The Full Stack for Data Science
How should one go about building a modern application powered by machine learning and data science? It is not easy to give a prescriptive answer given the vast diversity of techniques and use cases involved. However, there are common, foundational components without which developing and operating a production-ready data science application would be difficult.
We can put these components together in a stack that looks like this:
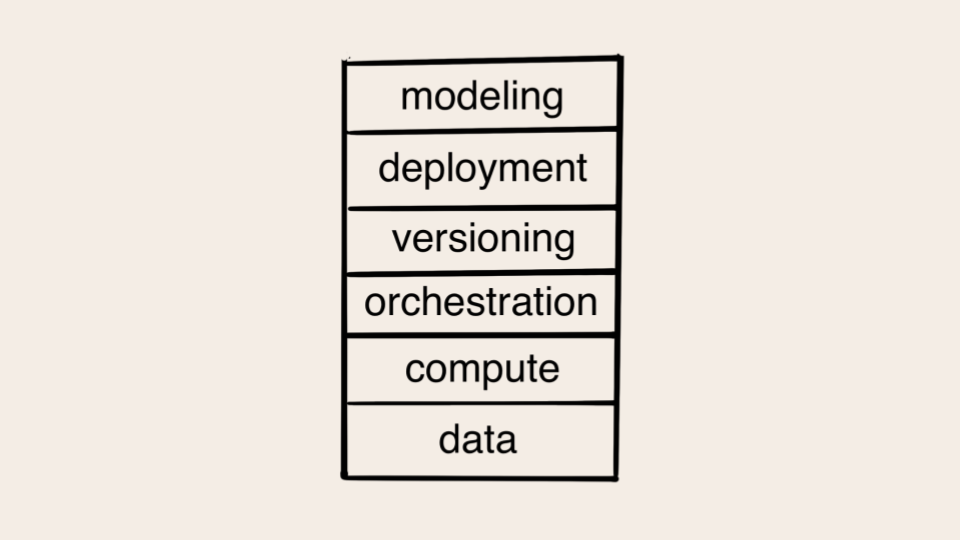
The stack is organized so that the most foundational components, data and compute, are at the bottom and higher-level concerns at the top. Most production-quality applications need a solution for every layer of the stack, the implementation of which vary depending on the application and the business environment.
Consider the stack a core mental model which helps you build and operate data-intensive applications. Each layer comes with questions and considerations of its own, which is why we have organized articles on this site after the stack, as shown on the left navigation bar.
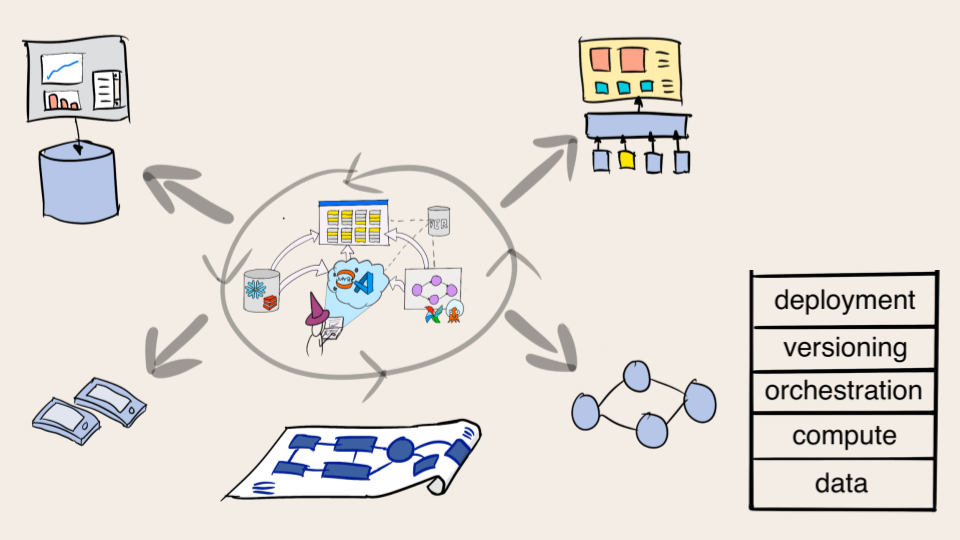
You may wonder: Why this stack and not another one? You could label the layers differently and find another way to arrange them but the activities behind them are fundamental and rather unavoidable, as illustrated below.
What’s behind the stack?
We want to empower a data scientist to develop applications - not just models - independently. Compare this to a modern full-stack engineer who is able to develop full-fledged websites on their own, thanks to the modern web stack.

A definining feature of data science applications is that they need data. The data may be tabular, stored in a data warehouse, or unstructured data like text or images. In any case, the question of data discovery and data access needs to be addressed.
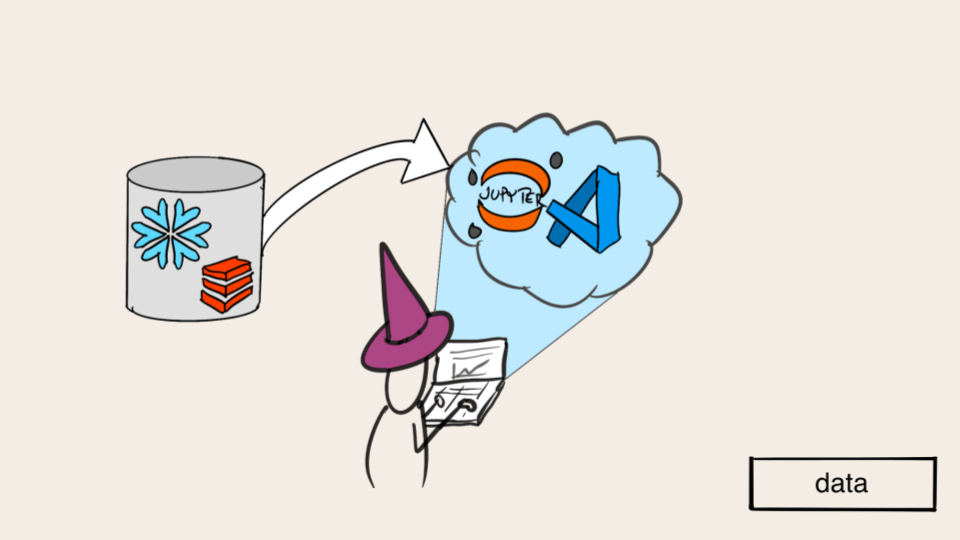
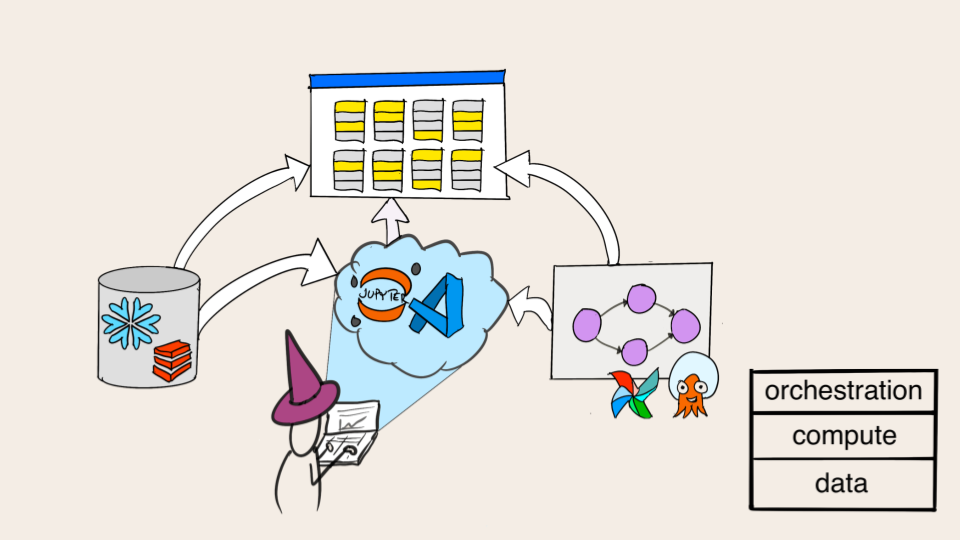
Another defining feature of data science is that it involves processing data or computation. Machine learning in particular is a compute-heavy activity, so being able to provision enough compute capacity is crucial. Even if your data is small and models lightweight, you can benefit from parallelized computation to speed up exploration and experimentation.

A data science application consists of multiple units of computation which can be organized as a workflow. Whereas the compute layer provides raw horsepower for executing functions, it is the job of a workflow orchestrator to ensure that the workflow gets executed reliably, on schedule, without any human intervention.
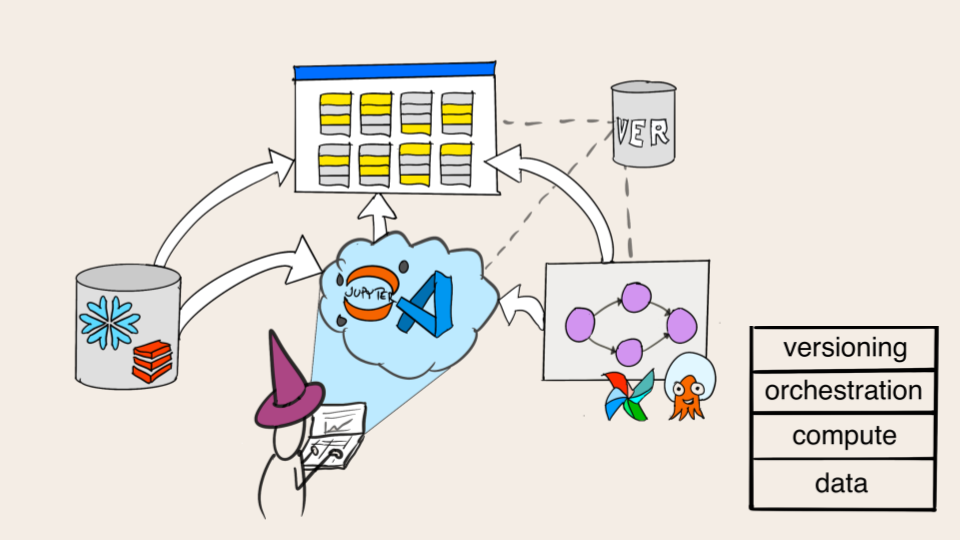
The development of a workflow happens through many iterations. Multiple variants of the project may be tested concurrently, developed by a team of data scientists working simultaneously. Tracking and organizing the work requires a robust versioning layer that makes sure that variants don't interfere with each other and experiments can be tracked and analyzed consistently.
To produce real business value, workflows must be connected to surrounding business systems and set up to run reliably without human intervention, that is, they must be deployed to production. There isn't a single way to deploy machine learning to production. Instead, different applications necessitate different deployment patterns.
Once all these layers are in place, one can start optimizing the quality and performance of models. The infrastructure stack can be shared by a diverse set of applications and models, from basic regression to sophisticated deep learning. They all benefit from the layers below.
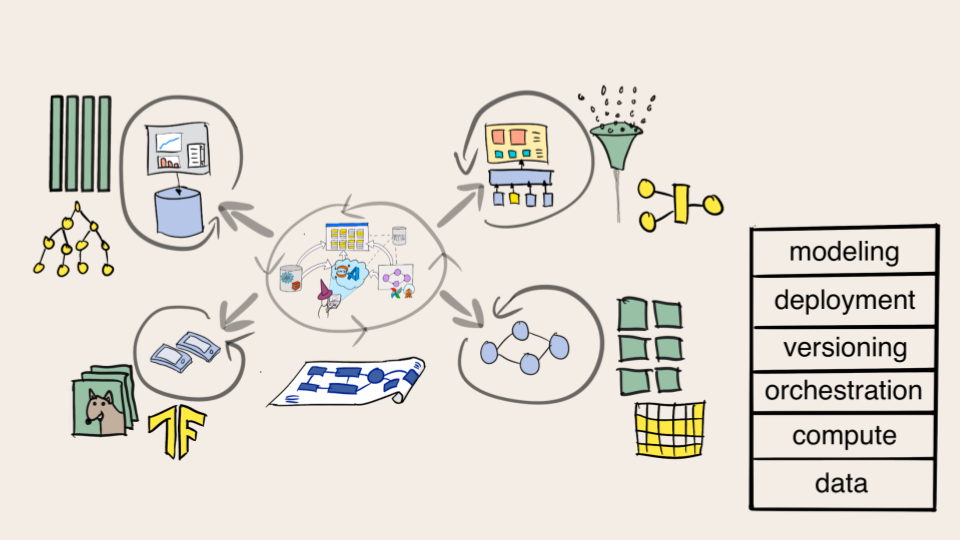
Using the stack
You can start building applications with the stack today! Making this happen requires collaboration between engineers and data scientists: The engineers need to set up the data, compute, and orchestration layers. Fear not: Our documentation for engineering includes customizable blueprints that help you get started.
Once the foundational layers are in place, Metaflow wraps them in a human-friendly API, allowing data scientists to build applications without having to get their hands dirty with the infrastructure. Metaflow comes with a built-in versioning layer, as well as patterns for robust deployments, which empower data scientists to prototype and productionize applications independently.
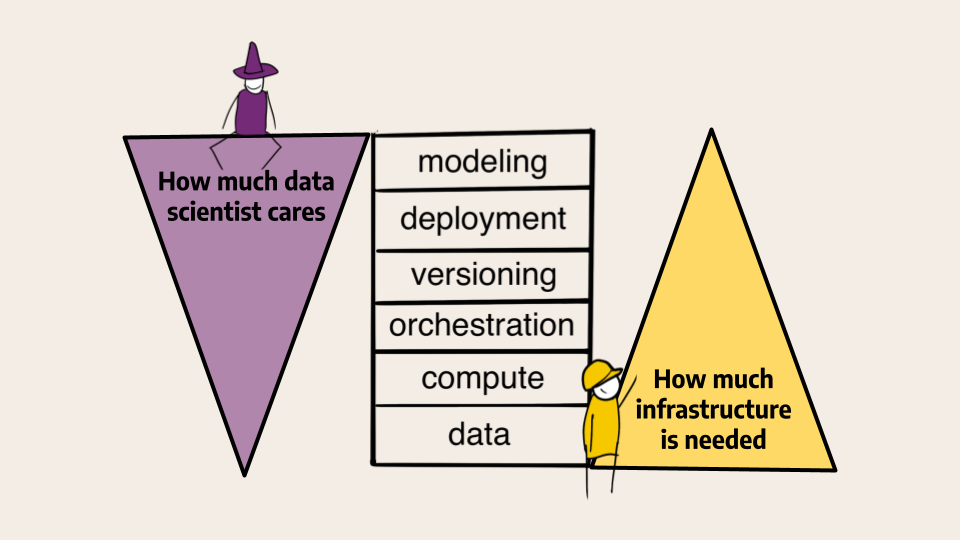
While the stack provides a robust scaffolding for applications, it doesn't build them by itself. It is still up to you, the data scientist, to understand business requirements, data, modeling constraints, and patterns of deployments. This can feel like a daunting job!
Over many years, we have helped hundreds of data scientists and engineers on our Slack who have asked a myriad of questions, some mundane and some very advanced, touching all layers of the stack. We are collecting these questions with answers on this site, so they can benefit you during your journey.
If you need help with anything related to the stack and you can't find an answer quickly here, join our Slack for support!
See Also
Test the stack live with a Metaflow Sandbox
Video: The Modern Stack for ML Infrastructure
Book: Effective Data Science Infrastructure