




Authors
.jpeg)
Developing Standout AI on Outerbounds and CoreWeave
August 28, 2025
Our CoreWeave integration makes it effortless to add top-tier, cost-efficient GPUs to your existing cloud account, minimizing data egress fees and I/O bottlenecks. Powered by our optimized proxy and CoreWeave’s native high-performance object store, this setup enables faster, more efficient training and inference workflows, running on GPUs at scale. Read the article to see how it works in practice.
Over the coming decade, every new product or service will integrate some form of AI. In some cases, AI will drive the entire system—such as a voice-controlled travel agent that autonomously plans and books trips. In other situations, AI will be used to enhance specific components, like automating the evaluation of loan applications in a tightly regulated fintech platform.
Some lightweight AI use cases are served well by off-the-shelf APIs or domain-specific services. Other, more innovative AI developers will realize that standing out in a crowded AI market requires going beyond generic solutions. That’s where Outerbounds and CoreWeave can help.
Evolving standout AI systems
Building differentiated product experiences is always an iterative journey. While creating ad-hoc AI demos using off-the-shelf APIs (Stage I in the diagram below) is relatively easy, many companies realize that incorporating their own data effectively, whether through RAG or other forms of context engineering (Stage II) requires significantly more effort.
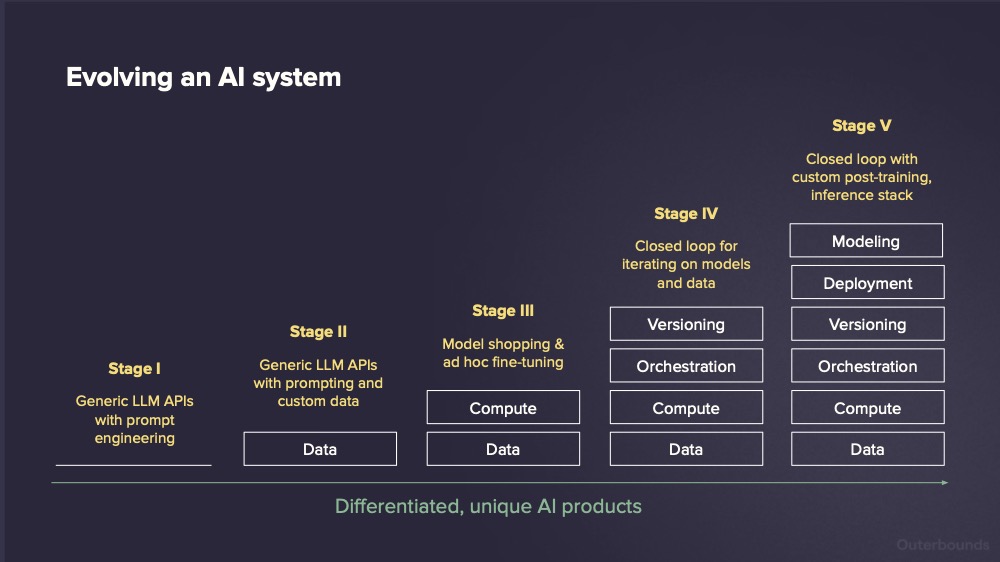
Infrastructure complexity reaches a new level at Stage III once your systems demand any amount of GPU compute, whether for fine-tuning, reasoning agents, or high-throughput inference. While many teams begin with ad-hoc notebooks and a handful of GPU instances, such setups quickly become bottlenecks: They don’t support fast iteration, scalability, or cost-efficient operations.
To move fast and build reliable AI systems, you need Stage IV. This means evolving beyond scattered prompts, datasets, and disorganized context engineering. You need structured, continuously running data pipelines; a compute platform that can provide fleets of GPUs for both training and inference; and an environment where data, code, and compute can evolve rapidly with proper CI/CD integration and GitOps best practices.
Outerbounds delivers a Stage IV-grade AI platform as a managed service, running securely in your own cloud accounts. Paired with CoreWeave, it gives you access to industry-leading GPU infrastructure— that is seamlessly integrated into a cohesive developer experience, built on the battle-tested foundation of open-source Metaflow. This combination lets you build, iterate, and ship differentiated AI products powered by your own fine-tuned models, inference, proprietary data, and cutting-edge agents—even for sensitive use cases—thanks to the SOC 2 and HIPAA compliance of the full stack.
If you aim to go even further and develop your own models and advanced inference patterns (Stage V) rest assured that CoreWeave powers frontier labs like OpenAI, so you’re unlikely to run into infrastructure limits.
The CoreWeave + Outerbounds Stack
Outerbounds is the platform of choice for top AI and ML teams at companies serious about their infrastructure. It runs securely in your cloud accounts, providing a unified control plane that seamlessly integrates your hyperscaler environments (AWS, Azure, or GCP) with your CoreWeave account.
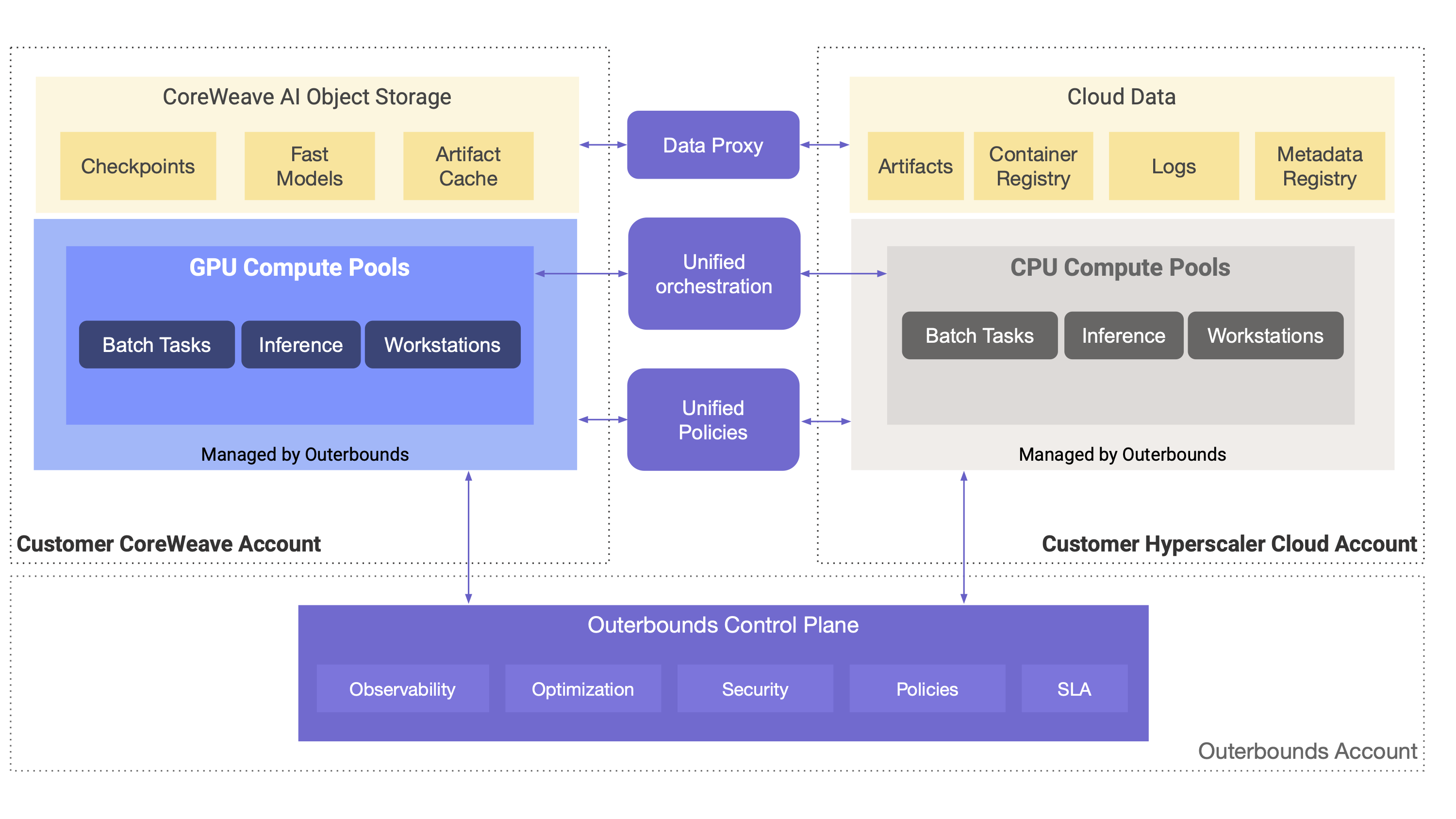
This setup allows you to attach large-scale, top-notch compute resources running on CoreWeave directly to your existing cloud account, without having to learn new infrastructure, change policies, or code. Key features of this setup allow you to:
- Mix and match CPU and GPU resources across CoreWeave and hyperscalers, even within a single workflow. Or, you can decide where to run experiments without changing anything in the code.
- Scale out to thousands of parallel GPU nodes or tens of thousands of GPU cores and leverage distributed training and inference with built-in support for PyTorch and Ray with robust and versatile checkpointing.
- Build production-grade scheduled or event-triggered workflows that leverage GPUs on CoreWeave, ingesting data from your production data warehouse or lake, such as Databricks or Snowflake, e.g. to power data pipelines, batch inference, or continuous training - respecting your existing data governance policies and boundaries.
- Develop on cloud workstations using notebooks or VSCode, backed by CoreWeave.
- Observe, track, and version experiments and production with real-time logs, custom reports, and comprehensive lineage and artifact tracking, consistently across CoreWeave and hyperscaler clouds.
- Deploy real-time inference endpoints on CoreWeave clusters, benefiting from centralized authentication and authorization, connected to your SSO provider through the control plane, as well as high-throughput batch and autonomous inference.
- Experiment with the whole software stack quickly with automatically baked container images and fast registry, allowing you to go from requirements.txt to running GPU tasks faster than ever before.
- Leverage your existing IAM policies on CoreWeave, minimizing the operational burden and the cost of adoption.
- Adopt CI/CD and GitOps best practices for all layers of a modern AI system, including code, data, and models.
- And, deploy production-grade agent environments.
Together, these features form a cohesive development experience and operational stack, enabling teams to rapidly iterate their way to differentiated AI.
Moving data across clouds efficiently
A common objection to cross-cloud operations is data movement.While CoreWeave may provide the best GPU clusters on the market, it is hard to utilize them fully if your data is stuck in existing data warehouses and hyperscaler object stores.
CoreWeave offers a high-performance object store, CoreWeave AI Object Storage, which is optimized for fast I/O within CoreWeave. To take full advantage of it, you need to populate it with your existing data. While many teams start by copying data manually, ad-hoc transfers quickly become a bottleneck, potentially slowing iteration, compromising hygiene, and complicating data governance.
To fix this issue, Outerbounds provides a transparent proxy (effectively a read-through cache) between hyperscaler object stores and CoreWeave AI Object Storage. For example, you can accessAWS S3 in your code as usual, and the proxy will cache the data in CoreWeave AI Object Storage automatically to speed up future data access and to remove accumulating data egress costs.
Thanks to our long-term experience in optimizing object store access, combined with the excellent performance afforded by CoreWeave AI Object Storage, we were able to optimize the proxy for maximum throughput:
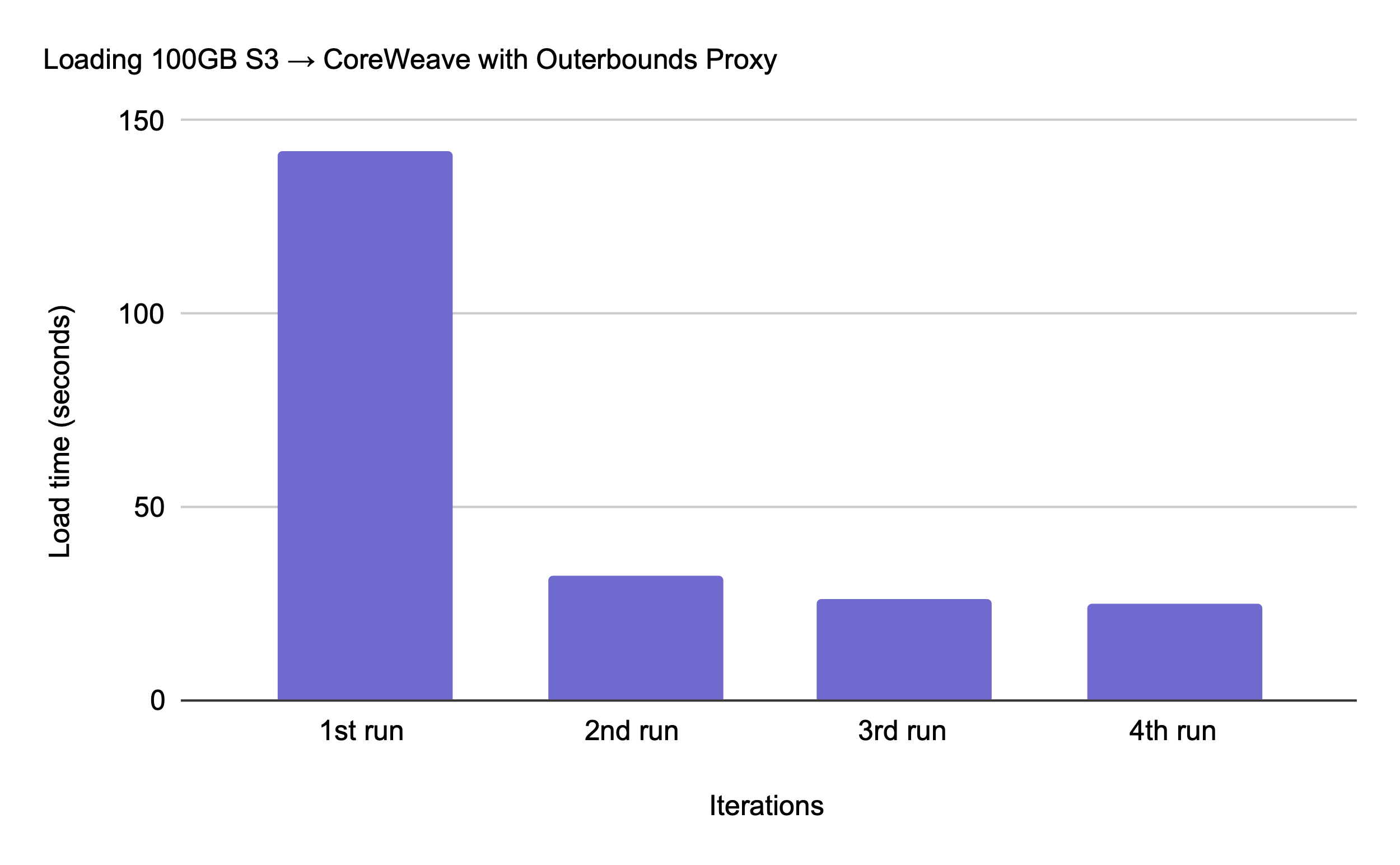
The chart above shows an example case of loading 100GB of data from AWS S3 to a task running on CoreWeave. The initial download takes 145s, crossing the datacenters, so the throughput is about 5.4Gbit/s, leveraging Metaflow’s built-in optimized S3 client. The subsequent downloads (no changes in the code required) produce a cache hit in CoreWeave AI Object Storage which can deliver 32Gbit/s to the pods.
Remarkably, the setup allows you to load data directly from AWS S3 into GPU VRAM without slowdowns from local disk IO:
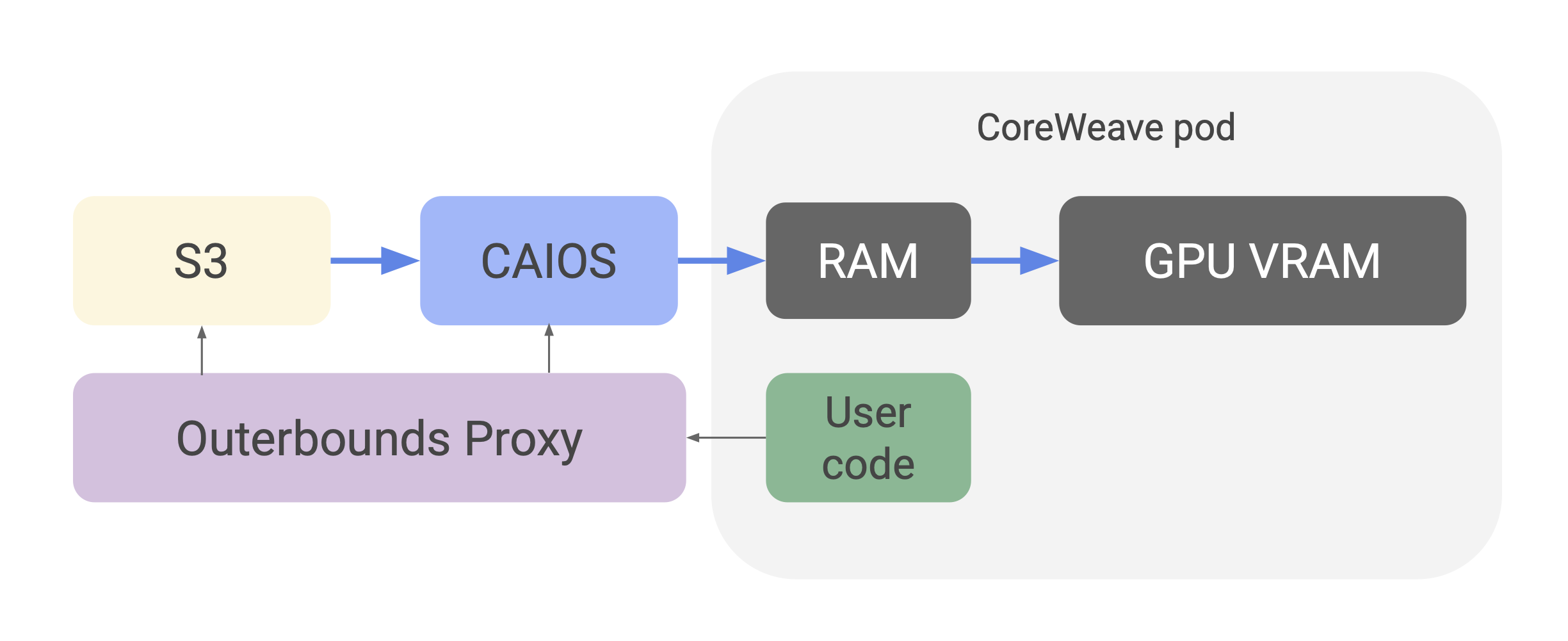
Subsequent I/O operations between CoreWeave AI Object Storage and GPUs deliver maximum data loader performance, effectively eliminating I/O bottlenecks.
On the upload side, Metaflow’s built-in support for checkpointing (@checkpoint) is optimized to support the proxy, so you can benefit from fast checkpoint saving and recovery seamlessly with CoreWeave AI Object Storage when finetuning GenAI models or training your custom deep learning models.
Example use case: Autonomous inference
With the infrastructure in place, you can use the platform to build and run business-critical AI systems. A common use case is large-scale autonomous inference, such as processing hundreds of millions of documents using anything from a simple LLM prompt to a complex, agentic workflow for deep research. Or, you might generate millions of product images or hours of video using diffusion models.
The default Stage II approach to batch inference is to use an off-the-shelf API - many providers offer best-effort endpoints for batch processing. However, this approach often comes with several limitations:
- Low throughput may cause processing to take hours, slowing down experimentation considerably.
- Cost may be prohibitive, especially with more complex workflows and longer documents, which yield many input and output tokens.
- Variable throughput can hinder applications that require more predictable performance when processing takes anywhere from minutes to hours.
- Security and compliance can hinder teams from sending sensitive data to an outside provider, especially the ones who may use the data for improving their models.
- Need for custom models and workflows can also be a blocker. You may want to leverage custom fine-tuned models or more complex workflows which are not supported by off-the-shelf APIs.
With the Outerbounds+CoreWeave stack, you gain a powerful alternative to the typical Option 1, depicted below. Thanks to our optimized batch inference operator, @vllm, Outerbounds enables high-throughput batch inference on your own CoreWeave clusters, seen in Option 2 below. Instead of relying on third-party AI APIs with unpredictable performance and scaling, you can deploy dedicated models tailored precisely to your workloads.

The performance gains can be dramatic. In a benchmark comparing batch inference on CoreWeave to a leading inference provider,using the same workload and open-weight model, we saw a 6x improvement in median processing time (3.2s vs. 20.7s).
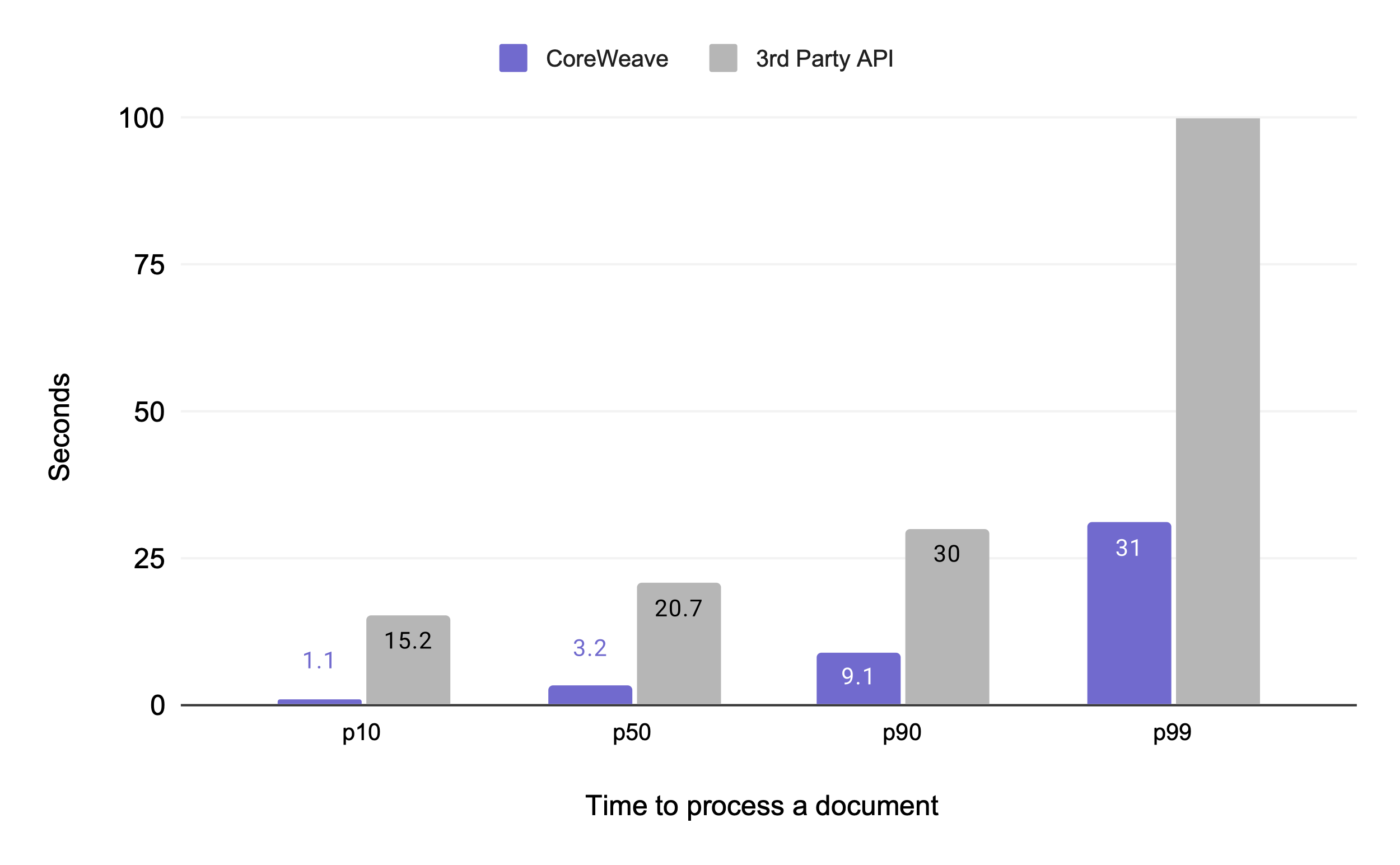
As expected with serverless services, the external provider’s p99 latency exceeded 10 minutes, leading to unpredictable slowdowns. In contrast, our dedicated CoreWeave cluster kept the p99 latency to a consistent 30 seconds.
Get started with minimal DevOps effort
Outerbounds deploys in your cloud account in minutes with just a few clicks. Once set up in your AWS, Azure, or GCP account, you can request a connection to CoreWeave. After the connection is established, CoreWeave appears as just another compute pool—one that happens to offer access to massive-scale GPU resources.
Outerbounds offers a 14-day free trial, allowing you to evaluate the full end-to-end setup with no commitment.
During the trial, you’ll get hands-on support from AI engineers and infrastructure specialists experienced with both hyperscalers and CoreWeave. They’ll help you stand up a complete Stage IV environment— ready for fine-tuning, inference, or agentic workloads—so you can start building differentiated AI products right away. Get started today!

Start building today
Join our office hours for a live demo! Whether you're curious about Outerbounds or have specific questions - nothing is off limits.
We can't wait to meet you soon! Keep an eye out for a confirmation email with the deets.






