Loading Tabular Data from Files
You are probably familiar with processing tabular data in a database or a spreadsheet. For instance, Excel loads tabular data from its own proprietary .xls files which are not straightforward to handle outside spreadsheets. When loading data programmatically, say in a Python script, it is more convenient to use text files like TSV (tab-separated values) or CSV (comma-separated values) which look something like this:
Alice,45,Director
Bob,22,Engineer
Charlie,34,Designer
CSV files are nicely human readable and universally supported across systems and libraries. You can load them by using Python’s built-in csv module or read_csv in pandas. However, the CSV format has a number of downsides:
- Newlines and commas and other special characters in value can easily result in corrupted data, unless special care is taken to escape the characters.
- Type information is lost: It is impossible to know reliably if a field is supposed to be an integer, string, a timestamp, or another data type.
- It is slow to load large amounts of data from a CSV file.
A newer file format, Parquet, addresses these shortcomings.
The Parquet Format
The above data could be stored as a Parquet file that looks like this conceptually:
| Name | Age | Title |
|---|---|---|
| String | Int | String |
| Alice | 45 | Director |
| Bob | 22 | Engineer |
| Charlie | 34 | Designer |
There are a few key differences to the CSV format:
- Data is stored by columns, not by rows. It is particularly efficient to load and process data in a columnar fashion: column-by-column vs. row-by-row.
- Each column has a name, type, and other optional metadata, which makes loading the data faster and more robust.
- Data is compressed by default. An upside of this is reduced space requirements and faster processing, a downside is the loss of human-readability - the data is stored in a binary format.
Today, Parquet is widely used by modern data warehouses and databases, like Snowflake or AWS RDS, Athena, or Google BigQuery, as an efficient format for importing, exporting, and processing data. You can load Parquet files either by using read_parquet in pandas or the Arrow library. Note that you may be able to load much larger datasets in memory using Arrow instead of pandas - for more details read Python data structures for tabular data. Over the past years, the tooling for handling Parquet files across languages and libraries has advanced dramatically - thanks to the Apache Arrow project - so Parquet is now a solid choice for loading and storing tabular data in modern data applications.
Local Files vs. Files in the Cloud
Besides the data format, where should you store the data? Business environments shun the idea of storing and sharing data as local files for good reasons: Local files can get lost, it is hard to make sure they follow the company’s data governance policies, and they are slow and inconvenient to move around. In the past, many data-hungry machine learning and data science applications preferred local files for performance reasons. For instance, it could have been 100x faster to train a model using local files versus loading the data from a database on the fly. Thanks to the advances in cloud computing, these days it can be faster to load files from a cloud storage like S3 than loading local files - e.g. Parquet files exported from a data warehouse - as long as the data doesn’t leave the cloud. Achieving the highest performance requires a relatively large cloud server and a sufficiently large dataset, which makes this a great pattern especially for applications handling hundreds of gigabytes of data or more. The situation can be summarized as follows:
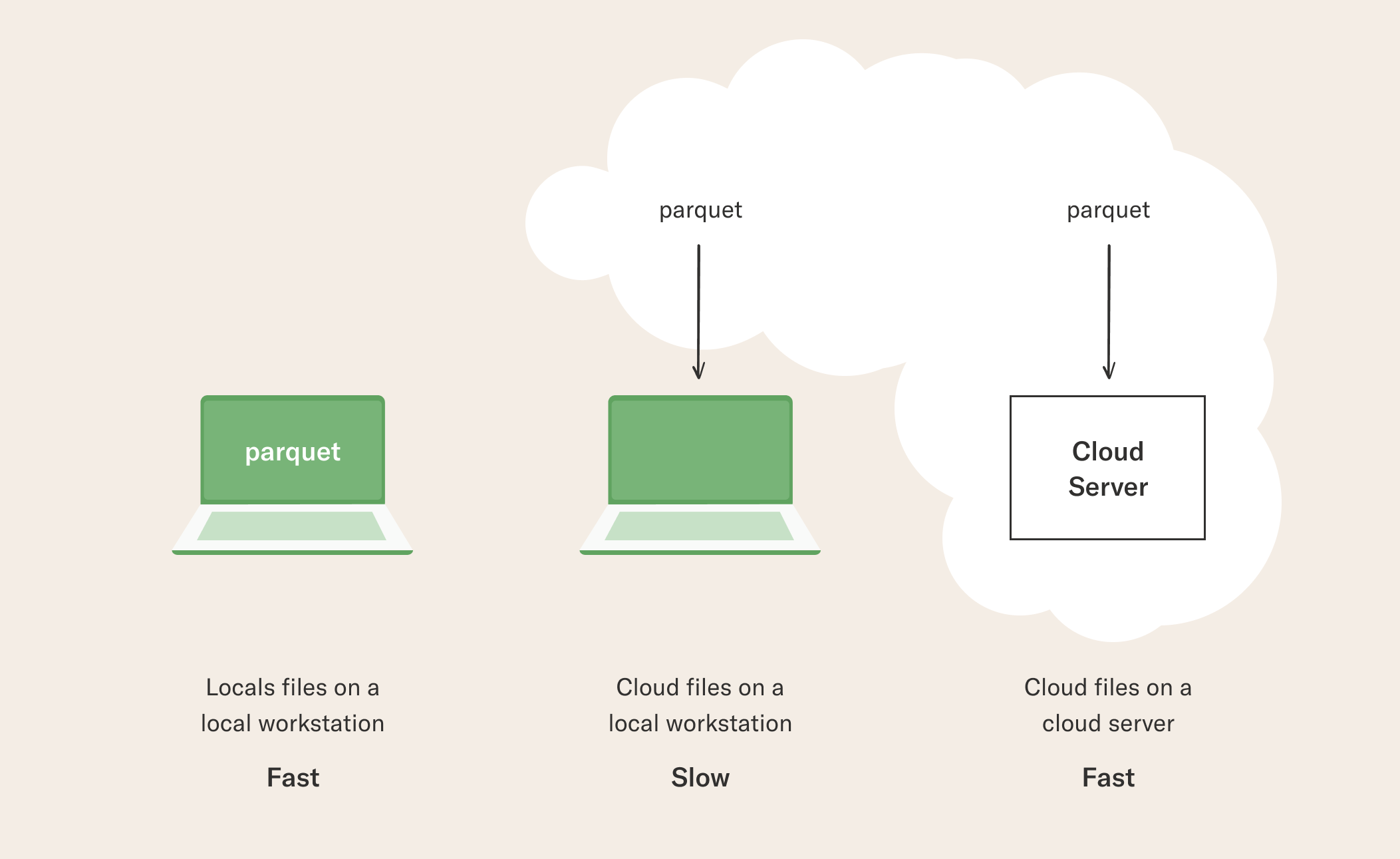
Loading local files on a local workstation like a laptop is certainly fast, but a single workstation is not a particularly scalable solution and local files can be problematic, as discussed above. Loading data from the cloud to a local workstation can be slow, depending on the local network. You can achieve the highest data throughput by using the @batch or @kubernetes decorators in Metaflow with @resources requirements that exceed the size of the dataset or by using a large cloud-based workstation. Metaflow comes with a built-in S3 client, metaflow.S3, which is optimized for high-performance data loading. It shines at loading e.g. Parquet data from S3, as demonstrated in the article about Loading Parquet Data from S3. If your data resides in local files, you can still benefit from cloud computing either by first copying the data to S3 manually using the AWS command line tools or by using the IncludeFile construct in Metaflow which snapshots the data as a Metaflow artifact automatically.
How do I?
Load a Parquet File to pandas Dataframe
Load CSV Data in Metaflow Steps
Include a File in a Metaflow Flow
Work with Tabular Data in Python