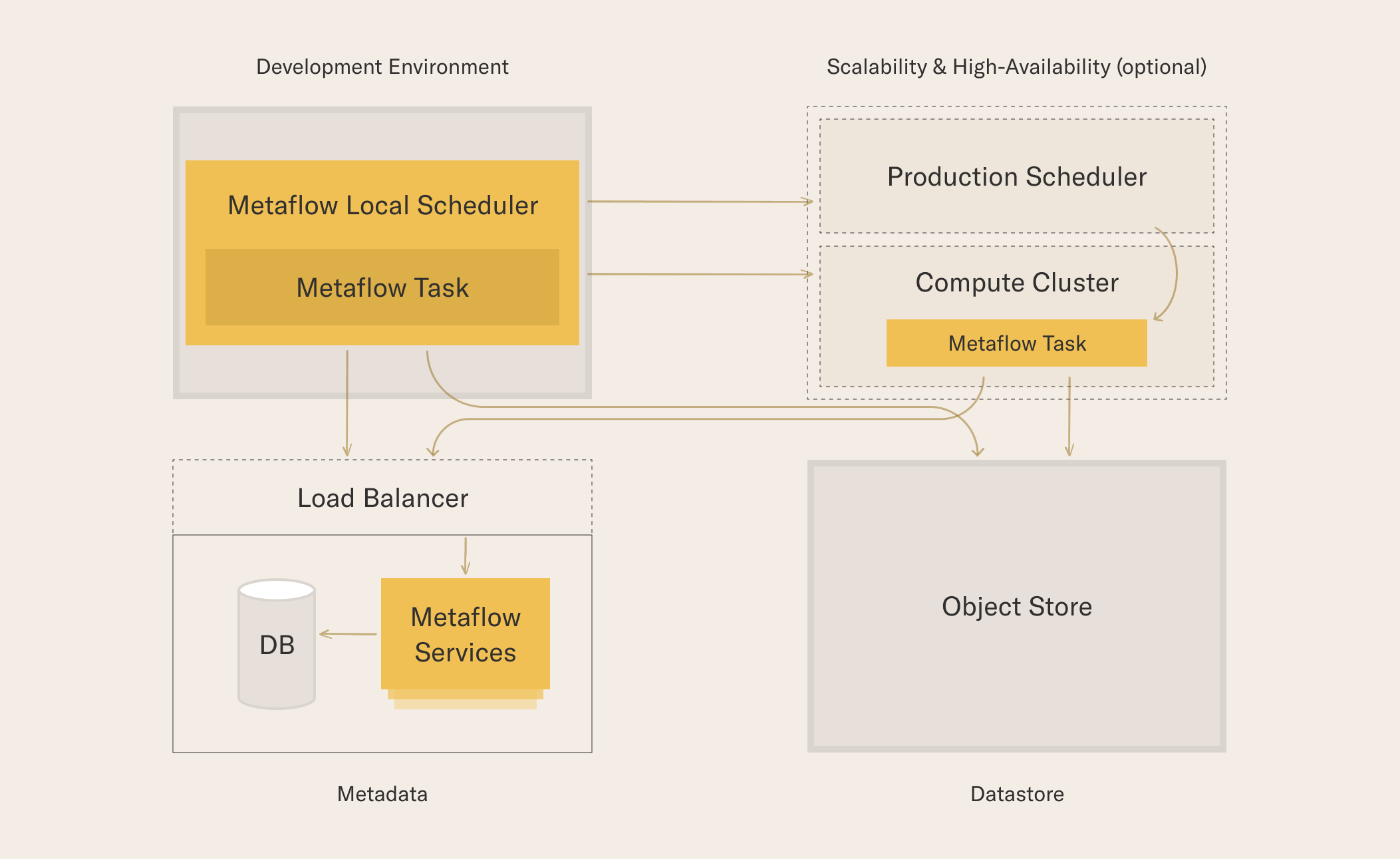
The diagram below shows an overview of services used by Metaflow in the shared mode. The services outlined in yellow are required: Development Environment, Datastore, and Metaflow Service and its database. The services outlined with dashed lines are optional.
Before we go into details about each of the services, the following diagram highlights their role in the Metaflow stack.
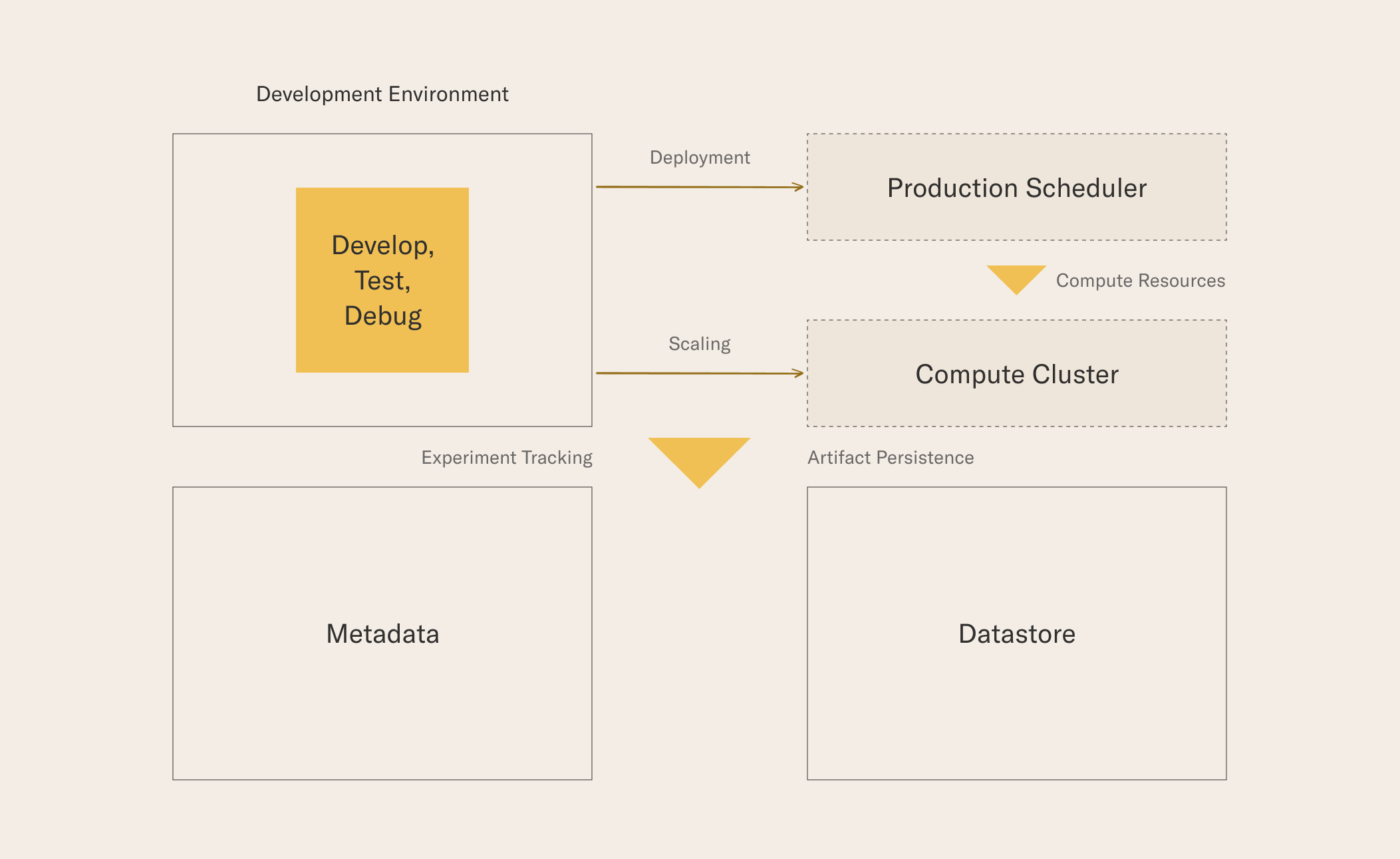
Metaflow treats both prototyping and production as equally important activities, which is why both Development Environment and Production Scheduler are supported as first-class execution environments. Both of these environments can rely on a separate Compute Cluster, typically a container platform, to provision compute resources on the fly. Much of the value of Metaflow relates to the fact that all executions are tracked by a central metadata service and their results are persisted in a common datastore.
Required Services
At the minimum, you need to set up the following three services to leverage Metaflow in the shared mode.
Development Environment
The client-side of Metaflow consists of a command-line tool, metaflow, and a Python package, also named metaflow. The user needs a development environment where they can develop and test their Metaflow workflows.
The development environment has the following requirements:
- Metaflow needs to be installed. Note that there isn’t a strict requirement to use the latest version of the library. Users can upgrade their library at their own cadence.
- Metaflow needs to be configured to access the services provided. At the minimum, the configuration needs to include the metadata service URL and information related to the datastore.
- The development environment needs to have the right cloud credentials to make API calls to the provided cloud services (e.g.
~/.aws/credentialsor IAM instance profile needs to be set up).
The user’s laptop can work as a development environment but we recommend providing a sandbox instance or a container in the cloud, if possible. A cloud instance has multiple benefits:
- Network connectivity to the datastore has a much lower latency, higher throughput, and less variance compared to a typical home or office wifi, which results in a better user experience.
- It is possible to provide large development instances for power users with lots of RAM, multiple CPU cores and optionally with GPUs. Metaflow will automatically use all the cores available to parallelize workflows, enabling faster iterations during development.
- The cloud instance can use the same operating system, Linux, as the compute cluster, which makes it more straightforward to use libraries with OS-specific dependencies.
- It is often easier to provide automatically refreshing authentication tokens on a cloud instance (e.g. using an IAM instance profile on AWS) compared to a laptop.
Note that many modern IDEs, e.g. VSCode or PyCharm, support code execution on a remote instance so the users can use a local editor to edit their code but execute it in the cloud.
Metadata
The Metaflow Service tracks all details about Metaflow executions, including pointers to the artifacts in Datastore. The main consumer of the service is the Client API. Metaflow executions write to the service but they don't read from it internally as they access Datastore directly. This ensures that the Metaflow Service doesn't easily become a bottleneck, even when tens of thousands of tasks are being executed concurrently.
No bulk data is stored in the service, so just a small instance backed by a medium-size database can keep track of millions of executions. As of today, we support Postgres as the backend database.
The service is provided as a pre-baked Docker container which you can deploy to a microservice platform of your choice. The service is a simple Flask app communicating with the Metaflow library over HTTP, so you can deploy it like any other basic web application.
The service doesn’t have any built-in support for authentication. We assume that the service is typically deployed inside a (virtual) private network that provides a secure operating environment.
Optionally, you can deploy multiple instances of the service behind a load balancer. The AWS CloudFormation deployment path does this for you automatically.
Metadata Migrations
We recommend that you always deploy the latest version of the service image. The latest image is guaranteed to be compatible with all previous versions of the client. However, occasionally new features of Metaflow require the database schema to be changed, which will require manual action from the administrator.
To make the administrator’s life easy, the Metaflow Service comes with a built-in migration service. When you deploy or restart the latest version of the image, it will detect the schema version of the database, and launch a corresponding version of the service. It will not upgrade the database automatically.
If a new feature in the client requires a newer version of the service, a clear error message is shown. In this situation, the administrator should decide if and when they want to run the migration, which will incur some downtime - up to a few minutes. As a best practice, it is advisable to take a backup of the database prior to the migration which allows you to roll back the migration in case something goes wrong.
The migration itself is just a matter of running a single command and restarting the service afterwards. How to do this exactly depends on your deployment strategy: See a separate section about running migrations on AWS.
Datastore
While Metaflow uses local disk as a datastore in the local mode, all serious use cases of Metaflow are expected to use a cloud-based object store such as AWS S3 as the persistence layer. Object stores provide excellent scalability in terms of space, massive throughput for concurrent requests, high durability, and desirable cost-effectiveness, which means that Metaflow can afford storing all artifacts automatically without having to worry about overloading the storage backend. Internally, Metaflow uses the datastore as a Content Addressable Storage, which means that no duplicate artifacts are stored.
In the administrator’s point of view, an object store like S3 is effectively maintenance-free. You may configure access policies and lifecycle rules for your object store as required by your organization.
Optional Services
The following two services are optional. They provide a way to scale out Metaflow executions and deploy Metaflow workflows in a highly available production scheduler. If your organization doesn’t require elastic scalability and occasional downtime for scheduled workflow executions is acceptable, you may ignore these services.
Compute Cluster
Similarly as a cloud-based object store provides a virtually infinite datastore, a cloud-based, elastically scalable compute cluster provides an infinitely scalable compute backend. Conceptually, Metaflow uses the compute cluster as a function-as-a-service platform: The user defines a function to be computed, a Metaflow step, optionally specifying resources it requires. The function is either executed locally in the Development Environment as a subprocess or it is shipped out to a compute cluster which provisions resources for it on the fly.
Metaflow packages and snapshots the user's code automatically in Datastore for remote execution. In addition, Metaflow provides built-in support for defining dependencies required by the user's code. The dependencies are also snapshot in Datastore, to make sure that unexpected changes in the package repository won't affect Metaflow executions.
Since Metaflow packages both the user's code and dependencies automatically, executions on Compute Cluster can use a single, off-the-shelf Docker image for all executions, which removes a major source of operational complexity as the administrator doesn't need to maintain a CI/CD pipeline, custom Dockerfiles, and potentially hundreds of separate images.
The compute cluster can support two dimensions of scalability: vertical (bigger instances) and horizontal (more instances). For instance, vertical scalability can a good way to scale the training step of a large model that runs most efficiently on a large instance with tens of CPU cores, multiple GPUs, and hundreds of GBs of RAM. Horizontal scalability through Metaflow’s foreach construct can be an efficient way to handle e.g. sharded datasets in an embarrassingly parallel fashion. The user can choose any combination of the two dimensions which best matches to their workload.
Currently, Metaflow provides an integration to Kubernetes and AWS Batch as a Compute Cluster backend. The administrator can configure namespace in Kubernetes or compute environments in AWS Batch depending on the types of workloads that they want to support in Metaflow.
Production Scheduler
Metaflow comes with a built-in local scheduler which makes it easy to develop and test workflows in Development Environment. It is a great solution for use cases where quick, manual iterations are preferred over high availability and unattended execution.
Data science workflows that need to run automatically without any human intervention have a different set of requirements. Most importantly, Production Scheduler needs to be highly available: it needs to be backed by a cluster of instances so that a failure of any single instance won’t cause downtime. Preferably, the scheduler should be highly scalable, both in terms of the size of a single workflow, which may spawn tens of thousands of tasks, as well as in terms of the number of concurrent workflows, which can grow to hundreds of thousands in a large deployment like at Netflix. In addition, the scheduler should provide flexible ways to trigger executions, and it should provide a plethora of tools for operational monitoring and alerting.
The user can deploy their Metaflow workflow to Production Scheduler with a single command - no changes in the code are required. We recognize that “deploying to production” is not a linear process. Rather, we expect the user to use both the local scheduler and the production scheduler in parallel. For instance, after the initial deployment, the data scientist typically wants to continue working on the project locally. Eventually, they might want to deploy a new, experimental version on the production scheduler to run in parallel with the production version as an A/B test. Also, things fail in production. Metaflow allows the user to reproduce issues that occur on the production scheduler locally, simply by using the resume command to continue the execution on their local machine.
Currently, Metaflow supports three workflow orchestrators for scheduling flows in production:
For more background about production orchestration, see the release blog post for Step Functions integration and a post about Metaflow-Airflow integration.
Security Considerations
Metaflow relies on the security mechanisms and policies provided by the deployment environment, for instance, VPCs, Security Groups and IAM on AWS. These mechanisms allow you to define as fine-grained security policies as required by your organization.
In the simplest setup, you can deploy all Metaflow services inside a common security perimeter, e.g. within a single virtual subnet. A more tightly controlled deployment is provided by our CloudFormation template which creates tightly scoped IAM roles and VPCs for you automatically.
Metaflow allows all users that have access to a shared Datastore and Metadata to access any data from past executions. If your organization requires more control over data governance, you can create multiple isolated Metaflow deployments.
For maximum security and control, you can consider a similar setup as what we provide with Metaflow Sandboxes. Sandboxes disallow all network ingress and egress within Compute Cluster. The user is able to execute arbitrary code, even using arbitrary library dependencies defined using @conda, and they are able to process arbitrary data that is imported in Datastore either using standard S3 tools or the IncludeFile construct. They can deploy workflows to Production Scheduler and analyze results in the provided notebook environment. In effect, they can perform any data science operations as usual.
However, no data can leave the environment since all communications with the external world is blocked. Technically, Sandboxes are implemented using extremely tightly scoped IAM roles, VPCs, and security groups. If you are interested in providing a similar sandbox environment for your users, please reach out to us.