Intermediate Computer Vision: Episode 5
Now that you have the core elements for a robust computer vision training environment, how can you use the TrainHandGestureClassifier flow to iteratively find the best models for your use case?
For the rest of this tutorial, we will demonstrate two important elements of iterative model development: checkpointing model state and tracking experiment results.
To follow along with this page, you can access this Jupyter notebook.
1Checkpoint Models
Checkpointing in model development essentially means that you save the state of a model, so you can resume it at a later time. This way you can make sure you do not lose results, such as your trained model. It also ensures you have a process to load an already trained model in future training and production scenarios while avoiding duplication of costly computation.
In the PyTorch example used in the TrainHandGestureClassifier flow, a "checkpoint" refers to this code.
checkpoint_dict = {
'state_dict': model.cpu().state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'epoch': epoch,
'config': config_dict
}
torch.save(checkpoint_dict, checkpoint_path)
You can save any artifact of the training work you have done in a checkpoint_dict like this.
Then, you can resume the model state from the checkpoint.
from models.mobilenetv3 import MobileNetV3
model = MobileNetV3(num_classes=num_classes, size='small', pretrained=pretrained, freezed=freezed)
...
checkpoint = torch.load(checkpoint, map_location=torch.device(device))["state_dict"]
model.load_state_dict(checkpoint, strict=False)
...
model.to(device)
return model
Here are more general resources from the PyTorch documentation on checkpointing.
2Uploading the Best Model to the Cloud
Model checkpoints in this example are written to the best_model.pth location.
But if we are running on a remote compute instance, how do we move this checkpoint to a cloud resource that will persist beyond the lifecycle of the compute task? Again, Metaflow's S3 client makes this easy!
There are many ways to structure model development workflows. You may not have to store model checkpoints in the cloud, for example. You also might prefer to use Metaflow's IncludeFile pattern to move data of this type onto remote compute instances.
After each time model performs better than the previous best one, it is checkpointed and the result is uploaded to the cloud using this snippet:
path_to_best_model = os.path.join(experiment_path, 'best_model.pth')
with S3(s3root = experiment_cloud_storage_path) as s3:
s3.put_files([(path_to_best_model, path_to_best_model)])
3Resuming the Best Model State
The payoff of checkpointing in this way is that now you can easily resume the model from this state.
In a notebook or Python script you can now evaluate the model, train it further, or iterate on the model architecture (PyTorch allows you to build dynamic graphs).
from hagrid.classifier.run import _initialize_model
from omegaconf import OmegaConf
model_path = 'best_model.pth'
try:
model = _initialize_model(
conf = OmegaConf.load('hagrid/classifier/config/default.yaml'),
model_name = 'ResNet18',
checkpoint_path = model_path, # can be local or S3 URI.
device = 'cpu'
)
except FileNotFoundError:
print("Are you sure you trained a model and saved the file to {}".format(model_path))
Because of how the TrainHandGestureClassifier uses Metaflow's built-in versioning capabilities, we can also resume model training with the --checkpoint parameter when you run the TrainHandGestureClassifier defined in classifier_flow.py.
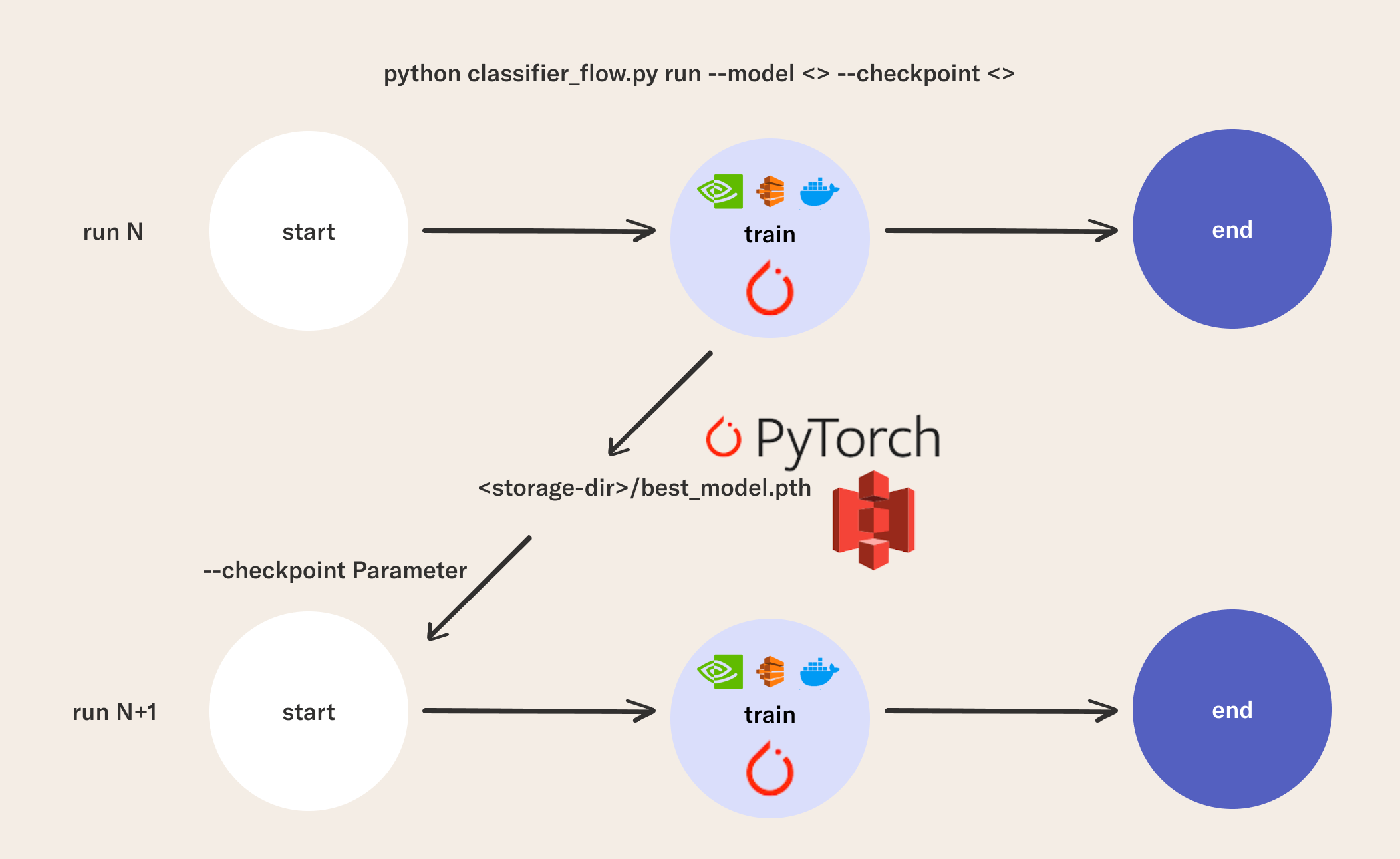
This checkpoint parameter can either be a .pth file in an S3 bucket or a path to a local .pth file. In general, you can add arbitrary parameter types like this to your Metaflow flows in one line of code. This helps you write flexible code that can read in data from external systems in a variety of ways.
python classifier_flow.py --package-suffixes '.yaml' run --epochs 1 --model 'ResNet18' --checkpoint 'best_model.pth'
In this lesson, you saw how to ensure you don't lose progress as you iterate on your model using checkpoints. You learned how to store model checkpoints and resume that state from a notebook or as the starting point in a subsequent flow. In the next lesson, we will complete the tutorial by demonstrating the use of TensorBoard's experiment tracking solution with Metaflow.