Python Data Structures for Tabular Data
Many data science applications deal with tabular data that looks something like this:
| Name | Credit score | Last login | Balance |
|---|---|---|---|
| Jane Smith | 852 | 2022-02-03 18:32 | 131.0 |
| John Smith | 765 | 2022-05-15 09:03 | 72.5 |
Note how each column has a uniform data type. In this example, the Name column contains strings, Credit Score integers, Last login timestamps, and Balance floating point numbers. The metadata about column names and types are called the schema. Often, structured or relational data like this is stored in a database or a data warehouse where it can be queried using SQL. In the past, it wasn’t considered wise to try to process large amounts of data in Python. Thanks to increasing amounts of memory and CPU power available in a single computer - in the cloud in particular - as well as the advent of highly optimized libraries for data science and machine learning, today it is possible to process even hundreds of millions of rows of tabular data in Python efficiently. This is a boon to data scientists, as they don’t need to learn new systems or programming languages to be able to process even massive data sets. Don’t underestimate the capacity of a single large server! However, some thinking may be required to choose the right library and data structure for the task at hand, as Python comes with a rich ecosystem of tools with varying tradeoffs. In the following, we will go through five common choices as illustrated by the figure below:
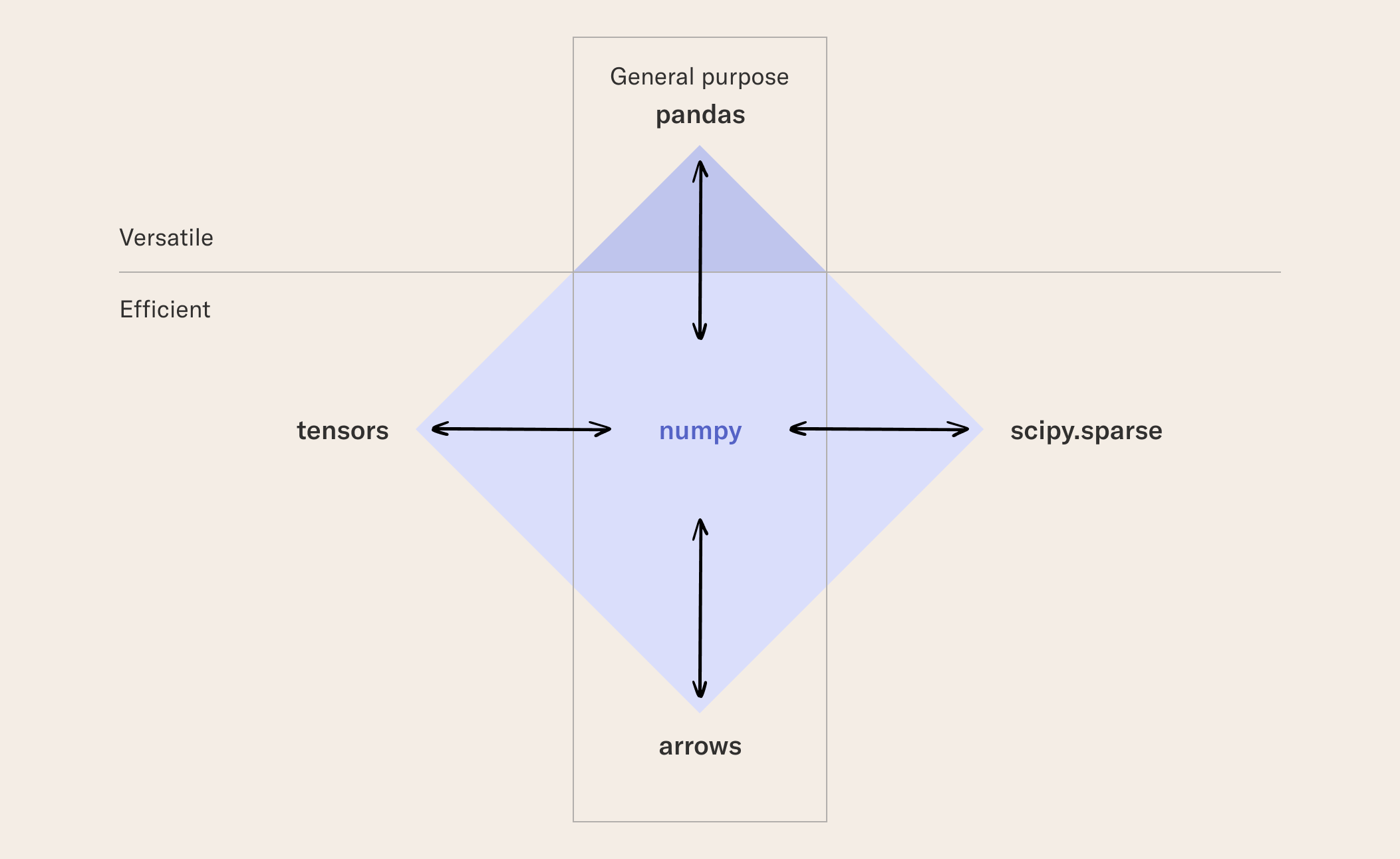
pandas is the most common library for handling tabular data in Python. pandas is a dataframe, meaning that it can handle mixed column types such as the table presented above. It adds an index over the columns and rows, making it easy to access particular elements by their name. It comes with a rich set of functions for filtering, selecting, and grouping data, which makes it a versatile tool for various data science tasks. A key tradeoff of pandas is that it is not particularly efficient when storing and processing data. In particular when the dataset is large, say, hundreds of megabytes or more, you may notice that pandas takes too much memory or too much time to perform desired operations. At this point, you can consider more efficient alternatives as listed below.
NumPy - Efficient, Interoperable Arrays for Numeric Data
NumPy is a performant array library for numeric data. It shines at handling arrays of data of uniform types - like individual columns of a table. In fact, pandas uses NumPy internally to store columns of a dataframe. NumPy can also represent higher-dimensional arrays which can come in handy as an input matrix, e.g. for model training or other mathematical operations. Under the hood, NumPy is implemented in the C programming language, making it very fast and memory-efficient. A downside is that it comes with a more limited set of data processing operations compared to a dataframe like pandas. A key upside of NumPy is that it can work as a conduit between various libraries. Most data science libraries in Python, such as SciKit Learn, can use, import, and export NumPy arrays natively. Many of them are smart enough to leverage NumPy in a manner that doesn’t require data to be copied explicitly, which makes it very fast to move even large amounts of data between libraries through NumPy.
Arrow - Efficient, Interoperable Tables
Apache Arrow is a newer, performance-oriented library for tabular data. In contrast to NumPy it can handle mixed columns like pandas, albeit as of today it doesn’t come with as many built-in operations for data processing. However, if you can express your operations using the Arrow API, the result can be much faster than with pandas. Also, thanks to Arrow’s efficient way of representing data, you can load much more data in memory than what would be possible using pandas. It is easy and efficient to move data between pandas and Arrow or NumPy and Arrow, which can be performed in a zero-copy fashion.
Scipy.Sparse - Efficient Sparse Arrays for Numeric Data
The three libraries above are general-purpose in a sense that they come with a rich set of APIs and supporting modules that allow them to be used for a wide range of use cases. In contrast, Scipy.Sparse is a more specialized library, targeted at handling sparse matrices i.e. numeric arrays where most values are empty or missing. For instance, a machine learning model may take an input matrix with tens of thousands of columns. In such cases, it is typical for most columns to be empty for any particular row. Processing such a dataset as a dense array e.g. using NumPy may be impractical due to a large amount of memory being consumed by empty values. If you use a library that is compatible with Scipy.Sparse matrices, such as XGBoost or Scikit Learn, sparse matrices may allow you to handle much larger datasets than what would be feasible otherwise.
Tensors and Other Library-specific Arrays
Modern machine learning libraries like XGBoost, TensorFlow, and PyTorch are capable of crunching through a huge amount of data efficiently but configuring them for peak performance requires effort. You need suitable data loaders that load raw data into the model, as well as specialized to facilitate data movement within the model. For optimal performance, you are often required to use library-specific data structures, such as DMatrix for XGBoost, or various tensor objects in deep learning frameworks. These data structures are optimized for the needs of each particular library, which limits their usefulness as a generic way to store and process data. Fortunately, it is often possible to move data from tensors to NumPy arrays efficiently and vice versa.
Choosing the Library
Here’s a simple rubric for choosing the right library for the job: Do you use a deep learning library? If yes, use library-specific objects and data loaders. Is your data small enough not to require special treatment (if you are unsure, assume yes)? Use pandas. Is your large data numerical and dense? Use NumPy. Is your large data numerical and sparse? Use Scipy.Sparse. Otherwise use Arrow. Note that in all these cases you can scale to larger datasets simply by requesting more resources from the cloud using Metaflow’s @resources decorator.
How do I?
Pass XGBoost DMatrix between Metaflow steps
Understand common file formats for tabular data