The Difference between Random Forests and Boosted Trees
Random forests and boosted trees are some of the most popular and performant machine learning models. Look no further than the success of packages such as XGBoost and models such as scikit-learn’s RandomForestClassifier.
They are often confused with one another as they are both ensemble methods that use decision trees as their base models. So we wrote this post to dispel any confusion and to provide guidance on when to use them!
Decision Tree Classifiers
Decision tree classifiers are algorithms that make predictions by climbing down a decision tree, such as that pictured below, for each data point, to reach a target value. Each branch is a decision, such as "is feature x > 5?”
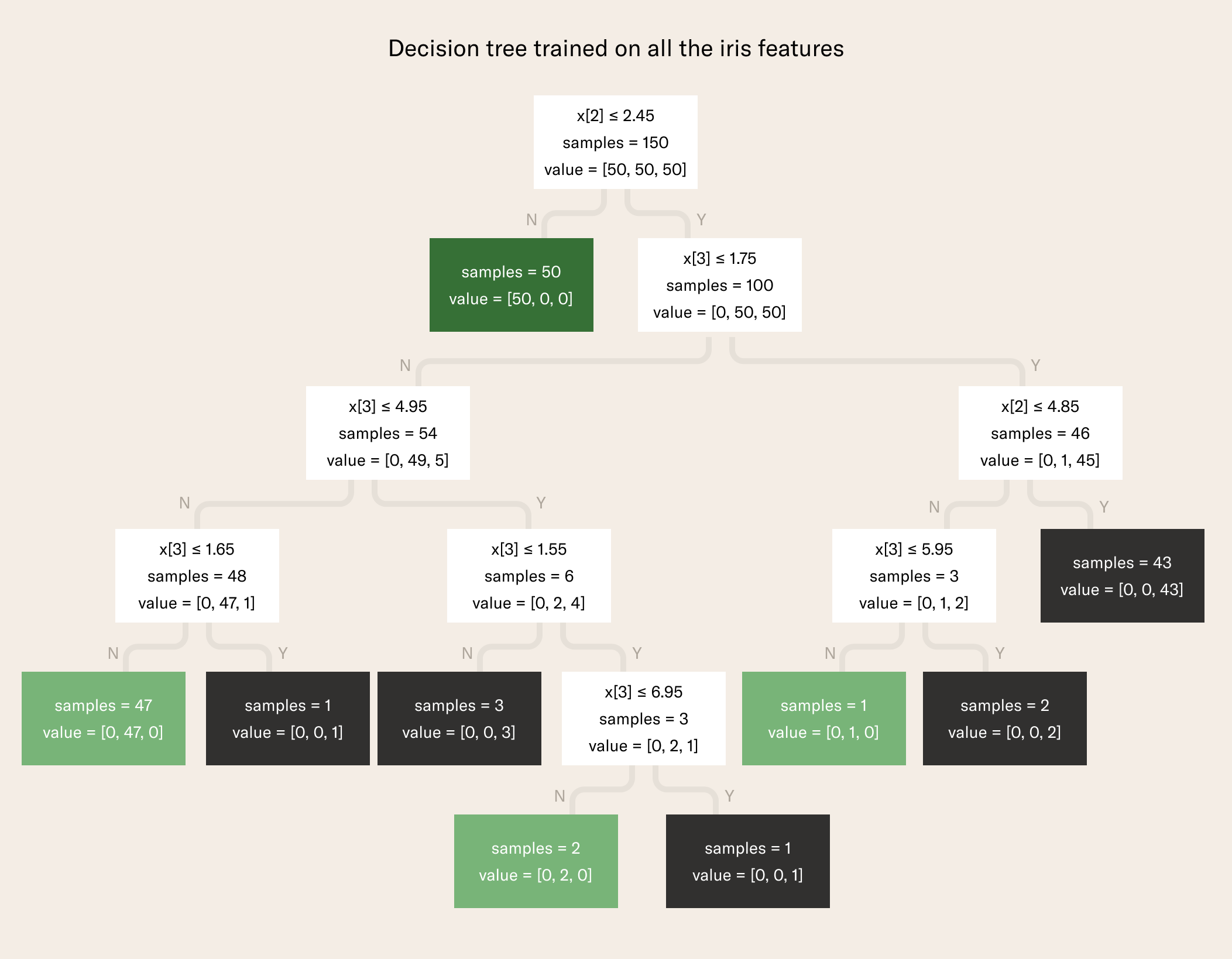
Decision trees have upsides, such as being explainable machine learning algorithms, but are also not particularly accurate and prone to overfitting, as they create linear decision boundaries:
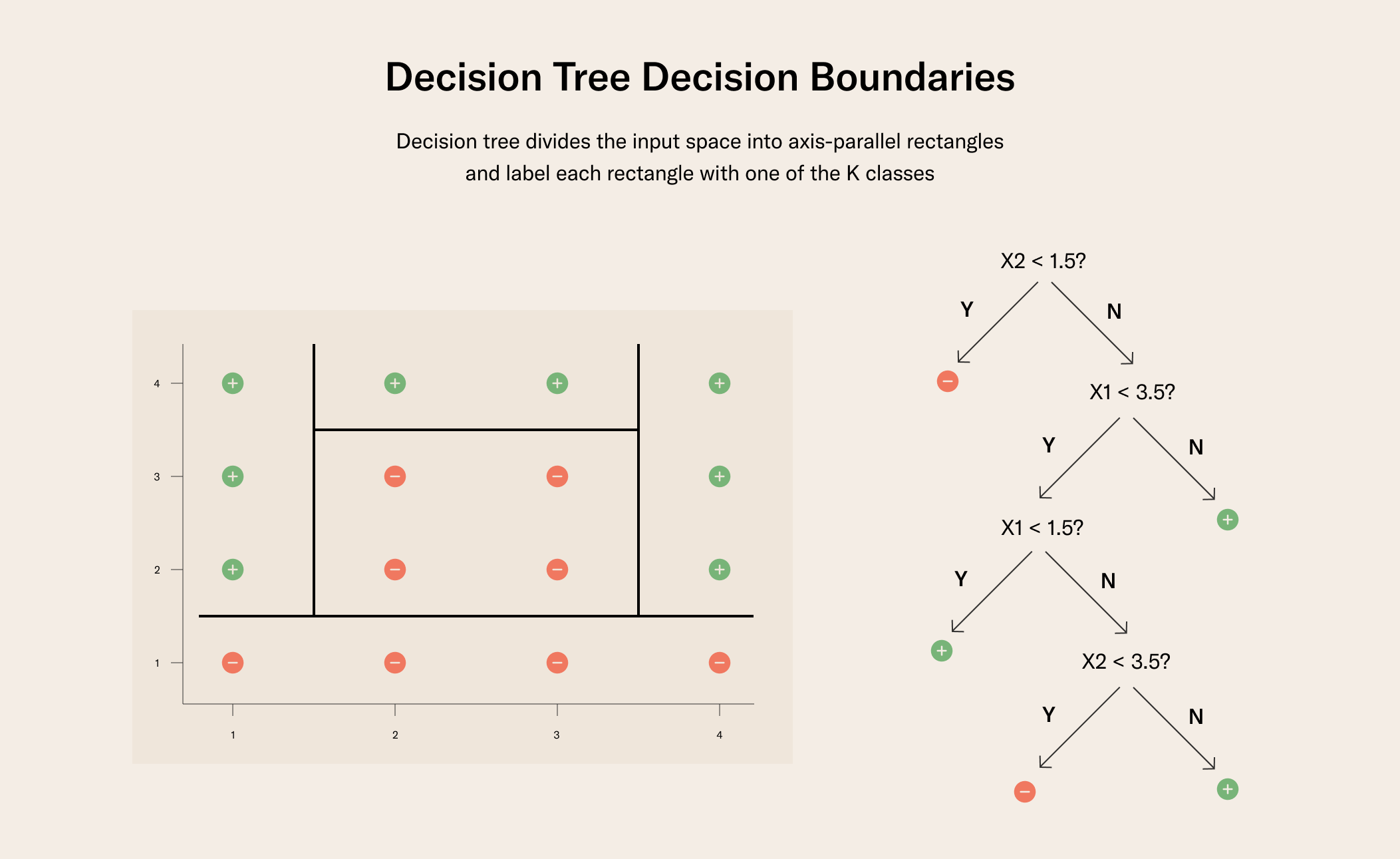
Another way to state this is that decision trees are prone to having high variance (thinking through the bias-variance tradeoff).
One way to reduce overfitting is to use ensemble learning, which uses multiple models together. Both random forests and boosted trees are ensemble methods that use decision trees (the former uses a method called bagging, the latter boosting) so let’s jump in.
Bagging and Random Forests
Bagging is an ensemble method that uses a technique called bootstrap aggregation (hence “bagging”). The basic idea is to take a bunch of subsets of the dataset, train a model on each subset, and then get your models to vote when predicting. Essentially, we’re averaging over all our models – this is the aggregation and the bootstrap is the way we sample our data each time.
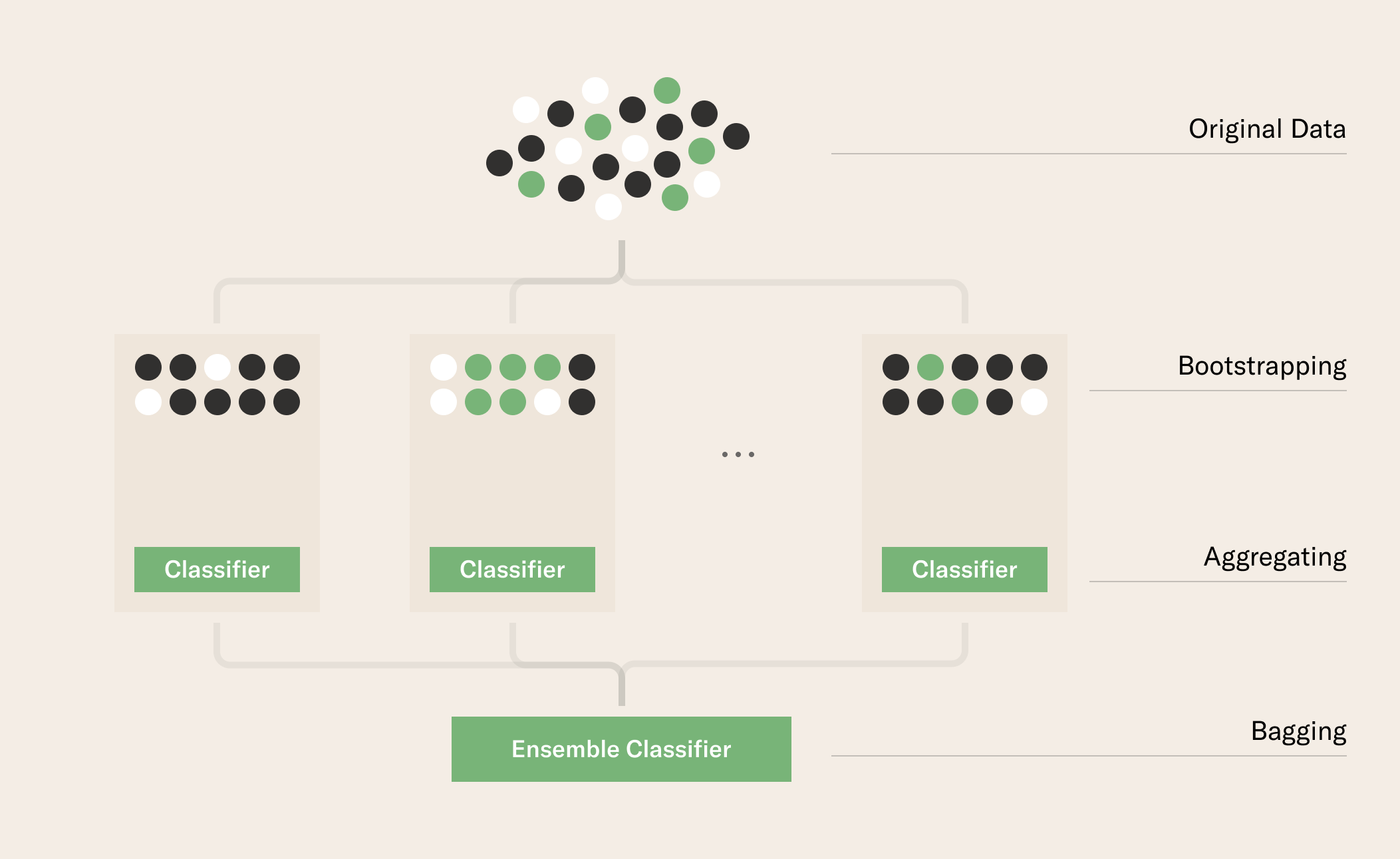
Random forests are essentially bagging over decision trees!
Boosting and Boosted Trees
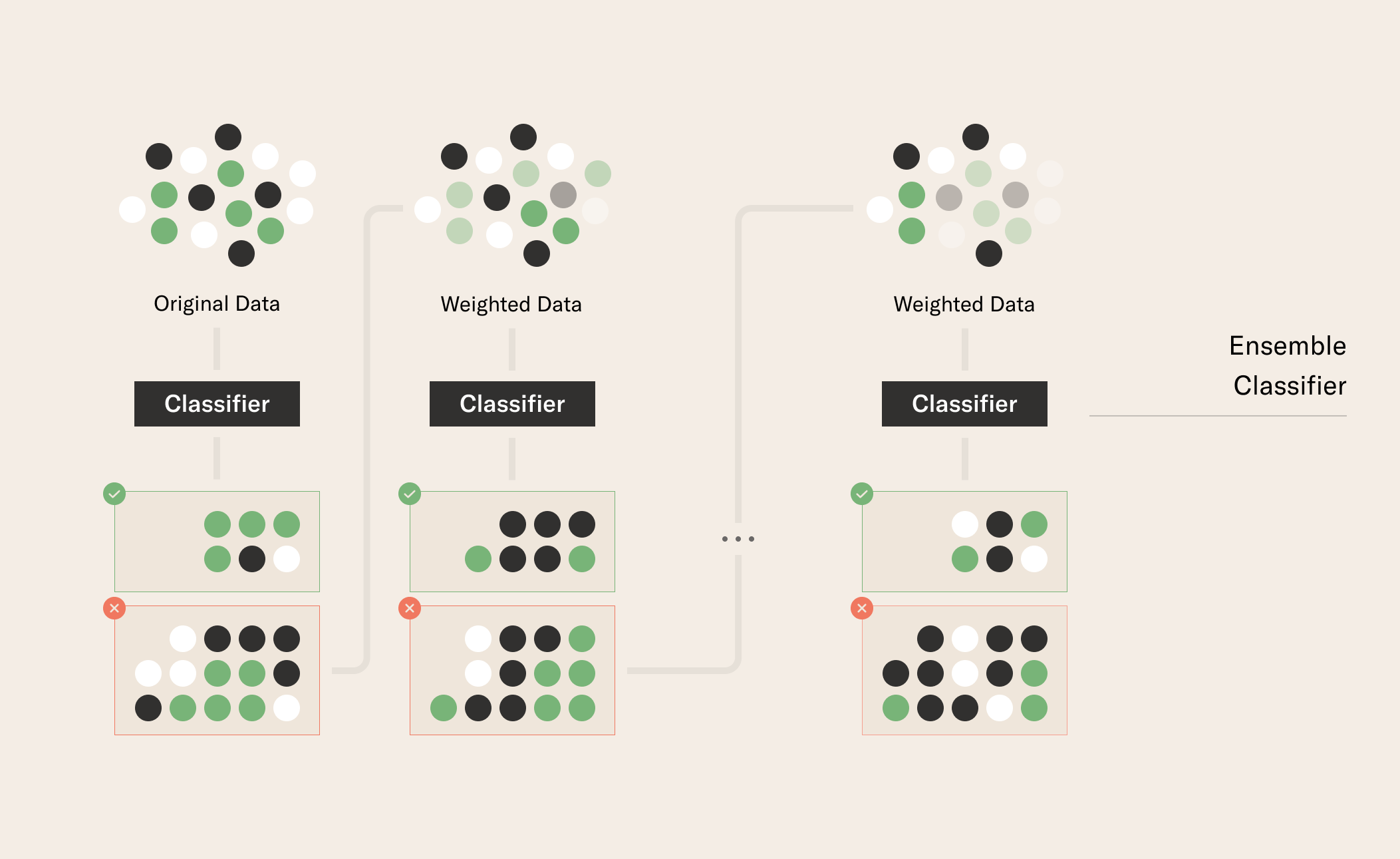
Boosting, like bagging, is an ensemble method, but it works differently:
We start off with one model, commonly referred to as a weak learner (a model weakly correlated with the signal in the data); We make predictions for each data point and assign higher weights to the data points that were classified incorrectly; We build a second model on our data set with re-assigned weights so that it attempts to correct the incorrect predictions; We continue this process: reweighting our data points and building more models to find a strong learner (strongly correlated with the true classification).
When to Use Boosting and When to Use Bagging
There is no free lunch here but we can provide some rules of thumb for thinking through which to use
- When a single model, such as a decision tree, is overfitting, using bagging (such as random forests) can improve performance;
- When a single model has low accuracy, boosting, such as boosted trees, can often improve performance, whereas bagging may not.
- Having provided these rules of thumb, you can also try both in parallel to find out which performs better for you!
In a word,
- With boosting: more trees eventually lead to overfitting;
- With bagging: more trees do not lead to more overfitting.
In practice, boosting seems to work better most of the time as long as you tune and evaluate properly to avoid overfitting. If you want to get started with random forests, you can do so with scikit-learn’s RandomForestEstimator. If you want to get started with boosted trees, check out XGBoost.
How do I?
Use scikit-learn estimators with Metaflow