




Authors

Infrastructure for Agentic Code
April 6, 2026
Outerbounds provides the structured, secure foundation that AI agents need to produce high-quality code quickly and reliably. If you're in a hurry, scroll down to see an example of a complete, production-grade system built by Claude on Outerbounds.
Imagine you are given the following task:
Our company maintains a continuously updating table of leads (company profiles) in a data warehouse. Each lead needs to be enriched with semantic tags derived from the company’s website. Given the volume of records processed daily, running a small local LLM is preferable to calling an external model endpoint, both for cost control and operational predictability. Beyond writing the enriched attributes back to the warehouse, can you make the data explorable through an internal dashboard?
You recognize this as a typical data or ML/AI system: a few batch workflows for data preparation and compute-intensive parallel processing, complemented by an online service hosting the UI:
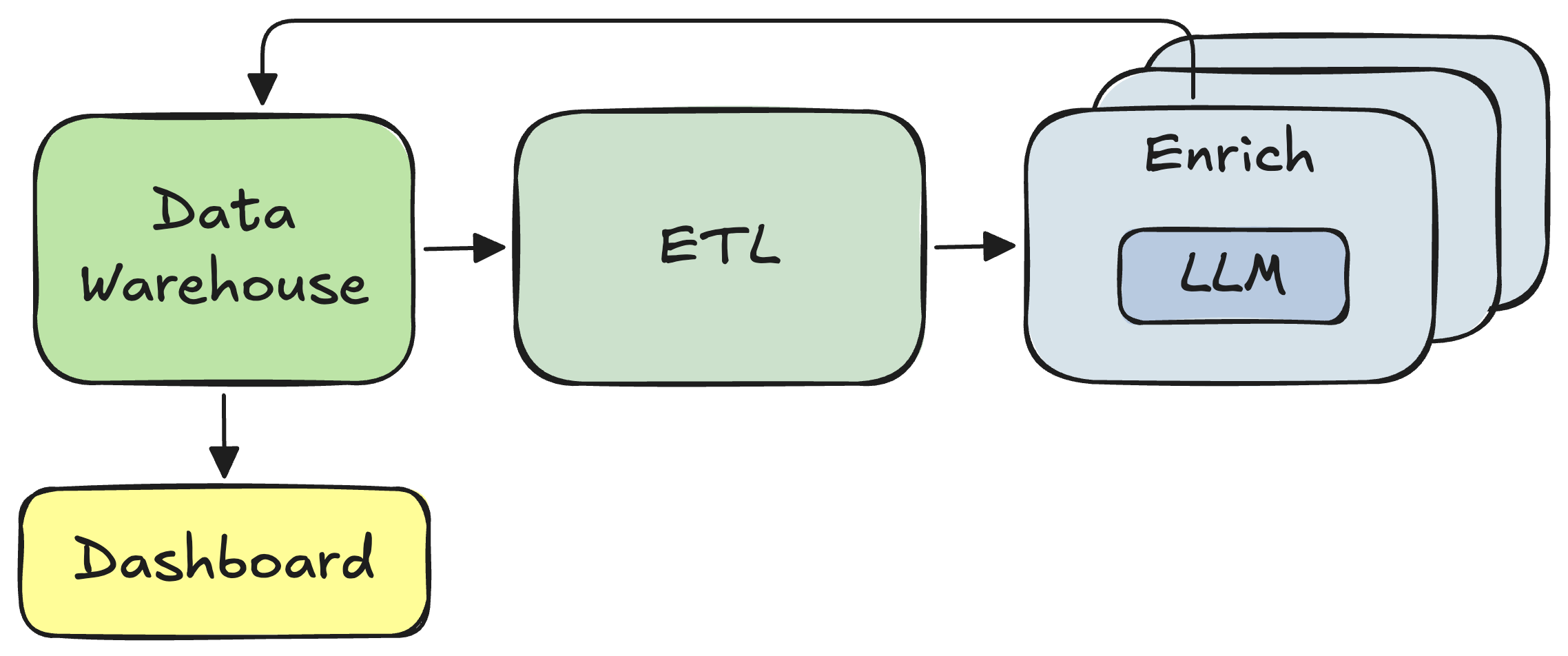
Conceptually, the system looks pretty straightforward. The implementation shouldn’t be too complicated either: Some SQL for ETL and a Python wrapper around a local LLM for inference. There are plenty of easy UI libraries that can be used for the dashboard.
You are glad it’s 2026. You can just ask Claude Code (or another coding agent) to build the system while you enjoy a long lunch.
Unleash the agent
Before heading out, you decide to be a prudent AI architect and ask the agent to present its implementation plan first. You copy-paste the above problem description into the most powerful frontier model (Opus 4.6) and ask it to design a system that you can deploy for production.
After three minutes of thinking, the agent outputs a proposed architecture:

This surely looks more complex than anticipated!
At a high level, the plan seems reasonable, but maybe overengineered. You may not feel fully confident about what exactly should be changed.
Undoubtedly you would feel uneasy about handing over your AWS credentials and letting the agent implement the plan autonomously. Yet, you don’t look forward to manually reviewing all the code the agent would generate.
Worse, you get the heebie-jeebies thinking about the potential cost and security implications of letting this loose in your AWS account - and the burden of having to maintain the beast over time.
A jack of all trades, not a master of complex systems
As of early 2026, the best models achieve roughly a 40% success rate when working with complex codebases. These benchmarks exclude infrastructure-heavy scenarios, where success rates would likely be even lower.
This is notably worse than performance on simpler coding tasks, where success rates approach 80%. Beyond the inherent complexity, infrastructure changes involve much longer trial-and-error cycles than purely local, easily verifiable code modifications. The resulting slower feedback loops help explain part of the gap.
In other words, it is highly unlikely that even the most capable coding agent could, as of today, build a system like the above fully autonomously without human guidance. To amplify the issue, a challenge is that when the agent gets stuck, unblocking it requires fairly deep infrastructure expertise to understand the architecture the agent is going after. Without sufficient human expertise, the developer may find themselves trapped in a frustrating loop of back-and-forth debugging with the agent.
The old saying applies to today’s coding agents: A high IQ is like a jeep. You’ll still get stuck — you’ll just be farther from help when you do.
Not only a skill issue
Extrapolating from the rapid progress of AI copilots over the past few years, it is easy to argue that agents should be able to build complex systems nearly flawlessly within a year or two.
An experienced distributed systems engineer might point out that infrastructure is subject to far more entropy, complexity, and unforgiving real-world constraints than closed-loop coding. Hence it may be fundamentally harder for agents (as it is for human developers). But for the sake of argument, let’s assume that agents reach the level of a senior systems engineer.
Working with infrastructure is not only a skill issue. Infrastructure encodes an intricate set of organizational policies, preferences, and requirements — it acts as a shared language that embodies the company’s technical culture. Hence it is fundamentally a shared environment, not a single-player sandbox where agents (or human developers) can change things at will, even if they were technically capable.
This point was made recently by the CEO of Linear as well:

Instead of letting agents roam free, you want to clearly define and enforce the infrastructural boundaries within which agentic code can be developed and operated with confidence. In the words of a recent blog post by OpenAI about Harness Engineering: “Agents are most effective in environments with strict boundaries and predictable structure”.
The boundaries and predictable structure provide three key benefits:
- It significantly reduces the technical surface area exposed to agents. Since agents perform best in closed-loop coding environments, it makes sense to let them focus there rather than having them assemble everything from scratch, in particular with infrastructure with long feedback cycles, which increases the likelihood of producing high-quality results quickly.
- A shared, stable foundation reduces maintenance and ownership costs by limiting the number of moving parts and the amount of entropy.
- Infrastructure defines the policies and the shared rulebook of the organization, which makes it easier for humans and agents to collaborate.
Notably, these points will remain true even as agents reach the level of a senior systems engineer in the coming years — and even more so if they won’t.
Outer bounds for data- and compute-intensive agentic code
Outerbounds provides a structured platform layer on top of raw cloud infrastructure, exposing a unified set of APIs and services that give agentic code clear boundaries, reliable primitives, and, in particular, a secure operating environment.
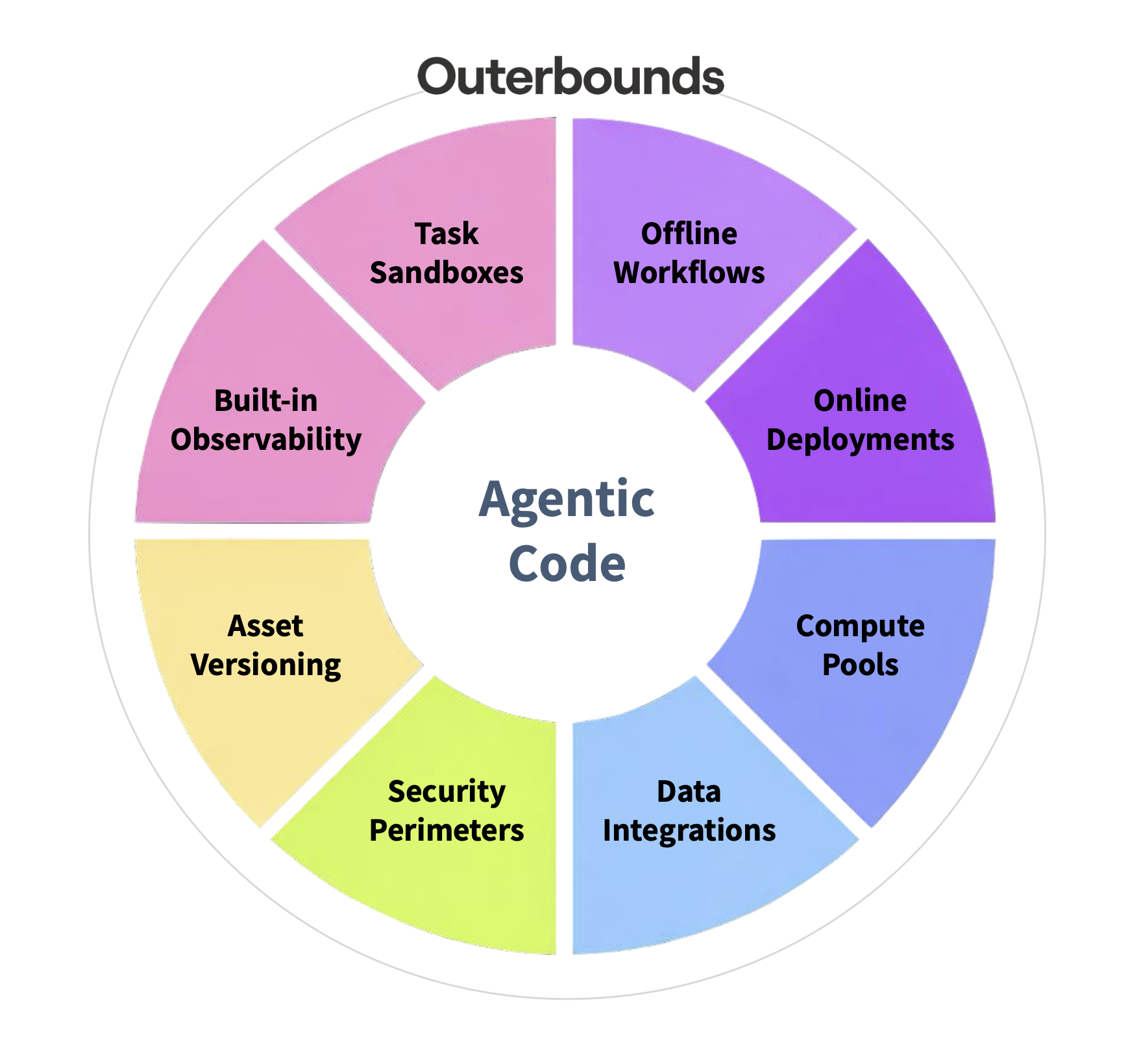
While a number of other platforms, such as Lovable and Replit, provide an agent harness for web applications and typical SaaS services, Outerbounds focuses on data- and compute-intensive applications, such as data processing, ML, and AI.
Outerbounds standardizes versatile offline workflows for heavy lifting, online deployments, secure data access, scalable compute (including container management), and observability, allowing agents to focus on generating high-quality application logic instead of attempting to assemble fragile infrastructure from scratch, as illustrated by an agent’s messy attempt earlier in this article.
Importantly, this operating environment for agentic code is deployed securely across your own cloud accounts, ensuring data and model privacy, compliance, and cost-effective compute. You can define secure boundaries for agentic code through perimeters, and execute agents themselves in tightly governed sandboxes.
As a result:
- Humans can define secure, scalable, and cost-efficient services and boundaries for agentic code, aligned with organizational policies, preferences, and requirements, within their familiar environment and integrated with their existing infrastructure.
- Agents operate within clear boundaries and a predictable structure, allowing them to produce accurate results faster and more reliably, using fewer lines of cleaner code that are easier for humans to review.
Example: The data enrichment system done right
Let’s return to the example from the beginning of this article. Instead of asking an agent to hack together a solution from scratch, we ask it to build the system on Outerbounds to highlight the benefits of clear boundaries and a consistent set of APIs.
You can view and reproduce the results yourself using this repository.
Setup
We ask the agent to follow the canonical structure of Outerbounds Projects, which brings all parts of the system — offline and online components, code, dependencies, and supporting assets — into a single repository. We provide instructions for doing this through a straightforward SKILL.md file.
You can see the prompt describing the task, elaborating the first paragraph of this article, in our CLAUDE.md file. To help the agent locate the relevant data, we include a six-line query snippet (without the correct SQL — the agent has to figure that out on its own), which leverages an existing secure connection between Outerbounds and our Snowflake instance.
Execution
After providing the above concise context for the agent, we let it rip:
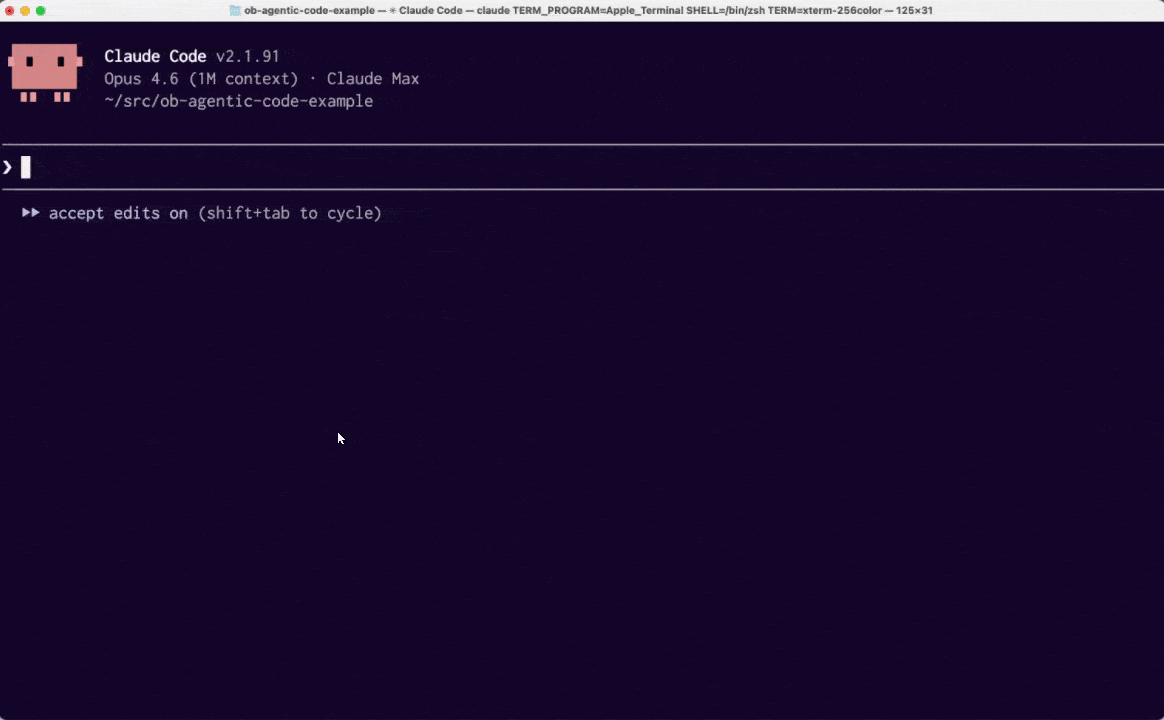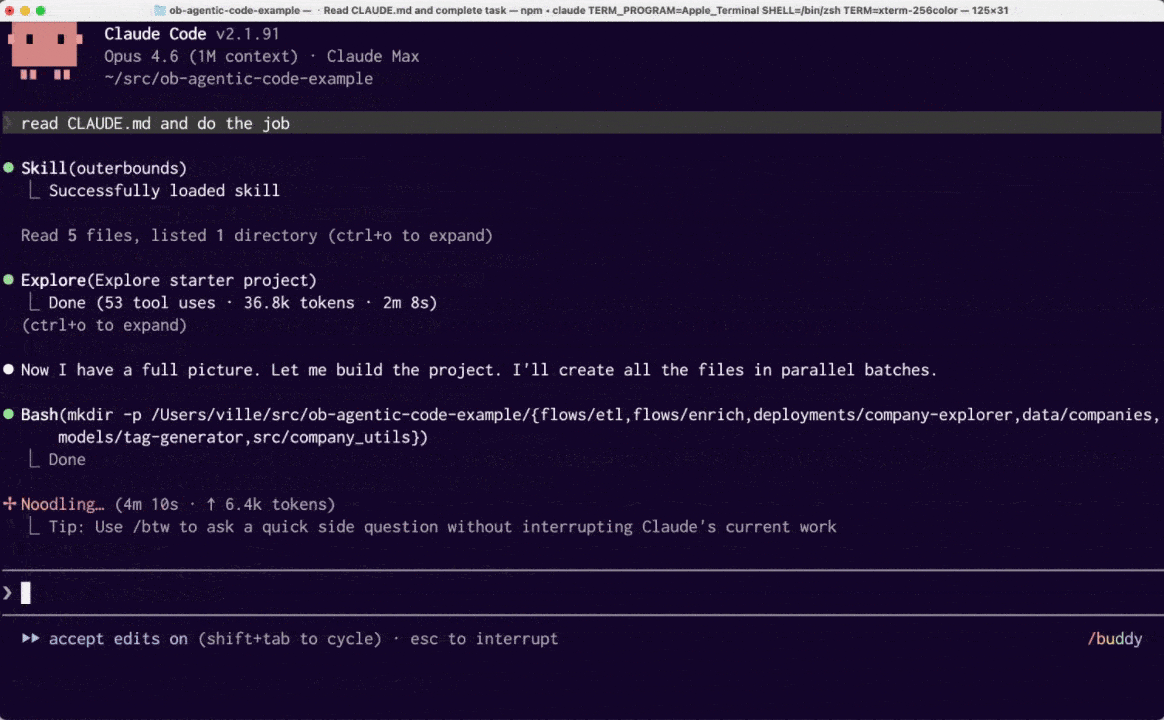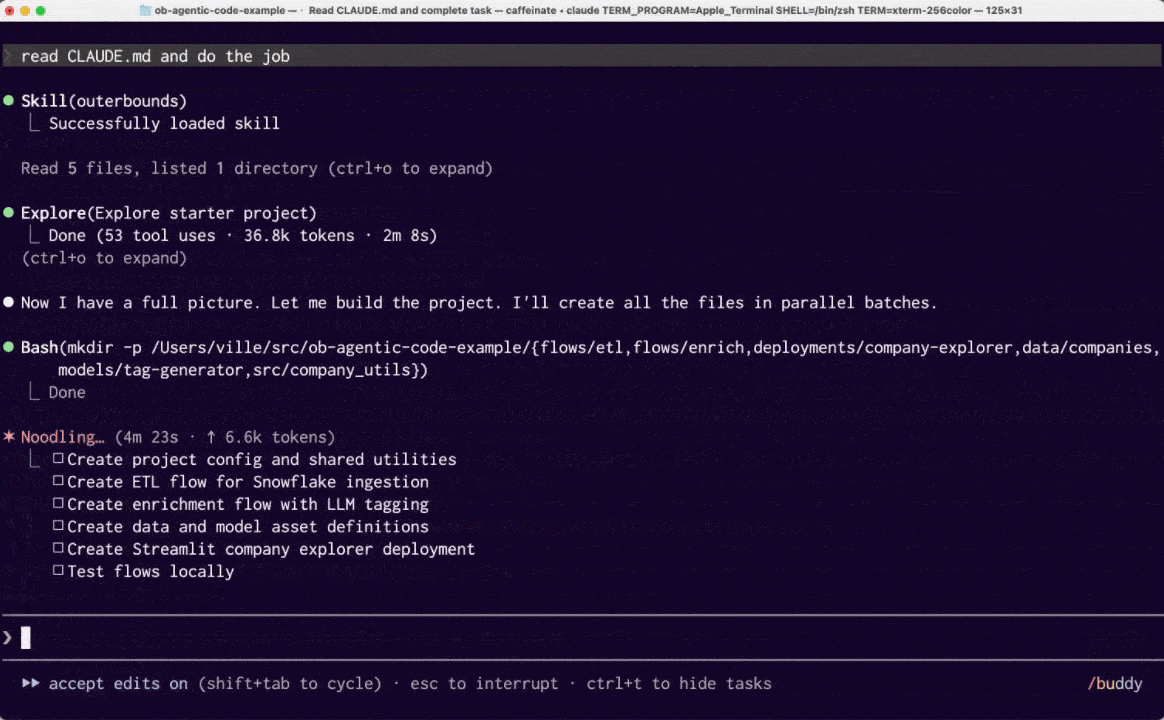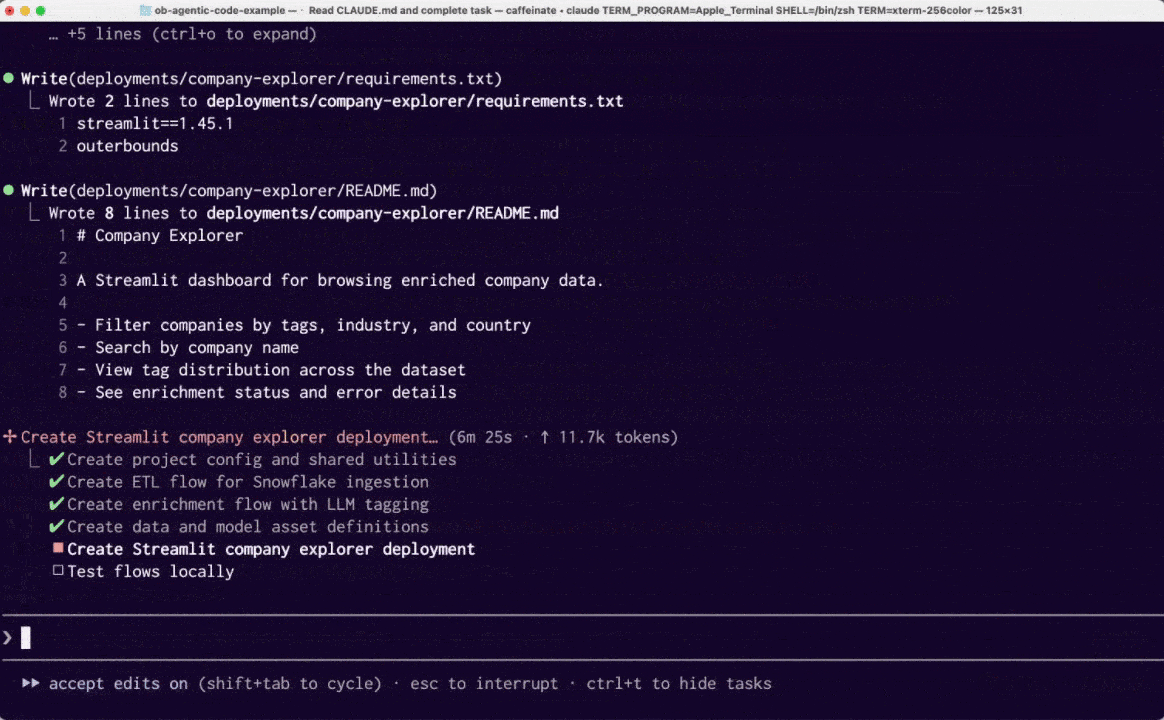
Claude spends about 3 minutes studying the Outerbounds project documentation and an example project. It identifies the required components correctly and implements the first versions in another 3 minutes.
A major benefit of Outerbounds, thanks to Metaflow, is the ability to test code locally without requiring a full deployment roundtrip. Features such as quickly testing individual steps with spin — originally implemented by Netflix to accelerate human development cycles — benefit agents even more by enabling quick local testing.
Agents tend to make small mistakes that they can often fix independently once they see the resulting errors, much like human developers. In this case, the agent spent another two minutes iterating on the code locally before converging on a working solution.
Codebase
After about 10 minutes of autonomous coding, the agent was done. Compared to the hairball of duct-taped services it had proposed in the absence of a proper harness, the resulting codebase is remarkably clean and maintainable:
flows/
- snowflake-etl (triggered hourly)
- company-enricher (triggered by snowflake-etl)
deployments/
- company-explorer (fetches results of company-enricher)
src/
[shared utilities]
data/
[track raw and enriched data assets]
models/
[track the local LLM used for enrichment]
No infrastructure boilerplate is required — just about 600 lines of readable and easily maintainable Python. Yet the system comes with enterprise-grade SLAs and security guarantees provided by the platform. The agent can focus on the business logic, as it should.
We chose not to let it deploy automatically, although it would be straightforward to set up a Karpathy-style fully autonomous AutoResearch environment with cost-efficient GPUs on Outerbounds. Instead, we committed the files manually and pushed them through a built-in CI/CD integration.
Notably, we didn’t review the code at this stage, since the entire system was deployed as an isolated Outerbounds branch, allowing us to observe the results safely in a live environment first. We noticed a few cosmetic issues in the Company Explorer UI (tags were not formatted correctly) and in cards showing tagging progress (tags were not shown initially), which the agent fixed promptly.
The complete system on Outerbounds
The following video shows a quick walkthrough of the system after it was deployed on the platform. You will see:
- The project overview, including auto-generated documentation.
- The latest data assets for both raw and enriched datasets.
- The most recent run of the
CompanyEnricherflow, showing the live status of the parallelized enrichment process. - The
Company Explorercustom UI (implemented with Streamlit), deployed as a platform app, which allows you to browse, filter, and search enriched company data.
Notably, not a single line of code or infrastructure configuration in this fully production-ready, continuously running, and reliably executing system was written by a human:
Continuous improvement
While it is impressive to see a production-ready system being few-shotted by an agent, a truly effective platform must take you further. As we have frequently highlighted, the real goal is to establish a closed loop of continuous improvement across all parts of the system. The first deployment is just the beginning, not the end.
If the company enrichment system were a real production project, it would require continuous iteration, with or without agents. Data changes, models evolve, business logic gets updated, and bugs inevitably surface. In all of these cases, you need a systematic way to test, validate, and roll out new versions safely to production.
This is why Outerbounds allows you to deploy any number of systems, cleanly defined as Git branches, to run side by side:
Crucially, you need the ability to isolate every part of the agent harness — data, compute, deployments, assets, and observability — since you cannot assume agents will behave responsibly by default. Outerbounds provides this isolation out of the box.
Welcoming our agentic co-workers
Five years ago, we founded Outerbounds with the vision of providing a productivity-enhancing environment for data scientists and ML practitioners working with high-entropy assets such as models and large-scale, continuously evolving data. Equally importantly, the characteristics of this environment — including company policies and preferred ways of working — needed to be easily definable and enforceable by platform and DevOps teams. Hence the name Outerbounds.
Fast forward to 2026, and this vision is more relevant than ever. Interestingly, it is primarily the insides of these environments that are rapidly being augmented, and sometimes taken over, by agents. In contrast, this shift has only increased the importance of humans being able to define the harnesses available to agents and to establish the outer bounds within which code can be generated and executed with confidence.
If you want to fast-forward to 2026 and beyond and start providing robust infrastructure for agentic code in your own secure environment, you can deploy Outerbounds in your own cloud today.

Start building today
Join our office hours for a live demo! Whether you're curious about Outerbounds or have specific questions - nothing is off limits.
We can't wait to meet you soon! Keep an eye out for a confirmation email with the deets.






