

This blog post is a collaboration between Coveo, a long-term Metaflow user, and Outerbounds. At Outerbounds, we’ve collaborated with Coveo several times, on such projects as Metaflow cards and a recent fireside chat about Reasonable Scale Machine Learning — You’re not Google and it’s totally OK. For this post, we sat down with Jacopo from Coveo to think through how they use Metaflow to connect DataOps with MLOps to answer the question: once data is properly transformed, how is it consumed downstream to produce business value?
TL;DR
- After the adoption of the modern data stack (MDS), organizations are still early in the journey to become “data-driven” and the MDS needs to be coupled with MLOps and actual data-powered software to succeed;
- You’ll learn about the challenges of working with data in a fast-paced, growing organization and how to overcome them, including scalable end-to-end code showing how DataOps and MLOps can join forces with state-of-the-art tooling, such as Metaflow and dbt;
- A key point in the solution is the abstraction level operated at: from data to serving, the entire pipeline does not need any special DevOps person, infrastructure work, or yaml files. SQL and Python are the only languages in the repository.
- In a follow up post, we’ll show how good tools provide a better way to think about the division of work and productivity, thus providing an organizational template for managers and data leaders.
From the Modern Data Stack to MLOps
The modern data stack (MDS) has been consolidated as a series of best practices around data collection, storage and transformation. In particular, the MDS encompasses three pillars:
- A scalable ingestion mechanism, either through tools (e.g. Fivetran, Airbyte) or infrastructure;
- A data warehouse (e.g. Snowflake) storing all data sources together;
- A transformation tool (e.g. dbt), ensuring versioned, DAG-like operations over raw data using SQL.
A lot has been said already about the MDS as such, but the situation is more “scattered” on the other side of the fence: once data is properly transformed, how is that consumed downstream to produce business value? At the end of the day, ingesting and transforming data is not (for most companies) an end in itself: while tech giants figured out a while ago how to “get models in production”, most companies still struggle to productionize a model in less than 3 months.
Our solution is to accept the fact that not every company requires elaborate and infinitely scalable infrastructure like those deployed by Googles and Metas of the world, and that is totally ok: doing ML at “reasonable scale” is more rewarding and effective than ever, thanks to a great ecosystem of vendors and open source solutions. In the companion repository, we demystify deep learning pipelines by training a model for sequential recommendations: if you see a shopper interacting with k products, what is she going to do next? We
- purposefully avoid toy datasets and local-only deployments;
- provide a cloud-ready, “reasonable scale” project;
- show how training, testing, and serving (the MLOps steps) are naturally embedded in a pipeline that starts with data and features (the DataOps steps).
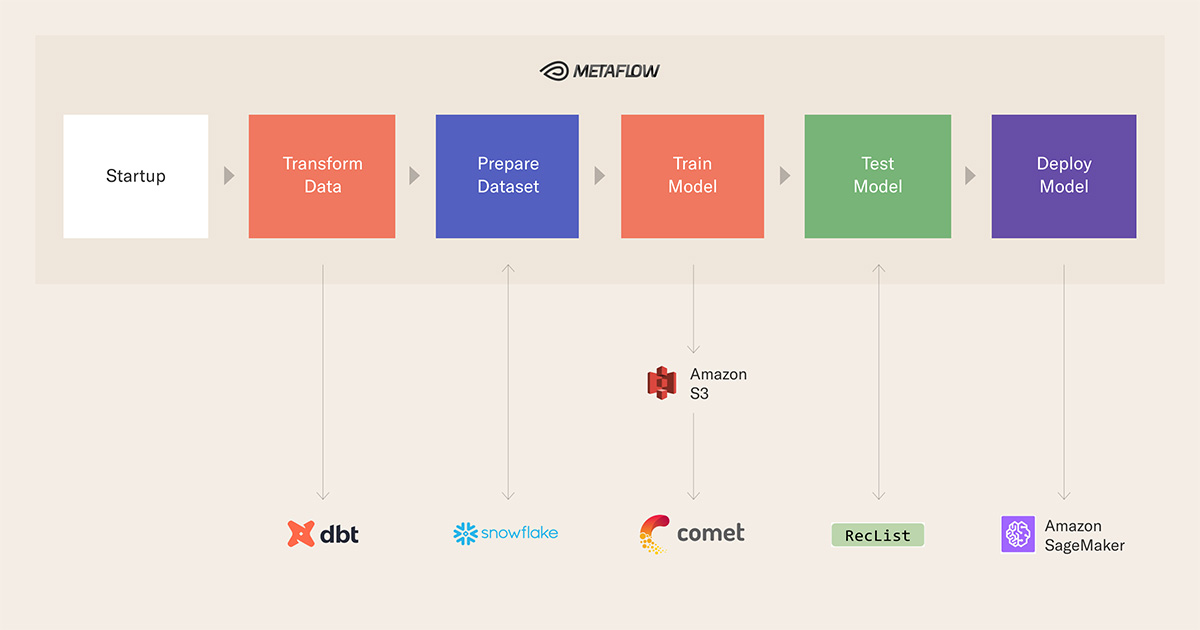
The backbone for this work is provided by Metaflow, our open-source framework which (among other things) lowers the barrier to entry for data scientists to take machine learning from prototype to production and the general stack looks like this, although Metaflow will allow you to switch in and out any other component parts:
 In this and a follow-up post, we tell the story of how tools and culture changed together during our tenure at a fast-growing company, Coveo, and share an open-source repository embodying in working code our principles for data collaboration: in our experience, DataOps and MLOps are better done under the same principles, instead of “handing over” artifacts to the team on the other side of the fence. In particular, our goal is twofold:
In this and a follow-up post, we tell the story of how tools and culture changed together during our tenure at a fast-growing company, Coveo, and share an open-source repository embodying in working code our principles for data collaboration: in our experience, DataOps and MLOps are better done under the same principles, instead of “handing over” artifacts to the team on the other side of the fence. In particular, our goal is twofold:
- Based on our experience, we provide a technical template for teams starting up, and wondering how to join DataOps and MLOps efficiently;
- We show how good tools provide a better way to think about the division of work and productivity, thus providing an organizational template for managers and data leaders. We’ll do this in a follow-up post.
All in all, while we are excited by the growth in the space, we also know that the number of options out there can be intimidating and that the field is still chaotic and quickly evolving. Our solution is a practical stack that both provides a reliable first step for teams testing the MLOps waters and shows in detail how simple pieces go a long way towards building ML systems that scale.
You can find a video tutorial on the repository guiding this post here:
Leveraging the Modern Data Stack for Machine Learning
How does this stack translate good data culture into working software at scale? A useful way to isolate (and reduce) complexity is by understanding where computation happens. In our pipeline, we have four computing steps, and two providers:
- Data is stored and transformed in Snowflake, which provides the underlying compute for SQL, including data transformations managed by a tool like dbt;
- Training happens on AWS Batch, leveraging the abstractions provided by Metaflow;
- Serving is on SageMaker, leveraging the PaaS offering by AWS;
- Scheduling is on AWS Step Functions, leveraging once again Metaflow (not shown in the repo, but straightforward to achieve).
A crucial point in our design is the abstraction level we chose to operate at: the entire pipeline does not need any special DevOps person, infrastructure work, or yaml files. SQL and Python are the only languages in the repository: infrastructure is either invisible (as in, Snowflake runs our dbt queries transparently) or declarative (for example, you specify the type of computation you need, such as GPUs, and Metaflow makes it happen).
While the DataOps part may be familiar to you, it is worth giving a high-level overview of the MLOps part. Remember: transforming and normalizing data is rarely an end in itself – data is valuable only insofar as you get something out of it, insights from visualization or predictions from machine learning models.
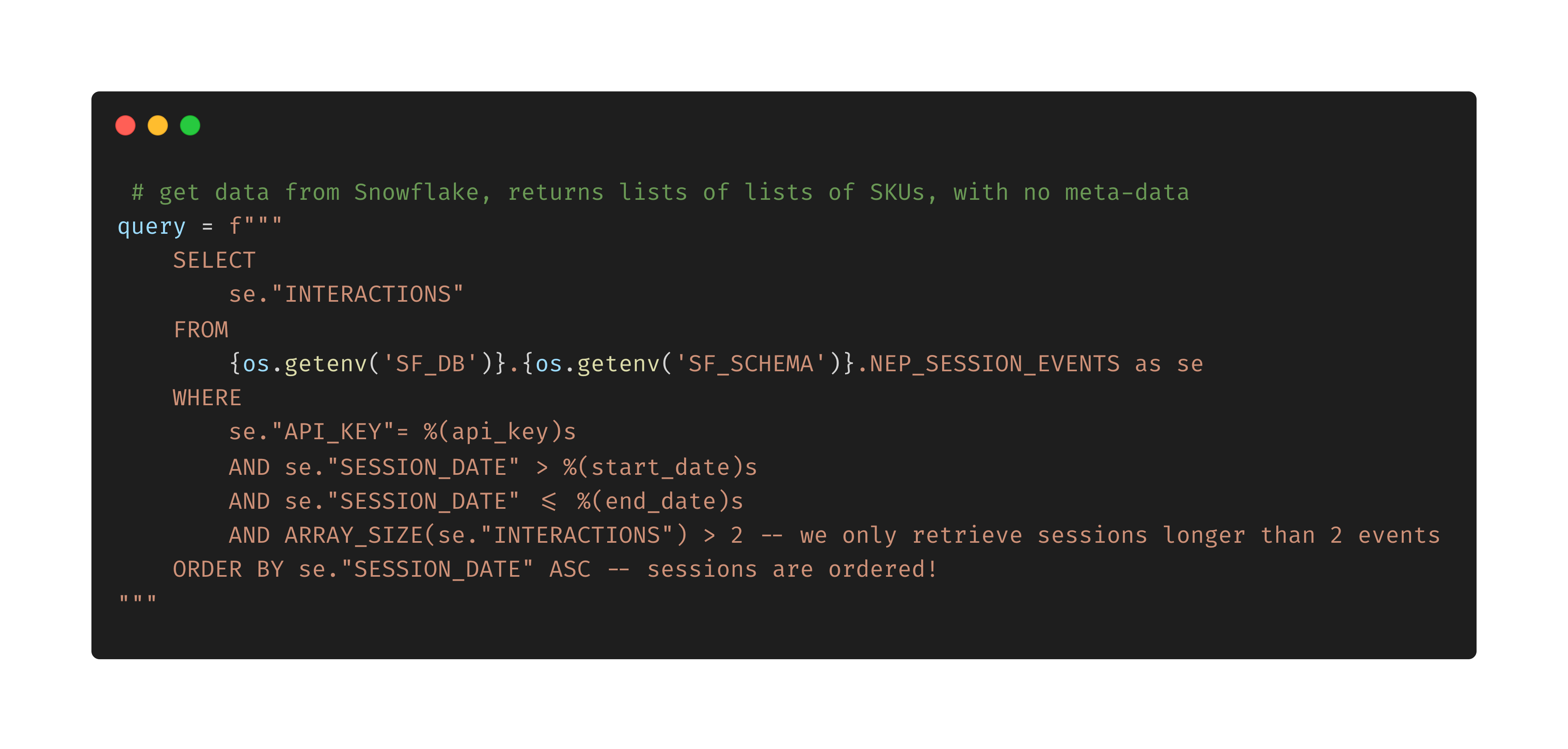
Our stack leverages a SQL DAG – as built by dbt – to run the necessary transformation from raw shopping events to sequences of product interactions for our recommendation model: by using SQL we accomplish two important goals:
- first, the ML team can work directly off-the-work of analytics engineer in a unified environment (SQL is the lingua franca of data, so to speak);
- second, we push down to Snowflake all the (distributed) computing, making the Python side of things pretty lightweight, as we are not really bound by machine memory to aggregate and filter data rows.
The training part itself is a vanilla deep model for session recs and nothing hinges on its details: the same principles would apply to more complex models. The exciting part is that a simple SQL query, easy to read and maintain, is all that is needed to connect feature preparation and deep learning training on a GPU in the cloud. Training a model produces an artifact (that is, a ready-to-use model!), which can now generate predictions: as it’s good practice to test the model on unseen data before deploying it on real traffic, we showcase in test_model a draft of an advanced technique, behavioral testing.
Finally, our pipeline ends with deployment, that is, the process of shipping the artifact produced by training and validated by testing to a public endpoint that can be reached like any other API; by supplying a shopping session, the endpoint will respond with the most likely continuation, according to the model we trained.
This is a comfortable stack for the data scientist, seasoned ML engineer, the analytics engineer who is just getting started with Python, and even the PM monitoring the project: collaboration and principled division of labor is encouraged. While we present a RecSys use case, most if not all of the above considerations apply to analogous pipelines in many other industries: you do not need a bigger boat, after all, to do cutting-edge ML.
This stack can also be run in increasingly complex configurations, depending on how many tools / functionalities you want to include: even at “full complexity” it is a remarkably simple and “hands-off” stack for terabytes-scale processing; also, everything is fairly decoupled, so if you wish to swap SageMaker with Seldon, or Comet with Weights & Biases you will be able to do it in a breeze.
The full stack contains ready-made connections to an experiment tracking platform and a (stub of a) custom DAG card showing how the recommender system is performing according to RecList, Jacopo’s team’s open-source framework for behavioral testing. We could write an article just on this (well, we actually did write it, plus two scholarly papers): even as a very small testing routine, we wanted to make sure to include it as a general reminder of how important is to understand model behavior before deployment, and how readable, shareable, low-touch documentation is crucial for ML pipelines in production.
This stack is simple, yet effective and modular: it may not be the end of the journey, but it surely makes a very good start.
In a follow-up post, we’ll show how good tools provide a better way to think about the division of work and productivity, thus providing an organizational template for managers and data leaders. If these topics are of interest, come chat with us on our community slack here.
Acknowledgments
Special thanks: Sung Won Chung from dbt Labs, Patrick John Chia, Luca Bigon, Andrea Polonioli and Ciro Greco from Coveo. None of this would have been possible without the fantastic dataset released by Coveo last year, containing millions of real-world anonymized shopping events.
If you liked this article, please take a second to support our open source initiatives by adding a star to our RecList package, this repo, and Metaflow.