Reproducible Machine Learning
Why does reproducibility matter? Quite simply, it is hard to make incremental progress towards a common goal if the solution being built changes its behavior abruptly. In order to build complex applications, such as a recommendation system, we need robust, predictable building blocks which behave predictably regardless of who develops them. This is true for engineering as well as data science, but the problem of reproducibility is amplified in data science applications as they tend to have more sources of unpredictability. It is important to notice that “unpredictable behavior” and reproducibility are not binary labels. Instead of saying that a data science project or a model is reproducible (or not), we can talk about the degree to which it is reproducible and under which conditions. Crucially, some sources of unpredictable behavior are easier to tame than others, so you can make sure every project has at least the basic elements covered, even if it doesn’t lead to perfect reproducibility. The requirements of reproducibility resemble the game of Jenga. In order to reach perfect reproducibility, you need to address every element of the stack. Addressing the bottom elements is harder than the basic elements at the top of the stack, so we can start from the top taking blocks off:
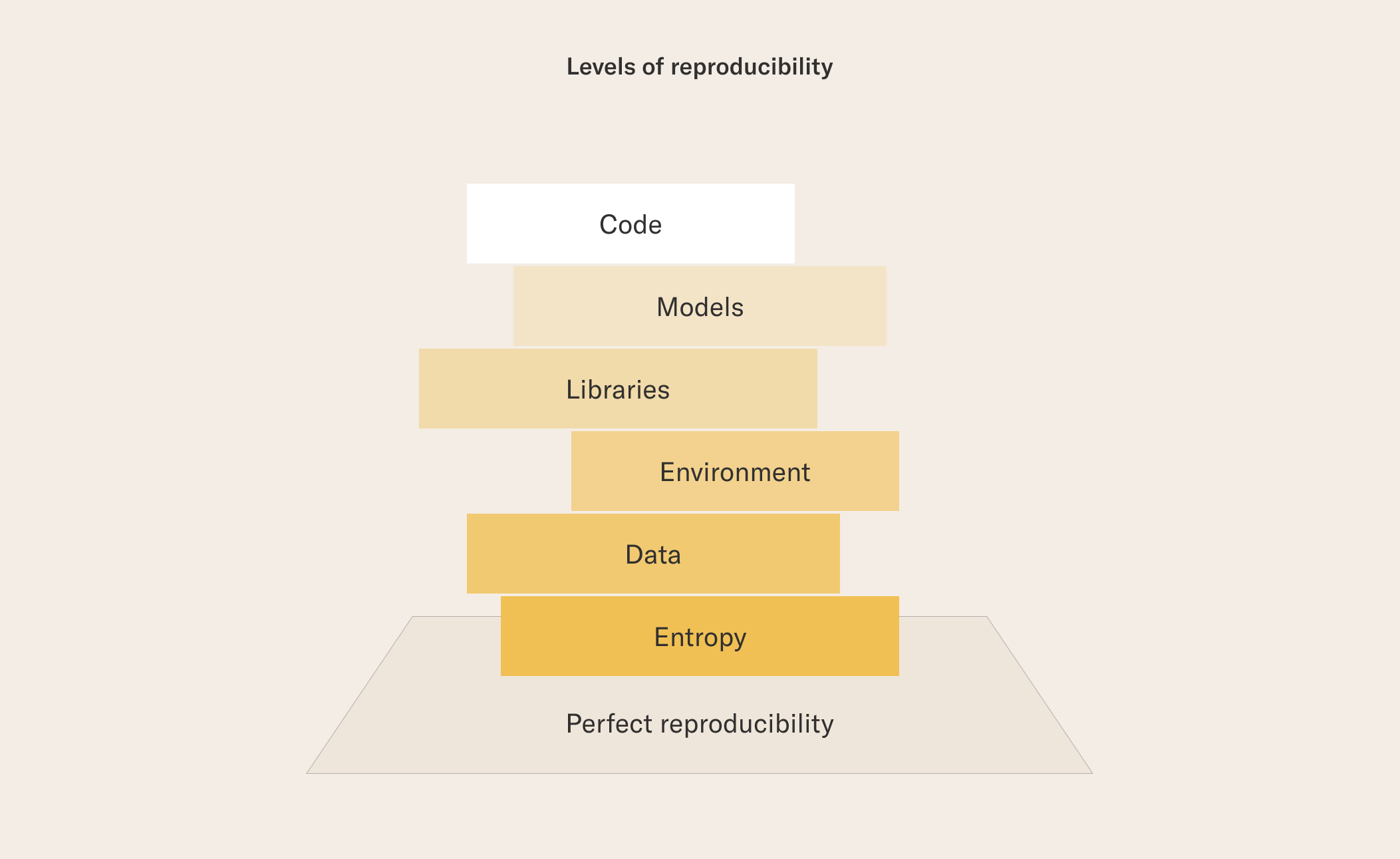
Code
Data science workflows are (Python) code. Obviously, we can’t reproduce the system’s behavior if we don’t know the code that produced the results in the first place. Luckily, there isn’t a big difference between versioning traditional software and versioning data science codes, so we can use widely-used tools like Git to version code. Metaflow snapshots all code executed remotely automatically, so you can know exactly what code powered any past experiment.
Models
Preferably, a model behaves like a mathematical function, y = f(x, p): given input data x and parameters p, we always get the same result y. Theoretically, to make models reproducible, we need to store the model itself, f, which is typically expressed as code, as well as its parameters p which is an array of data. In practice, machine learning models are exposed to various side effects as described below, so just persisting the model structure and its parameters is not sufficient but it is a good starting point.
In the case of Metaflow, you can treat models simply as any other artifacts and let Metaflow worry about versioning and storing them. You can take a step further and try to ensure that the training procedure that produced the parameters p is also reproducible. Doing this requires that you store the hyperparameters that were used to train the model, and also address elements deeper in the stack.
Libraries
Most of the code that powers a data science application is not written by you but it resides in 3rd party libraries, such as PyTorch, Tensorflow, pandas, or scikit-learn. Changing libraries are a common source of abrupt breakage and unpredictable behavior: Even when running on one machine, you might install the same Python packages on the same exact machine on two different days and the results produced are different. Even if you request the same version of a package, the library may have internal dependencies of its own which change over time.
Addressing unpredictable behavior caused by libraries requires that all dependencies are snapshot and frozen, similar to the code you write. How to do this exactly is a deep question of its own. Metaflow’s @conda decorator is one possible solution.
Environment
Frustratingly, even perfectly frozen code and libraries may produce unexpected behavior when executed in a new compute environment: Machine learning processes like model training often require special hardware accelerators like GPUs with complex device drivers which evolve over time. Having common, shared, reliable infrastructure (e.g. @batch or @kubernetes compute environments) helps to contain and control changes in the environment.
When using a solid data science infrastructure like the one enabled by Metaflow, achieving this level of reproducibility and reliability is quite achievable at least for the most critical applications.
Data
If you want to reproduce a specific past prediction y using our model y = f(x, p), you need to use the exact input data x as well. Also to retrain the exact same model, you need the exact snapshot of a past data. In the case of data science, data often goes through a series of feature transformations which may happen in an outside system, e.g. in an extract, transform, and load pipeline. Hence managing change carefully in all the systems that touch data is critical but it is not easy. Many companies find partial solutions that satisfy the needs of most critical applications which allows them to achieve partial reproducibility without a thoroughly versioned data warehouse.
Entropy
Finally, even after perfectly freezing code, models, environments, and data, you may find out that results differ. Many machine learning and data science algorithms have deliberately stochastic, random attributes, which yield different results every time the code is executed. Or, there may be attributes that depend, say, on the time of day. To achieve perfect reproducibility, you must fix random seeds, clocks, and other sources of entropy across all code, libraries, and environments, which can be a daunting task.
Luckily, very few applications require absolutely perfect reproducibility. If you need this, your best bet is to stick with the simplest possible models, code, and libraries which can be audited thoroughly.
How do I?
Set environment variables with Metaflow decorator