What is Cross-validation?
A Reminder on Supervised Learning
Recall that supervised learning is the subset of machine learning in which you’re predicting a label: If you’re predicting a categorical variable, such as “click” or “not” for website conversion rate, or “benign” or “malignant” for diagnostic imaging of tumors, the task is known as classification; If you’re predicting a numerical variable, such as the price of a property or the lifetime value of a customer, the task is known as regression; In both cases, you’ll need to have a robust way to gauge the performance of any model you build and cross-validation is one such method.
Training Data, Accuracy, and Cross-validation
To build a supervised learning model, you require two things:
Training data (which the algorithms learn from) and An evaluation metric, such as accuracy. After training your algorithm on your training data, you can use it to make predictions on a labeled holdout (or test) set and compare those predictions with the known labels to compute how well it performs.
You can also use a technique called (k-fold) cross-validation (CV), where you train and test several times using different holdout sets and compute the relevant accuracies:
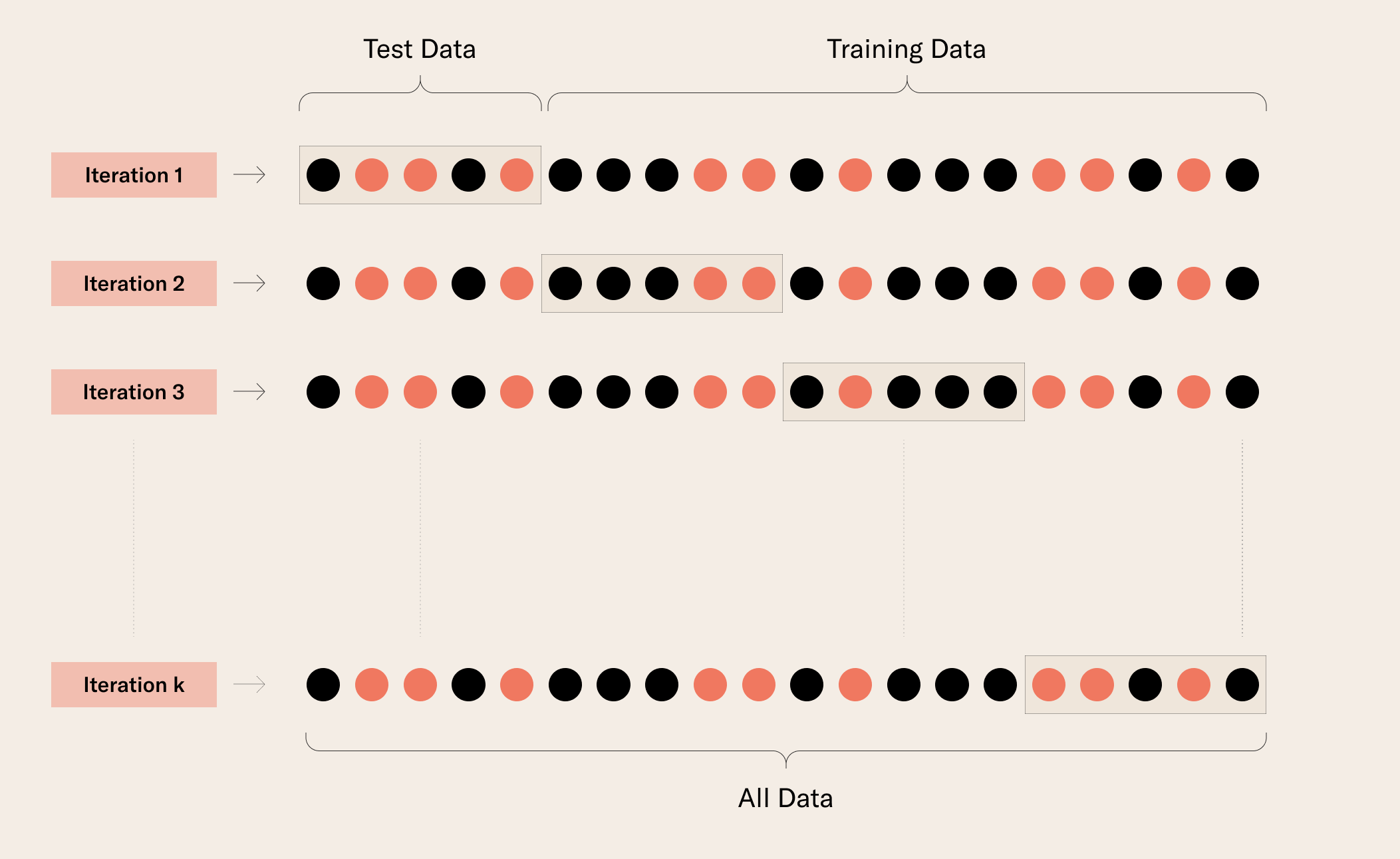
The algorithm for k-fold cross-validation is as follows:
- You split your labeled data into k subsets S_1, … , S_k;
- For each i,
- You hold out S_i,
- You train your model on the rest of the data
- You compute the accuracy of your trained model on S_i
- This gives you k accuracies for your model, which tells you how well your model performs on unseen data and hence how it generalizes!
As we discuss below in the section Practical notes on using CV, in many situations you should use both a holdout in addition to CV.
As cross-validation is strictly more expensive than a simple one-fold test/train split, it’s a good question as to why we want to do it in the first place. The answer is that it is both helpful to reduce the chance of overfitting and it also allows us to retrieve statistics on model performance, such as median accuracies and percentiles.
Practical Notes on Using Cross-validation
- The more folds you use, the more certainty you will have about your model performance BUT also: the more folds you use, the more computationally intensive your k-fold CV is as the more models you train!
- For classification tasks, you’ll most likely want to use stratified cross-validation, which preserves the target variable across folds so that, for example, you don’t get one fold with one target variable for all data points. Major packages for supervised learning, such as scikit-learn in Python and tidymodels in R, have APIs to access stratified CV.
- Cross-validation is often used with grid search, randomized grid search, and other methods of hyperparameter optimization.
- If you are using CV to make any decisions like model selection (for example, using hyperparameter tuning), you also need to set aside a holdout set to evaluate the final performance of your model in order to avoid overfitting. Moreover, after you have found the best model using CV, you want to retrain your models on the entire training data before moving it to production.
- Cross-validation for time series works differently! A common mistake in data science is applying traditional CV to time series. See Rob Hyndman’s post about CV for time series here for further details.
How do I?
Use Metaflow to train a model for each cross-validation fold